




 本文详细探讨了流水线处理器中的数据依赖问题,如RAW、WAR、WAW冒险,以及如何通过前递(forwarding)来减少延迟。在没有前递的情况下,插入NOP指令来消除冒险,而在全前递支持下,执行时间显著减少。此外,还分析了不同类型的前递(如仅EX/MEM或仅MEM/WB)对性能的影响。文章指出,分支预测和延迟槽策略对于避免控制冒险和提高效率至关重要。最后,讨论了单发和双发处理器的性能对比,展示了多发处理器在执行循环代码时的潜在加速效果。
本文详细探讨了流水线处理器中的数据依赖问题,如RAW、WAR、WAW冒险,以及如何通过前递(forwarding)来减少延迟。在没有前递的情况下,插入NOP指令来消除冒险,而在全前递支持下,执行时间显著减少。此外,还分析了不同类型的前递(如仅EX/MEM或仅MEM/WB)对性能的影响。文章指出,分支预测和延迟槽策略对于避免控制冒险和提高效率至关重要。最后,讨论了单发和双发处理器的性能对比,展示了多发处理器在执行循环代码时的潜在加速效果。
4.9
In this exercise, we examine how data dependences aff ect execution in the
basic 5-stage pipeline described in Section 4.5. Problems in this exercise refer to the
following sequence of instructions:
or r1,r2,r3
or r2,r1,r4
or r1,r1,r2
Also, assume the following cycle times for each of the options related to forwarding:
| Without Forwarding | With Full Forwarding | With ALU-ALU Forwarding Only |
|---|---|---|
| 250ps | 300ps | 290ps |
1
[10] <§4.5> Indicate dependences and their type
把这三个指令分别标为①②③
- R1需要完成在①写入操作后才能获得正确的值进行②和③,因此会产生RAW stall
- R2在②写入后才能讲正确结果给③,也会产生RAW stall
- R2在①中需要把数据载出后才能在②中当载入寄存器,产生 WAR stall
- R1在②中载出后要在③中当载入寄存器,产生 WAR stall
- R1在①载入后,在③也有载入, 产生 WAW stall
2
[10] <§4.5> Assume there is no forwarding in this pipelined processor. Indicate hazards and add nop instructions to eliminate them.
WAR和 WAW dependence不会造成任何冒险。在没有forwarding的情况下,一条指令和下两条指令之间的任何原始dependence(寄存器写入发生在前半部分,通识寄存器读取发生在时钟周期的后半部分——也就是RAW操作)通过插入NOP指令(空操作)这些hazard的代码如下
or r1,r2,r3
NOP
NOP
or r2,r1,r4
NOP
NOP
or r1,r1,r2
3
[10] <§4.5> Assume there is full forwarding. Indicate hazards and add NOP
instructions to eliminate them.
如果有 full forwarding, ALU指令可以将值前递到下一条指令的EX阶段的同时不产生hazard。需要注意的是:load有关的值不能前递到下一条指令的EX阶段。代码如下
or r1,r2,r3
or r2,r1,r4 # 没有RAW hazrad
or r1,r1,r2
4
[10] <§4.5> What is the total execution time of this instruction sequence
without forwarding and with full forwarding? What is the speedup achieved by adding full forwarding to a pipeline that had no forwarding?
总执行时间时钟周期时间×周期数\quad时钟周期时间\times 周期数\quad时钟周期时间×周期数(不包括stall的时间)
三指令序列要进行五个周期(1个指令5个周期,加一个指令多一个周期)
没有forwarding 参考4.9.2
有forwarding 参考4.9.3
no forward
(7+4)×250=2750(7+4)\times 250 = 2750(7+4)×250=2750
forwarding
7×300=21007\times 300 = 21007×300=2100
| no forwarding | full forwarding |
|---|---|
| 2750ps | 2100ps |
加速比
2750/2100=1.30952750/2100=1.30952750/2100=1.3095
5
[10] <§4.5> Add nop instructions to this code to eliminate hazards if there
is ALU-ALU forwarding only (no forwarding from the MEM to the EX stage).
ALU-ALU-only forwarding, ALU指令可以前递给下一个指令,但是不能传送给往后的第二个指令(不然那就不是ALU forwarding了,就是普通的forwarding——从MEM到EX) load指令也不能前递(因为需要在MEM阶段才能确定寄存器的数据,这对于ALU-forwarding操作来说太迟了)
or r1,r2,r3
or r2,r1,r4 # 对①的R1进行 ALU-ALU forwarding
or r1,r1,r2 # 对②的R2进行ALU-ALU forwarding
6
[10] <§4.5> What is the total execution time of this instruction sequence
with only ALU-ALU forwarding? What is the speedup over a no-forwarding
pipeline?
7×290=20307\times 290 = 20307×290=2030
2750/2030=1.3542750/2030=1.3542750/2030=1.354
4.11
Consider the following loop.
loop:lw r1,0(r1)
and r1,r1,r2
lw r1,0(r1)
lw r1,0(r1)
beq r1,r0,loop
Assume that perfect branch prediction is used (no stalls due to control hazards),
that there are no delay slots, and that the pipeline has full forwarding support. Also
assume that many iterations of this loop are executed before the loop exits.
1
[10] <§4.6> Show a pipeline execution diagram for the third iteration of
this loop, from the cycle in which we fetch the fi rst instruction of that iteration up
to (but not including) the cycle in which we can fetch the fi rst instruction of the
next iteration. Show all instructions that are in the pipeline during these cycles (not
just those from the third iteration).
取出循环首条指令开始到区出下次循环的首条指令(不包括该条取值)结束,给出流水线的所有指令
1 2 3 4 5 6 7 8
lw r1,0(r1) WB
lw r1,0(r1) EX MEM WB
beq r1,r0,loop ID ... EX MEM WB
lw r1,0(r1) IF ... ID EX MEM WB
and r1,r1,r2 IF ID ... EX MEM WB
lw r1,0(r1) IF ... ID EX MEM
lw r1,0(r1) IF ID ...
beq r1,r0,loop IF ...
这里beq不管是否跳转,都先进行下一个instruction(默认不进行跳转),但是没有instruction了,就变成bubble了,所以后续的and操作是跟着bubble后才开始和lw得ID阶段同时操作
2
[10] <§4.6> How oft en (as a percentage of all cycles) do we have a cycle in which all fi ve pipeline stages are doing useful work?
在特定的时钟周期中,如果流水线某个阶段暂停或者该阶段的指令没有做任何有效的工作,流水线就没有做有用的工作。
上文画的流水线执行图中:因为如果没有为特定的周期显示其名称(也就是用…表示的部分),流水线暂停,以及BEQ的WB和AND的MEM都没有做有效的工作。需要注意的是,BEQ指令在MEM阶段正在做有用的工作,因为它正在确定该阶段下一条指令的PC的正确值,
综上这8个指令都没有所有阶段都做了有效工作,都存在bubble
答案为0%0\%0%
4.12
4.12 Th is exercise is intended to help you understand the cost/complexity/
performance trade-off s of forwarding in a pipelined processor. Problems in this
exercise refer to pipelined datapaths from Figure 4.45. Th ese problems assume
that, of all the instructions executed in a processor, the following fraction of these
instructions have a particular type of RAW data dependence. Th e type of RAW
data dependence is identifi ed by the stage that produces the result (EX or MEM)
and the instruction that consumes the result (1st instruction that follows the one
that produces the result, 2nd instruction that follows, or both). We assume that the
register write is done in the fi rst half of the clock cycle and that register reads are
done in the second half of the cycle, so “EX to 3rd” and “MEM to 3rd” dependences
are not counted because they cannot result in data hazards. Also, assume that the
CPI of the processor is 1 if there are no data hazards.
| EX to 1st Only | MEM to 1st Only | EX to 2nd Only | MEM to 2nd Only | EX to 1st and MEM to 2nd | Other RAW Dependences |
|---|---|---|---|---|---|
| 5% | 20% | 5% | 10% | 10% | 10% |
Assume the following latencies for individual pipeline stages. For the EX stage,
latencies are given separately for a processor without forwarding and for a processor
with diff erent kinds of forwarding.
| IF | ID | EX(no FW) | EX(full FW) | EX (FW from EX/MEM only) | EX (FW from MEM/WB only) | MEM | WB |
|---|---|---|---|---|---|---|---|
| 150 ps | 100 ps | 120 ps | 150 ps | 140 ps | 130 ps | 120 ps | 100 ps |
1
[10] <§4.7> If we use no forwarding, what fraction of cycles are we stalling
due to data hazards?
与下一条指令的依赖导致2个暂停周期,如果与往后第一条和往后第二条的指令的依赖同时存在,也是暂停2个周期。仅依赖于往后第二条指令会导致1个暂停周期
有关1st的
0.05+0.2+0.1=0.350.05+0.2+0.1=0.350.05+0.2+0.1=0.35
仅仅有关2nd的
0.05+0.1=0.150.05+0.1=0.150.05+0.1=0.15
CPI=1+0.35×2+0.15×1=1.85CPI = 1+0.35\times 2+0.15\times 1=1.85CPI=1+0.35×2+0.15×1=1.85
stall cycles =0.85/1.85=46%0.85/1.85=46\%0.85/1.85=46%
2
[5] <§4.7> If we use full forwarding (forward all results that can be
forwarded), what fraction of cycles are we staling due to data hazards?
使用前递的话,只有 RAW数据依赖(下一个指令依赖MEM阶段)会导致一个周期暂停
MEM与下一个指令相关的只占20%
CPI=1+0.2×1=1.2CPI = 1+0.2\times 1=1.2CPI=1+0.2×1=1.2
stall cycle
0.2/1.2=17%0.2/1.2 = 17\%0.2/1.2=17%
3
4.12.3 [10] <§4.7> Let us assume that we cannot aff ord to have three-input Muxes
that are needed for full forwarding. We have to decide if it is better to forward
only from the EX/MEM pipeline register (next-cycle forwarding) or only from
the MEM/WB pipeline register (two-cycle forwarding). Which of the two options
results in fewer data stall cycles?
只对EX/MEM寄存器前递的话,EX到下一条指令的暂停周期可以避免,但是其他的依赖就无法避免,会引发一个暂停周期(对于MEM TO 1st甚至是两个暂停周期)。
只对MEM/WB寄存器前递的话, EX到往后第二条指令依赖不会产生暂停周期,而MEM对下一条指令的依赖仍然会产生一个暂停周期,EX到下一个指令以来也会导致一个暂停周期(因为必须要等指令完成MEM阶段操作才能前递)
| EX to 1st Only | MEM to 1st Only | EX to 2nd Only | MEM to 2nd Only | EX to 1st and MEM to 2nd | Other RAW Dependences |
|---|---|---|---|---|---|
| 5% | 20% | 5% | 10% | 10% | 10% |
BTW,这里是按照出现的频率来计算的(百分比),为了方便第六问的计算
并且不考虑最后一个RAW
EX/MEM
0.2这里是停两个周期,答案没×2感觉有问题
0.2×2+0.05+0.1+0.1=0.650.2\times 2+0.05+0.1+0.1=0.650.2×2+0.05+0.1+0.1=0.65
MEM/WB
0.05+0.2+0.1=0.350.05+0.2+0.1=0.350.05+0.2+0.1=0.35
显然后者产生暂停周期更少
4
4.12.4 [10] <§4.7> For the given hazard probabilities and pipeline stage latencies,
what is the speedup achieved by adding full forwarding to a pipeline that had no
forwarding?
没有旁路
1.85×120=2221.85\times 120 = 2221.85×120=222
有旁路
1.2×150=1801.2\times 150 = 1801.2×150=180
加速
222/180=1.23222/180=1.23222/180=1.23
5
4.12.5 [10] <§4.7> What would be the additional speedup (relative to a processor
with forwarding) if we added time-travel forwarding that eliminates all data
hazards? Assume that the yet-to-be-invented time-travel circuitry adds 100 ps to
the latency of the full-forwarding EX stage.
时间旅行
1×250=2501\times 250 = 2501×250=250
原本有EX级完全旁路
180180180
加速比
180/250=0.72180 / 250 = 0.72180/250=0.72
6
4.12.6 [20] <§4.7> Repeat 4.12.3 but this time determine which of the two
options results in shorter time per instruction
EX/MEM
1.64×140=2311.64\times 140 = 2311.64×140=231
MEM/WB
1.35×130=175.51.35\times 130 = 175.51.35×130=175.5
显然后者
4.13.1-3
4.13 Th is exercise is intended to help you understand the relationship between
forwarding, hazard detection, and ISA design. Problems in this exercise refer to
the following sequence of instructions, and assume that it is executed on a 5-stage
pipelined datapath:
add r5,r2,r1
lw r3,4(r5)
lw r2,0(r2)
or r3,r5,r3
sw r3,0(r5)
1
4.13.1 [5] <§4.7> If there is no forwarding or hazard detection, insert nops to
ensure correct execution.
add r5,r2,r1
NOP #RAW要暂停两个Cycle
NOP
lw r3,4(r5)
lw r2,0(r2)
NOP #本来要暂停两个Cycle,但是这个r3在第二个指令所以只暂停一个
or r3,r5,r3
NOP
NOP
sw r3,0(r5)
2
4.13.2 [10] <§4.7> Repeat 4.13.1 but now use nops only when a hazard cannot be
avoided by changing or rearranging these instructions. You can assume register R7
can be used to hold temporary values in your modifi ed code.
add r5,r2,r1
lw r2,0(r2)
NOP
lw r3,4(r5)
NOP
NOP
or r3,r5,r3
NOP
NOP
sw r3,0(r5)
由于这里并没有WAW和WAR依赖,所以R7并没有用到
3
4.13.3 [10] <§4.7> If the processor has forwarding, but we forgot to implement
the hazard detection unit, what happens when this code executes?
没有冒险检测单元会导致load操作进行时间旅行冒险,会让寄存器将旧的数据提前传给后续分支
但4.13这个代码可以正确执行
4.14.1-2
4.14 Th is exercise is intended to help you understand the relationship between
delay slots, control hazards, and branch execution in a pipelined processor. In
this exercise, we assume that the following MIPS code is executed on a pipelined
processor with a 5-stage pipeline, full forwarding, and a predict-taken branch
predictor:
lw r2,0(r1)
label1: beq r2,r0,label2 # not taken once, then taken
lw r3,0(r2)
beq r3,r0,label1 # taken
add r1,r3,r1
label2: sw r1,0(r2)
1
4.14.1 [10] <§4.8> Draw the pipeline execution diagram for this code, assuming
there are no delay slots and that branches execute in the EX stage.
没有延迟时间槽和移到EX级执行分支
每次时间跳转要延迟一个cycle,并且如果是 RAW 还得延迟到EX结束
1 2 3 4 5 6 7 8 9 10 11 12 13 14
lw r2,0(r1) IF ID EX MEM WB
beq r2,r0,label2 IF ID ... EX MEM WB
lw r3,0(r2) IF ID EX MEM WB
beq r3,r0,label1 IF ID ... EX MEM WB
beq r2,r0,label2 IF ... ID EX MEM WB
sw r1,0(r2) IF ID EX MEM WB
2
4.14.2 [10] <§4.8> Repeat 4.14.1, but assume that delay slots are used. In the
given code, the instruction that follows the branch is now the delay slot instruction
for that branch.
使用延迟时间槽,跟在分支后面的指令是延迟槽指令
1 2 3 4 5 6 7 8 9 10 11 12 13 14
lw r2,0(r1) IF ID EX MEM WB
beq r2,r0,label2 IF ID ... EX MEM WB
#(NT)
lw r3,0(r2) IF ... ID EX MEM WB
beq r3,r0,label1 IF ID EX MEM WB
add r1,r3,r1 IF ID EX MEM WB
#先假定没跳转,先执行add
beq r2,r0,label2 IF ID EX MEM WB
lw r3,0(r2) IF ID EX MEM WB
#同上
sw r1,0(r2) IF ID EX MEM WB
延迟时间槽可以理解成:beq后面直接跟着“原来程序”的下一个指令。如果beq预测成功,beq后续第二个指令进行跳转成功之后的指令,没成功就暂停1个cycle再进行原来后续的第二个指令
因为本质上如果预测失败,本来就会产生两个NOP指令来清除本身预测失败导致的代价。
所以用延迟时间槽来把一个“不会影响最终结果”的指令插入到beq后面,充分利用CPU
所以预测成功——多做了一个不影响结果的指令,然后后续第二个指令便是跳转后的操作。
预测失败——至少也有一个指令占用了2个NOP的其中一个
5
4.14.5 [10] <§4.8> For the given code, what is the speedup achieved by moving
branch execution into the ID stage? Explain your answer. In your speedup
calculation, assume that the additional comparison in the ID stage does not aff ect
clock cycle time
执行分支移到ID的图标如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
lw r2,0(r1) IF ID EX MEM WB
beq r2,r0,label2 IF ... ... ID EX MEM WB
lw r3,0(r2) IF ID EX MEM WB
beq r3,r0,label1 IF ... ... ID EX MEM WB
beq r2,r0,label2 IF ... ID EX MEM WB
sw r1,0(r2) IF ID EX MEM WB
加速比为:
14/15=0.9314/15=0.9314/15=0.93
4.15.1-3
Th e importance of having a good branch predictor depends on how oft en
conditional branches are executed. Together with branch predictor accuracy, this
will determine how much time is spent stalling due to mispredicted branches. In
this exercise, assume that the breakdown of dynamic instructions into various
instruction categories is as follows:
| R-Type | BEQ | JMP | LW | SW |
|---|---|---|---|---|
| 40% | 25% | 5% | 25% | 5% |
Also, assume the following branch predictor accuracies:
| Always-Taken | Always-Not-Taken | 2-Bit |
|---|---|---|
| 45% | 55% | 85% |
1
[10] <§4.8> Stall cycles due to mispredicted branches increase the
CPI. What is the extra CPI due to mispredicted branches with the always-taken
predictor? Assume that branch outcomes are determined in the EX stage, that there
are no data hazards, and that no delay slots are used.
不正确的预判分支会导致2个循环暂停
根据数据,对应的不发生预判为55%, 且有25%的分支判断
2×0.55×0.25=0.2752\times0.55\times 0.25 = 0.2752×0.55×0.25=0.275
2
[10] <§4.8> Repeat 4.15.1 for the “always-not-taken” predictor
反过来就是45%
2×0.45×0.25=0.2252\times0.45\times 0.25 = 0.2252×0.45×0.25=0.225
3
[10] <§4.8> Repeat 4.15.1 for for the 2-bit predictor.
对应的没预判成功的概率就是1-0.85
2×(1−0.85)×0.25=0.0752\times (1-0.85)\times 0.25 = 0.0752×(1−0.85)×0.25=0.075
6
[10] <§4.8> Some branch instructions are much more predictable than
others. If we know that 80% of all executed branch instructions are easy-to-predict
loop-back branches that are always predicted correctly, what is the accuracy of the
2-bit predictor on the remaining 20% of the branch instructions?
- 预测正确率为0.85
- 其中有0.8是很好预测的,相减得到剩下20%中正确预测的有5%
- 计算公式为0.05/0.20=25%0.05/0.20=25\%0.05/0.20=25%
4.16.1-3
Th is exercise examines the accuracy of various branch predictors for the
following repeating pattern (e.g., in a loop) of branch outcomes: T, NT, T, T, NT
1
4.16.1 [5] <§4.8> What is the accuracy of always-taken and always-not-taken
predictors for this sequence of branch outcomes?
NT占比
2/5=40%2/5=40\%2/5=40%
T占比
3/5=60%3/5=60\%3/5=60%
2
4.16.2 [5] <§4.8> What is the accuracy of the two-bit predictor for the fi rst 4
branches in this pattern, assuming that the predictor starts off in the bottom left
state from Figure 4.63 (predict not taken)?
一开始是4-63左下角状态
那么
- 预测未发生,第一次为T,变为4-63右下角状态,错误
- 预测未发生,第二次为NT,变为4-63左下角状态,正确
- 预测未发生,第三次为T,变为4-63右下角状态,错误
- 预测未发生,第四次为T,变为4-63右上角状态,错误
accuracy
1/4=25%1/4=25\%1/4=25%
3
4.16.3 [10] <§4.8> What is the accuracy of the two-bit predictor if this pattern is
repeated forever?
每次循环
- 左下,右下,左下,右下,右上
- 右下,右上,右下,右上,左上
- 右上,左上,右上,左上,左上
- 右上,左上,右上,左上,左上
从第3次循环开始,状态就固定在右上,左上,右上,左上,左上的情况,准确率为
3/5=60%3/5=60\%3/5=60%
4.18
In this exercise we compare the performance of 1-issue and 2-issue
processors, taking into account program transformations that can be made to
optimize for 2-issue execution. Problems in this exercise refer to the following loop
(written in C):
for(i=0;i!=j;i+=2)
b[i]=a[i]–a[i+1];
When writing MIPS code, assume that variables are kept in registers as follows, and
that all registers except those indicated as Free are used to keep various variables,
so they cannot be used for anything else.
| i | j | a | b | c | Free |
|---|---|---|---|---|---|
| R5 | R6 | R1 | R2 | R3 | R10, R11, R12 |
1
4.18.1 [10] <§4.10> Translate this C code into MIPS instructions. Your translation
should be direct, without rearranging instructions to achieve better performance.
add r5,r0,r0
loop: beq r5,r6,flag
slli r12,r5,2 #这里我把它认为是int类型数组
#如果是字符串就把slli去掉即可
add r10,r1,r12 #a[i]的地址,默认是字符串就把r12换r5
lw r11,0(r10)
lw r10,4(r10)
sub r10,r11,r10
add r11,r12,r2 #b[i]的地址,操作同上
sw r10,0(r11)
addi r5,r5,2
flag:
2
4.18.2 [10] <§4.10> If the loop exits aft er executing only two iterations, draw a
pipeline diagram for your MIPS code from 4.18.1 executed on a 2-issue processor
shown in Figure 4.69. Assume the processor has perfect branch prediction and can
fetch any two instructions (not just consecutive instructions) in the same cycle.
这里为了方便画图我还是默认这个是char数组吧。。。
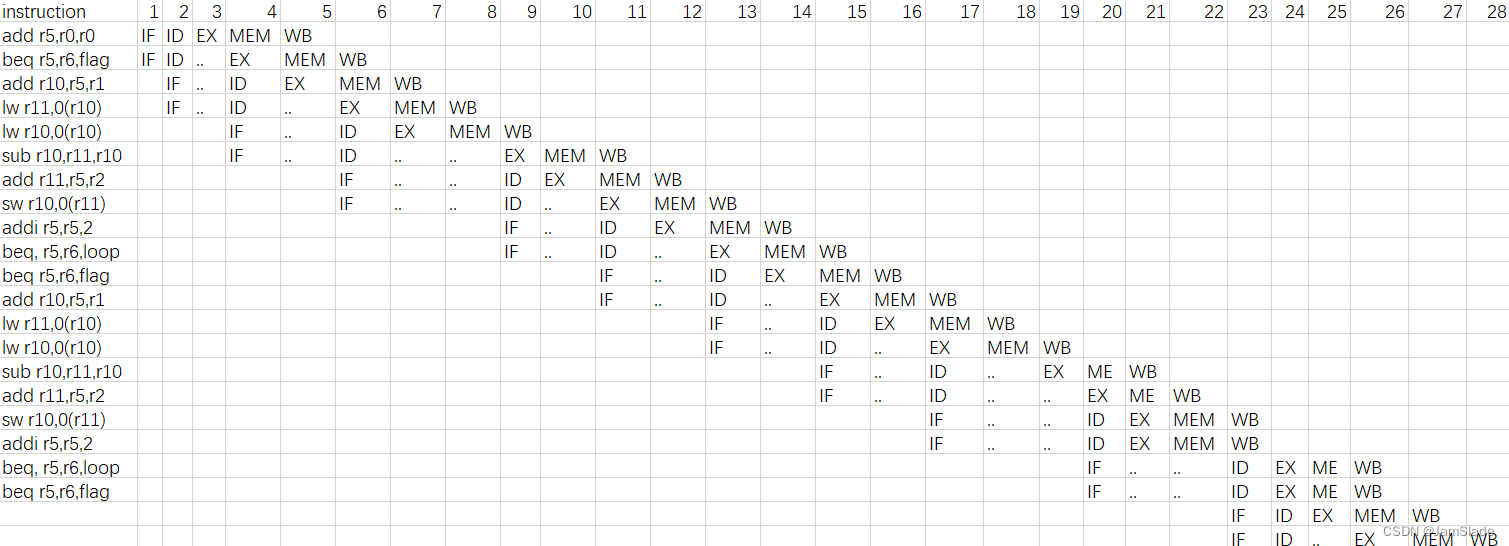
3
4.18.3 [10] <§4.10> Rearrange your code from 4.18.1 to achieve better
performance on a 2-issue statically scheduled processor from Figure 4.69.
这里默认char数组
add r5,r0,r0
loop: add r10,r5,r1
beq, r5,r6,flag
lw r11,0(r10)
add r12,r5,r2
lw r10,1(r10)
addi r5,r5,2
sub r10,r11,r10
sw r10,0(r12)
beq r0,r0 loop
flag:
4
4.18.4 [10] <§4.10> Repeat 4.18.2, but this time use your MIPS code from 4.18.3.
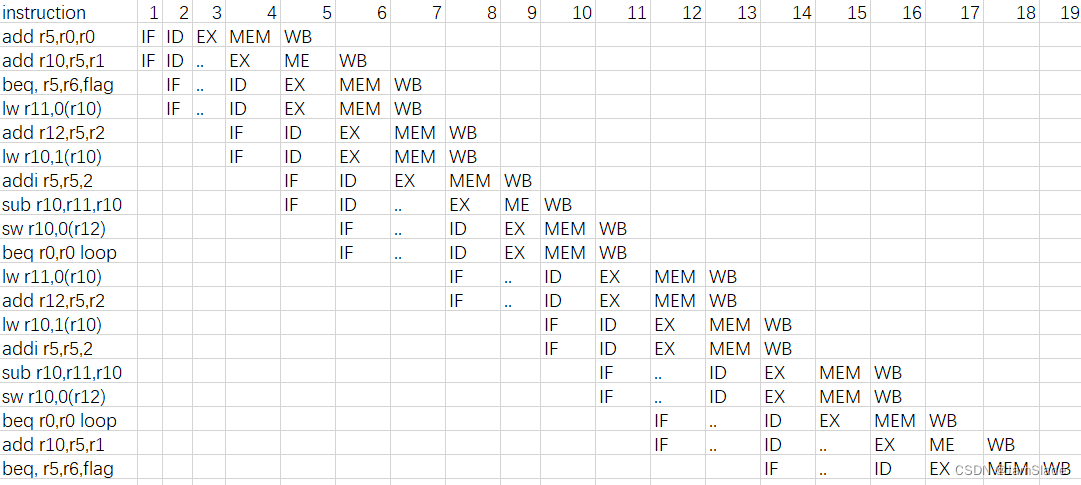
5
4.18.5 [10] <§4.10> What is the speedup of going from a 1-issue processor to
a 2-issue processor from Figure 4.69? Use your code from 4.18.1 for both 1-issue
and 2-issue, and assume that 1,000,000 iterations of the loop are executed. As in
4.18.2, assume that the processor has perfect branch predictions, and that a 2-issue
processor can fetch any two instructions in the same cycle.
单发射处理器:
每9个指令要占用10个循环,所以由于数据冒险,存在一个介于LW和SUB的流水线暂停循环
10/9=1.1110/9=1.1110/9=1.11
双发射处理器
18个指令占用19个循环
两个LW指令都可以和另一个后续指令并行,SUB依赖于第二个LW指令,所以会产生一个SUB暂停,但SUB上面的ADDI不受影响
19/19=1.0519/19=1.0519/19=1.05
1.11/1.05=1.341.11/1.05=1.341.11/1.05=1.34
6
4.18.6 [10] <§4.10> Repeat 4.18.5, but this time assume that in the 2-issue
processor one of the instructions to be executed in a cycle can be of any kind, and
the other must be a non-memory instruction.
如果另一个必须得是非存取指令
那么本来再4.18.5中的ADDI和BEQ将放在第二个iteration中,第二个LW不能和其他操作并行,最终导致每18个指令占用15个cycle
15/19=0.8315/19=0.8315/19=0.83
speedup
1.11/0.83=1.341.11/0.83=1.341.11/0.83=1.34


















 3001
3001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









