




 本文介绍了SQL数据定义语言(DDL)的基本概念,包括关系模式、属性取值范围、完整性约束等,并详细阐述了SQL查询的基本结构及各种子句的使用方法。
本文介绍了SQL数据定义语言(DDL)的基本概念,包括关系模式、属性取值范围、完整性约束等,并详细阐述了SQL查询的基本结构及各种子句的使用方法。
SQL数据定义
SQL数据定义语言(DDL)可以定义每个关系的信息
- 关系模式
- 属性取值范围、属性域
- 完整性约束(主外码)
- 关系的安全性和权限信息
- 其他信息
- 关系维护的索引集合
- 关系在磁盘上的物理存储结构
基本类型
| 声明 | 意义 |
|---|---|
| char(n) | 固定长度的字符串,用户指定长度n |
| varchar(n) | 可变长度字符串,用户指定最大长度n |
| int | 整数类型 (4字节) |
| smallint | 小整数类型 (2字节) |
| numeric(p,d) | 定点数,精度由用户指定。这个数有p位数字,其中,d位数字在小数点右边 |
| real, double precision | 浮点数与双精度浮点数,精度与机器相关 |
| float(n) | 精度至少为n位的浮点数 |
定义
create table命令定义SQL关系
create table r(
A1,D1,
...,
An,Dn,
<完整性约束1>,
<完整性约束2>);
r是关系名,AiA_iAi是关系rrr模式中一个属性名,DiD_iDi是属性AiA_iAi的域(取值类型、范围)
create table instructor (
ID char(5) ,
name varchar(20) ,
dept_name varchar(20) ,
salary numeric(8,2),
primary key (ID));
完整性约束
- not null
- primary key(A1,...,An)(A_1,...,A_n)(A1,...,An)
- foreign key(Am,...,An)(A_m,...,A_n)(Am,...,An)
如
create table instructor (
ID char(5),
name varchar(20) not null,
dept_name varchar(20),
salary numeric(8, 2),
primary key (ID),
foreign key (dept_name) references department );
PS:primary key声明属性自动为not null
更多的例子
create table student (
ID varchar(5),
name varchar(20) not null,
dept_name varchar(20),
tot_cred numeric(3,0),
primary key (ID),
foreign key (dept_name) references department);
SQL进制破坏完整性约束的数据库更新,如
- 新插入元组主码attribute为null,或取值与零一关系中的另一 tuple主码属性相同
- 新插入的student的tuple所在dept_name未出现在department关系中,破坏外码约束
create table course (
course_id varchar(8) primary key,
title varchar(50),
dept_name varchar(20),
credits numeric(2,0),
foreign key (dept_name) references department);
主键定义可以和属性声明相结合
修改、删除表
drop table student
删除表和其中内容
delete from student
删除表里的内容,但是保留表(关系模式)
alter table 增加、删除属性
alter table r add A D
• 其中 A 是要被添加到关系 r 的属性的名称,并且 D 是 A 的域。
• 关系中所有元组使用 null 作为新的属性值。
alter table r drop A
• 其中,A 是关系 r 的属性的名称
• 许多数据库都不支持删除属性,但支持drop整个表
查询基本结构
select A_1, A_2, ..., A_n from r_1, r_2, ..., r_m
where P_1 and (or, not) P_n;
AiA_iAi表示属性,rir_iri关系实例,PiP_iPi谓词-限定条件
一个sql语句结果是一个关系
末尾需要有分号
select子句
选择列出需要的属性,对应投影操作Π\PiΠ
select name from instructor;
sql语句不区分大小写
name == Name == NAME
SQL查询结果和关系中默认允许重复
消除重复使用distinct
找出所有老师所在系名、无重复名字
select distinct dept_name from instructor;
用all则指定不消除重复
select all dept_name from instructor
所有属性*
select * from instructor
可包含算术表达式,可以有+,-,*,/运算符对常量和属性的操作
select ID, name, salary/12 from instructor;
select还可以包含其他特殊数据类型如日期,算术函数
where 和 from
Ø where子句表示结果必须满足的限定条件
Ø 对应关系代数的选择操作(元组的选择)
select name from instructor where dept_name = 'comp.Sci.' and salary > 80000
可以用比较运算符>,<,>=,<=,=,<>比较字符串,算术表达式和日期
Ø from分句列出了查询中用到的关系
Ø 对应关系代数中笛卡尔积操作
select * from instructor, teaches;
生成每一个可能的instructor-teaches对
存在相同属性需要在子句做区分,如instructor.ID
连接
select name, course_id from instructor, teaches
where instructor.ID = teaches.ID; (限制条件)
一个SQL查询的含义可以理解如下:
- 为from子句中列出的关系产生笛卡尔积
- 在步骤1的结果上应用where子句中指定的谓词
- 对于步骤2结果中的每个元组,输出select子句中指定的属性(或表达式的结果
注意:这个不是SQL查询语句执行顺序,实际上是查询优化过的
省略where 则谓词P为ture
与关系代数表达式不同,sql查询结果可出现重复元组
自然连接
自然连接会匹配两个关系中所有共同属性的相同值的元组, 去掉重复属性列
Ø 自然连接结果=共同属性+第一个关系属性+第二个关系属性

注意:小心两两无关的属性重名

当模式设计对联接表的列采用了相同的命名样式时,就可以使用 USING 语法来简化 ON 语法,格式为:USING(column_name)。
附加的基本运算
更名操作
oldName as newName
距离
select id,name,salary/12 as monthly_salary from instructor
select distinct T.name
from instructor as T, instructor as S
where T.salary > S.salary and S.dept_name = 'Comp. Sci.'
此处as可以省去(ORacle必须省)
上文的T,S称为
- 相关名词
- 表别名
- 相关变量
- 元组变量
字符串运算
- 百分号%匹配任意字符串
- 下划线_匹配任意一个字符
- sql用单引号,关系代数字符串用双引号
- 匹配模式大小写敏感,但有些数据库不区分大小写
例子
- ‘intro%’ 以intro为开头的字符串
- ‘%a%’ 任意包含a子串的字符串
- ‘—’只有三个字符的字符串
- ‘—%’ 至少三个
select name from instructor where name like '%dar%'
特殊字符需要转意,准确搜寻%在字符串中要写%
sql额外字符串操作
串联 — ||
大小写 lower(), upper()
长度length()
字串substr
次序
order by
select distinct name from instructor order by name desc;
desc降序,asc升序,默认升序
可以每个属性都设置asc和desc
between
select name from insturctor where salary between 9000 and 10000
也可以用元组运算
where (instructor.ID, dept_name) = (teaches.ID, biology)
集合运算
union 并
intersect 交
except, 减
上面三个操作自动消除冗余
要保留冗余要使用
union all
intersect all
excpet all

空值
null表示
未知值或不存在
任何涉及null算术表达式为null
5+null返回null
用null谓词检测空(is null, is not null)
select name from instructor where salary is null
涉及null的比较运算返回unknown
null<null返回unknown
三值逻辑

空值相同 比较 “=”
如果元组在所有属性上取值相等,那么它们就被当作是相同元组,即使某些值为空
例如:{(‘A’, null), (‘A’, null)}
在去除重复元组时,只包留上述元组的一个拷贝
But,(‘A’, null) = (‘A’, null) 逻辑判断结果为unknown
NOTES:distinct子句和谓词中对待空值方式不同
聚集函数
以值的一个集合(集或多重集)为输入、返回单个值的函数
- ave
- min
- max
- sum
- count
找出course 关系中的元组数
select count(*) from course;
分组聚集 group by
select dept_name, ave(salary) from instructor group by dept_name;
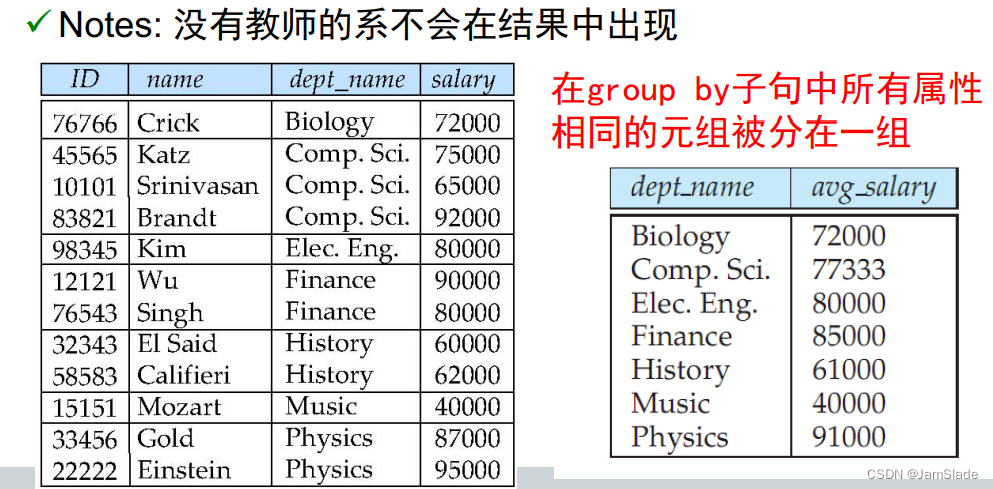
规定
出现在select语句但没有被聚集的属性只能是出现在group by子句的属性
也就是说,select子句中出现、但没有在group by子句中的属性,只能出现在聚集函数的内部
比如select C from A group by B
B和A中都没有C该语句无意义
having
having: 分组限定条件
在分组的情况下再限定
where: 元组限定条件
找出所有教师平均工资超过42000美元的系的名字与平均工资
select dept_name, avg(salary) from instructor group by dept_name having avg(salary) > 42000
having在行成分组后才起作用,可使用聚集函数。任何出现在having子句中但没聚集的属性,要出现在group by子句中
空值和聚集
select sum(salary) from instructor
在进行sum运算的时候忽略null值
处理空值规则如下
- 除了 count(*)外,所有聚集函数都忽略空值
- 如果只有空值(空集
count函数返回0
其他函数返回null
聚集函数一般在select、having子句中使用
where、having、聚集运算顺序
- 根据
from计算关系 - 应用
where的谓词 - 满足where谓词的元组通过
group by子句形成分组 having存在则作用于每个分组,不满足having则抛弃- 剩余分组被select子句应用
聚集函数产生结果
嵌套子查询
子查询是嵌套在另一个查询中select-from-where表达式
对于成员资格、集合比较、集合基数比较
select distinct course_id from section
where semester = 'fall' and year = 2009 and course_id in
(select course_id from section where semester = 'spring' and year = 2010);
2009秋季与2010春季同时开课的所有id
2009秋季开设但不在2010春季开课的所有id
上式in改为not in
找出选修ID位10101教师讲授课程段的学生的总数
select count(distinct ID)
from takes
where (course_id, sec_id, semester, year) in
(select course_id, sec_id, semester,year from teaches where teaches.ID = 10101)
空关系测试
测试子查询结果是否为空集(是否存在元组
使用exists
子查询非空返回ture
“找出在
2009年秋季学期和2010年春季学期同时开课的所有课程”
select course_id from section as S
where semester = 'Fall' and year = 2009
and exists
(
select *
from section as T
where semester = 'Spring' and year = 2010
and S.course_id = T.course_id
);
相关子查询:使用了来自外层查询中出现的表的列的子查询
相关名称作用域:在一个子查询中,可以使用此子查询本身定义的、或者包括此子查询的任何查询中定义的相关名称;类似于编程语言中的变量作用域
Not Exist
使用not exists (B except A)表示关系A中原足迹和包含关系B的元组集合
B−A=∅ ⟺ B⊆AB-A = \empty \iff B\sube AB−A=∅⟺B⊆A
找出选修了Biology系开设的所有课程的学生
select distinct S.ID, S.name
from student as S
where not exists
(
(
select course_id
from course
where dept_name = 'Biology'
)
except
(
select T.course_id
from takes as T
where S.ID = T.ID
)
)
集合比较
所有比biology某一个教师工资高的老师姓名

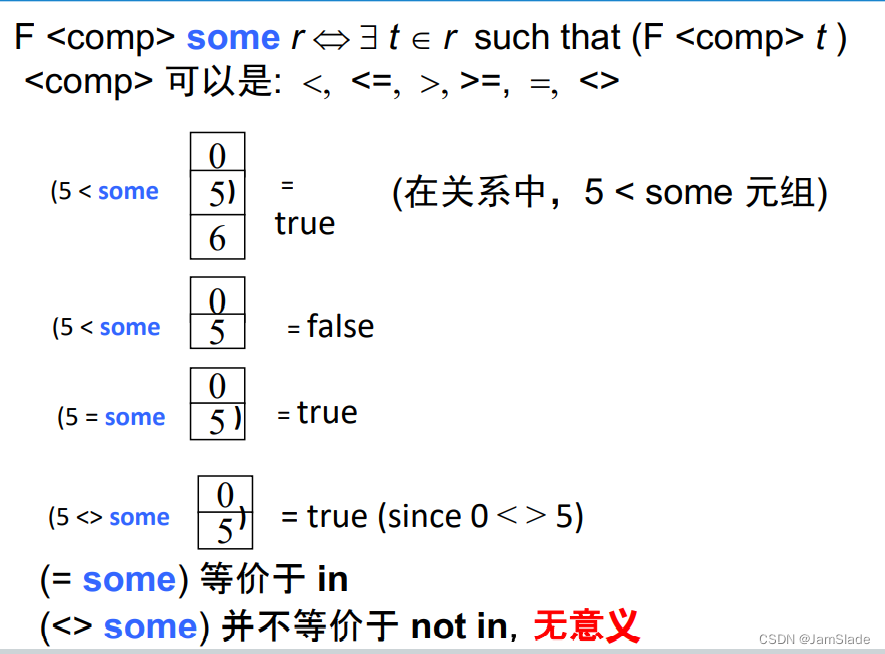
改成每个的话,要把some改成all

From
除了where,SQL允许再from子句中使用子查询表达式
找出系平均工资超过42000系的老师的平均工资
select dept_name, avg_salary
from
(
select dept_name, avg(salary) as avg_salary
from instructor
group by dept_name
)where ave_salary > 42000;
# 这里 使用了where不需要再次使用having
select dept_name, ave salary
from
(
select dept_name, avg(salary)
from instructor
group by dept_name
)
as dept_avg(dept_name, avg_salary)
where avg_salary > 42000;
lateral关键字
使得from子句中的子查询使用来自其他关系的
相关变
select name, salary, avg_salary
from instructor as I1, lateral
(
select avg(salary) as avg_salary
from instructor as I2
where I2.dept_name = I1.dept_name
);
标量子查询
标量子查询:该子查询返回包含单个属性的单个元组(count、max)
select dept_name , #后面这一部分也是输出的部分
(
select count(*) #这个系的老师数量
from instructor
where department.dept_name = instructor.dept_name
as num_of_instructors
)
from department
➢标量子查询可以出现在select、where、having子句中
➢ 如果子查询被执行后其结果中有不止一个元组,则产生一个运行错
不带from子句标量
➢ 某些查询语句需要计算,无需引用任何关系
➢ 例如:查询平均每位教师所讲授(无论是学年还是学期)的课程段数,其中由多位教师所讲授的课程段对
每位教师计数一次
(select count(*) from teches) / (select count(*) from instrucot)
可以除法前×1.0减少精度损失
或者使用cast类型转换
数据库修改
删
delete from instructor
删除所有
delete from instructor
where dept_name =
‘Finance’;
删除一个系
删除再waston大楼系工作的老师
delete from instructor
where dept_name in
(
select dept_name
from departmen
where building - 'waston'
);
delete from instructor
where salary <
(
select avg (salary)
from instructor
);
插入
insert into course
values (’CS-437’,’Database Systems’,’Comp. Sci.’,4);
#等价
insert into course (course_id, title, dept_name, credits)
values (’CS-437’, ’Database Systems’, ’Comp. Sci.’, 4);
# keyi
将所有的教师元组插入student 关系中,同时使tot_creds置为0
insert into student
select ID, name, dept_name, 0
from instructor
在执行插入之前先执行完 select from where 语句非常重要,
否则会出现错误
更新
update instrucotr
set salary = salary * 1.03
where salary > 100000;
update instructor
set salary = salary * 1.05
where salary <= 100000;
精度问题会影响顺序不能替换。否则工资略少于100000美元的老师会涨8.15%
case语句更新
update instructor
set salary = case
when salary <= 100000 then salary * 1.05
else salary * 1.03
end
格式如下
case
when pred1 then result1
when pred2 then result2
…
when predn then resultn
else result0
end
标量子查询的更新
为学生计算更新tot_creds
update student S
set tot_cred =
(
select sum(credits)
from takes natural join course
where S.ID = takes.ID
and takes.grade <> 'F'
and takes.grade is not null
);
# 如果一个学生没有成功学完任何课程,则将 tot_creds 置空
# 若需要空值改成零
update student S
set tot_cred =
(
select case
when sum(credits) is not null
then sum(credits)
else 0
end
from takes natural join course
where S.ID = takes.ID
and takes.grade <> 'F'
and takes.grade is not null
);


















 1655
1655


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








