




 该博客讨论了一种使用C++实现的优化字典搜索的方法,通过将单词首字母分为26个小类存储以减少搜索时间。代码中处理了大小写字母,并在遍历过程中查找最长匹配的字典单词,输出最大分词并更新位置。注意到了边界条件和字母表检查,复杂度为O(n²)。
该博客讨论了一种使用C++实现的优化字典搜索的方法,通过将单词首字母分为26个小类存储以减少搜索时间。代码中处理了大小写字母,并在遍历过程中查找最长匹配的字典单词,输出最大分词并更新位置。注意到了边界条件和字母表检查,复杂度为O(n²)。
题目

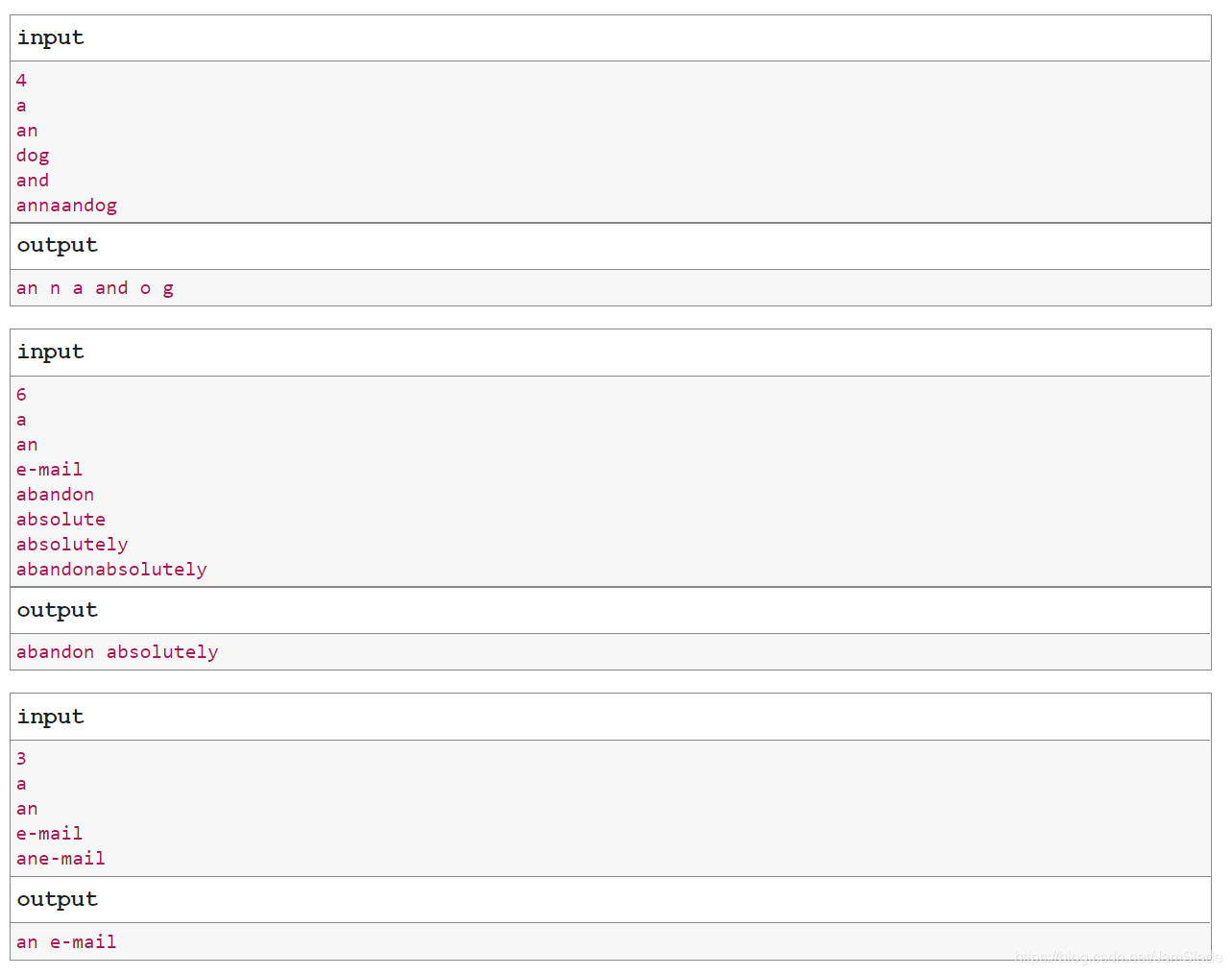
思路
①根据字典的性质,可以把每个字典单词的开头分成26个小类来储存,可以减少搜索时间,如果要省排序就使用set
(看了数据才知道还会出大写字母,需要把大写字母的情况考虑上不然会runtime error)
②存放好之后就是遍历了,遍历没啥好说的,复杂度O(n²)把
老生常谈的越界问题、字母表问题、特判在注释中有提及
代码
#include<iostream>
#include<set>
using namespace std;
//
set<string> S[26];
int main()
{
int n;
string a;
cin >> n;
for(int i = 0; i < n; i++)
{
cin >> a;
if(a[0] >= 'a' && a[0] <='z')
S[a[0] - 'a'].insert(a);
if(a[0] >= 'A' && a[0] <='Z')
S[a[0] - 'A'].insert(a);
}
cin >> a;
int len = a.length();
for(int i = 0; i < len; i++)
{
string max;
int max_len = 0;
for(set<string>::iterator it = ((a[i]>= 'a' && a[i] <='z') ? S[a[i] - 'a'].begin() : S[a[i] - 'A'].begin());
it != ((a[i]>= 'a' && a[i] <='z') ? S[a[i] - 'a'].end() : S[a[i] - 'A'].end()); it++)
{
int flag = 1;//判定字典有没有这个元素
int d_len = it->length();
for(int j = 0; j < d_len && i + j < len; j++)//越界问题
{
if(it->at(j) != a[i + j] || i + d_len > len)
{
flag = 0;
break;
}
}
if(flag)
{
if(d_len > max_len)
{
max = *it;
max_len = d_len;
}
}
}
//找出来最大的分词之后要输出并让i移到新的位置;
if(max_len >= 1)
{
cout << max << " ";
i += max_len - 1;
}
else
{
cout << a[i] << " ";
}
}
cout << endl;
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









