






 本文介绍两种使用Python爬取王者荣耀英雄壁纸的方法:一是不区分文件夹统一存放;二是为每个英雄单独建立文件夹存放。提供了完整的代码示例及exe文件下载。
本文介绍两种使用Python爬取王者荣耀英雄壁纸的方法:一是不区分文件夹统一存放;二是为每个英雄单独建立文件夹存放。提供了完整的代码示例及exe文件下载。
第一种:不分文件夹的
代码
import os
import requests
url = 'https://pvp.qq.com/web201605/js/herolist.json'
response = requests.get(url)
heroList_json = response.json()
hero_dir = 'wangzhe'
if not os.path.exists(hero_dir):
os.mkdir(hero_dir)
# 创建存储的文件,判断是否存在,不存在就创建,自己可以更改
for m in range(len(heroList_json)):
hero_num = heroList_json[m]['ename']
# 获取英雄编号
hero_name = heroList_json[m]['cname']
# 获取英雄名称
skin_names = heroList_json[m]['skin_name'].split('|')
# 根据皮肤名分割成皮肤列表
number = len(skin_names)
# 皮肤数量
n = 1
for i in range(1, number + 1):
# 遍历每一个图片网址
url = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/'
url_photo = url + str(hero_num) + '/' + str(hero_num) + '-bigskin-' + str(i) + '.jpg'
photo = requests.get(url_photo).content
# 获取图片
with open('wangzhe/' + str(hero_name) + '-' + str(skin_names[i - 1]) + '.jpg', 'wb') as f:
f.write(photo)
# 创建文件并写入文件
print(f'{skin_names}的第{n}个皮肤爬取完成')
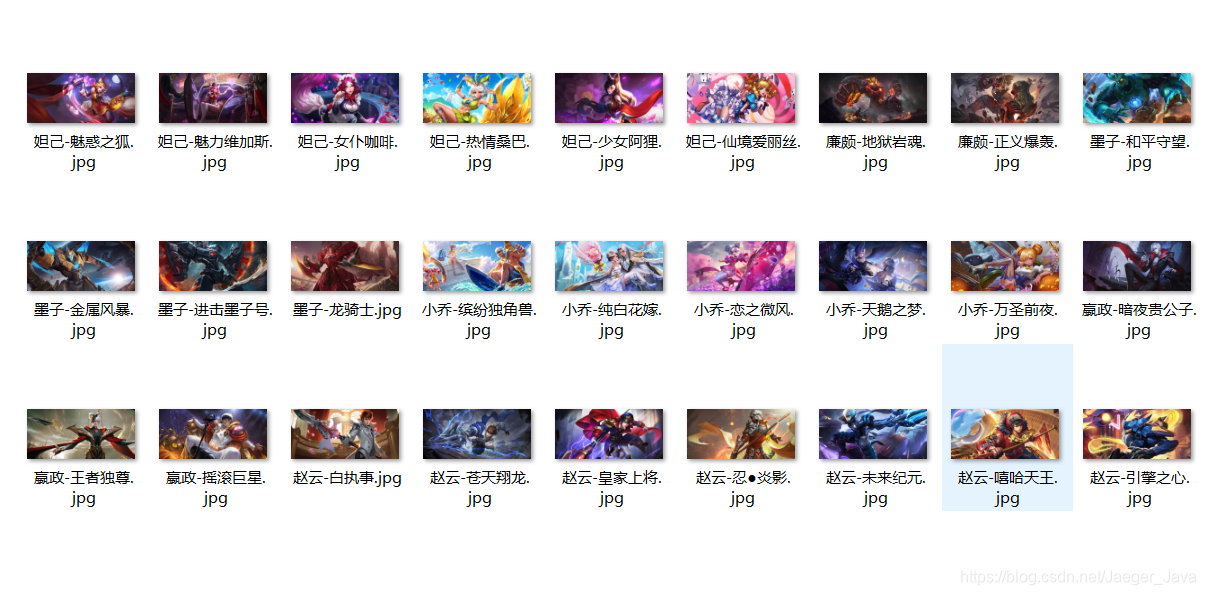
看下效果
第二种:每个英雄分文件夹爬取
代码
# -*- coding: utf-8 -*-
import os
import re
import requests
from bs4 import BeautifulSoup
baseurl = 'http://pvp.qq.com/web201605'
mainurl = 'http://pvp.qq.com/web201605/herolist.shtml'
herolist = []
def getHeroList():
'''取所以英雄存入list中'''
hero = {}
res = requests.get(mainurl)
sp = BeautifulSoup(res.content, "html.parser")
lists = sp.select('body > div.wrapper > div > div > div.herolist-box > div.herolist-content > ul > li')
for li in lists:
oj = li.select('a')[0];
hero['url'] = oj['href']
hero['name'] = oj.text
# 正则表达式取ename编号
ename = re.findall('herodetail/(\d+)\.shtml', oj['href'])[0]
hero['ename'] = ename
herolist.append(hero)
hero = {}
return herolist
def saveImg(filepath, imgUrl):
'''下载图片并保存'''
r = requests.get(imgUrl, stream=True)
with open(filepath, 'wb') as f:
for chunk in r.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
f.flush()
f.close()
if __name__ == '__main__':
hlist = getHeroList()
for hero in herolist:
herodir = os.path.join(os.getcwd(), hero['name'])
heropage = baseurl + '/' + hero['url']
print('[%s]' % (herodir))
res = requests.get(heropage)
sop = BeautifulSoup(res.content, "html.parser")
li = sop.select('body > div.wrapper > div.zk-con1.zk-con > div > div > div.pic-pf > ul ')[0]['data-imgname']
li = str(li).split('|')
print(li)
# 遍历所有皮肤
for i in range(len(li)):
imgurl = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/' \
+ hero['ename'] + '/' + hero['ename'] + '-bigskin-' + str(i + 1) + '.jpg'
imgname = os.path.join(herodir, li[i] + ".jpg")
print('----[%s]--[%s]---' % (imgname, imgurl))
# 创建英雄目录
if os.path.exists(herodir) == False:
os.mkdir(herodir)
saveImg(imgname, imgurl)
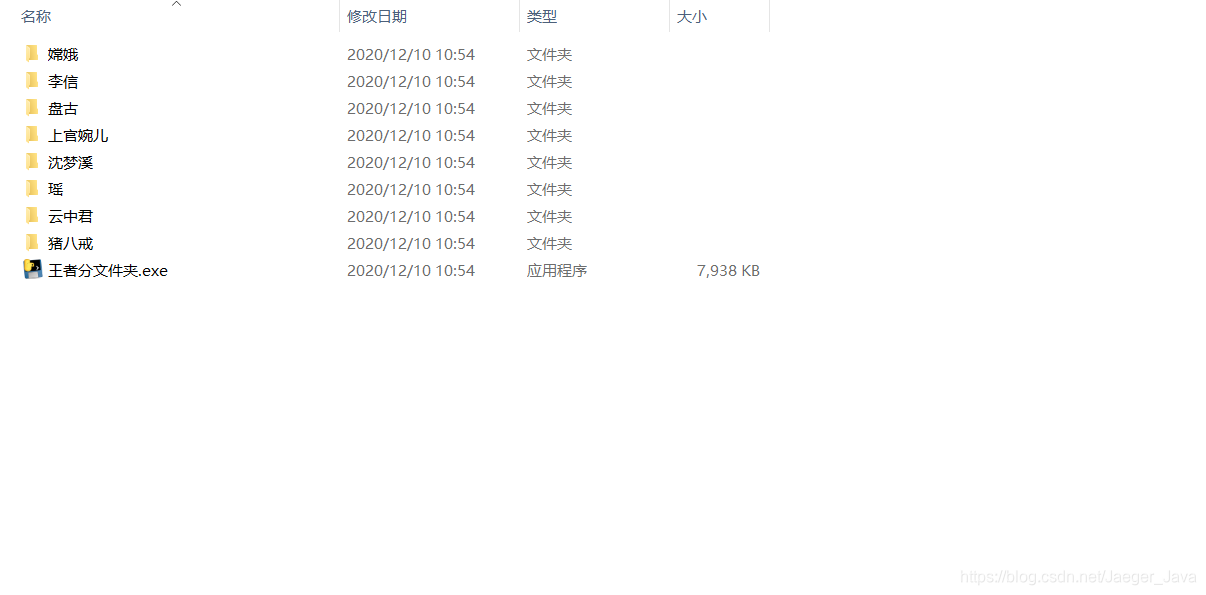
看下效果
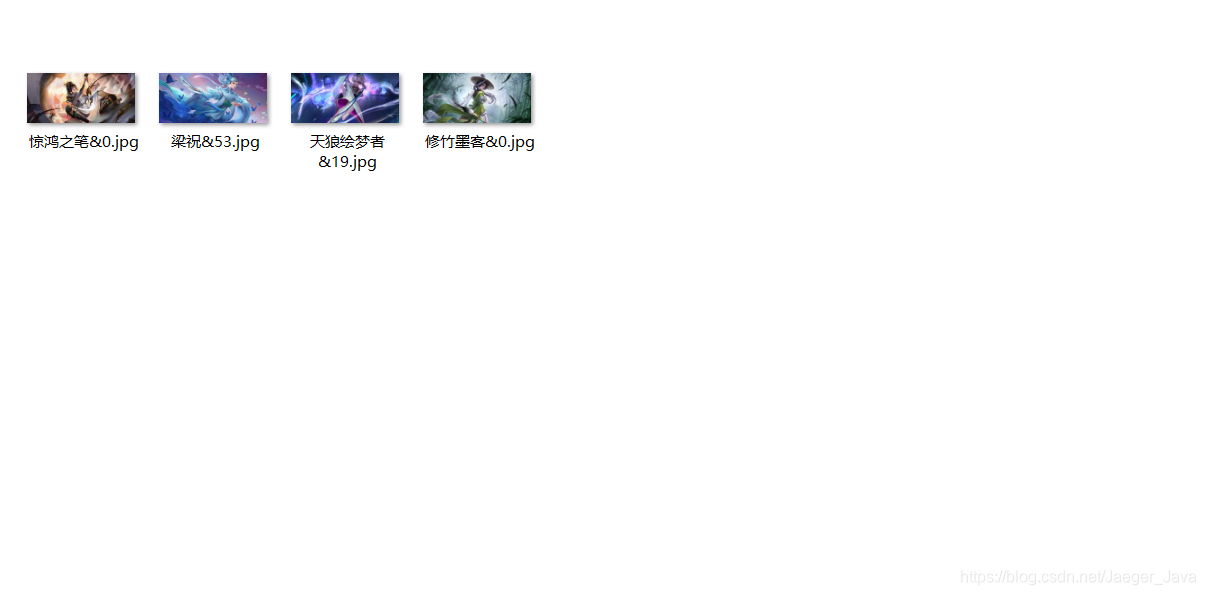
这里针对下没python环境还想获得壁纸的普通人,我已经用pyInstaller打成exe文件了,直接用鼠标双击就可以获取王者海量壁纸了(傻瓜式操作)


















 1385
1385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









