







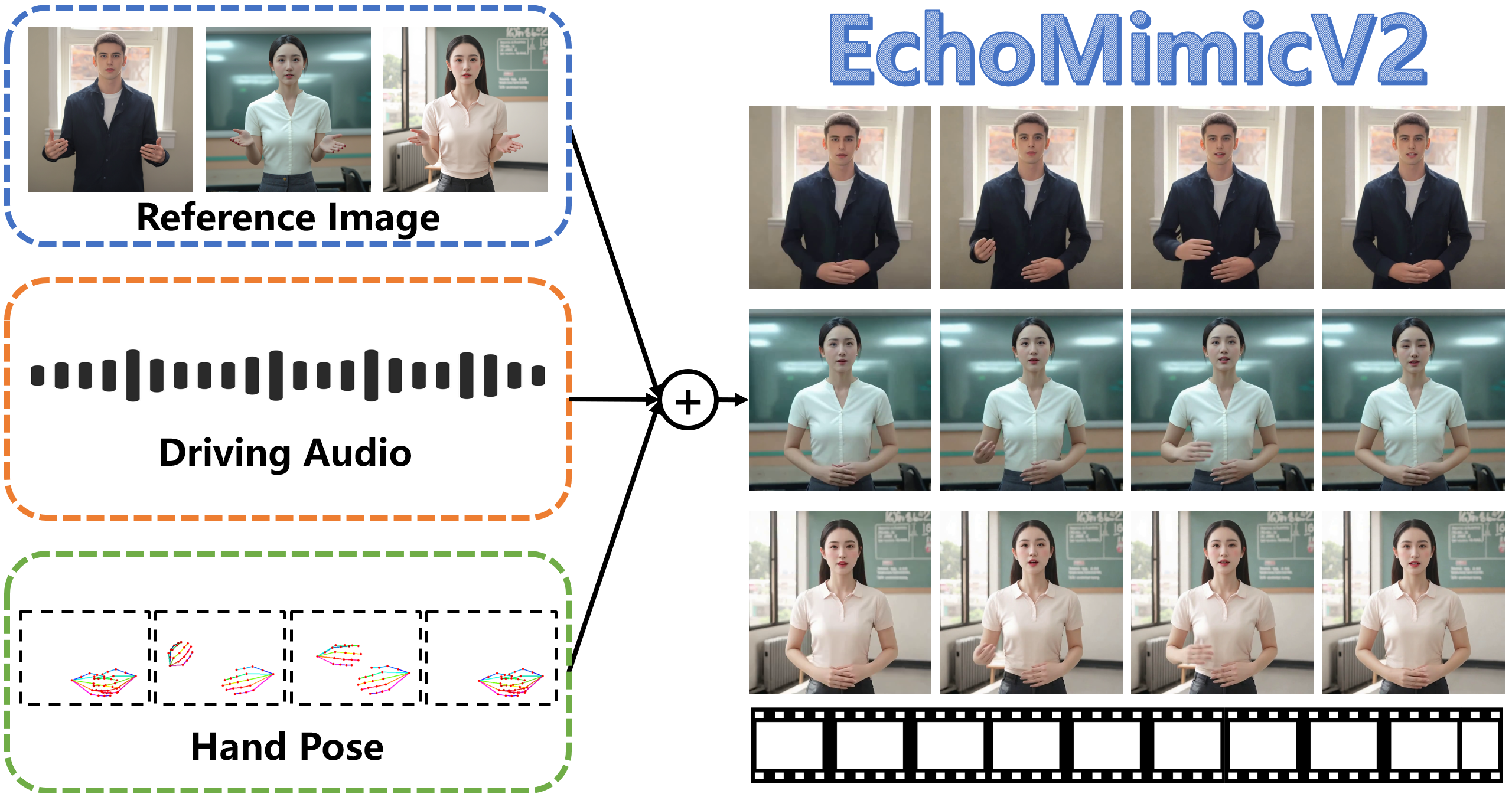
EchoMimicV2是阿里蚂蚁集团推出的半身人体AI数字人项目,基于参考图片、音频剪辑和手部姿势序列生成高质量动画视频,确保音频内容与半身动作的一致性。EchoMimicV2在前代EchoMimicV1生成逼真人头动画的基础上,效果得到进一步提升,现在能生成完整的数字人半身动画,实现从中英文语音到动作的无缝转换。
该项目采用音频-姿势动态协调策略,包括姿势采样和音频扩散,增强细节表现力并减少条件冗余。并使用头部局部注意力技术整合头部数据,设计特定阶段去噪损失优化动画质量。
- 项目官网:https://antgroup.github.io/ai/echomimic_v2
- GitHub 仓库:https://github.com/antgroup/echomimic_v2
- HuggingFace 模型库:https://huggingface.co/BadToBest/EchoMimicV2
- ModelScope 模型库:https://www.modelscope.cn/BadToBest/EchoMimicV2
- arXiv 技术论文:https://arxiv.org/pdf/2411.10061
主要功能
- 音频驱动的动画生成:用音频剪辑驱动人物的面部表情和身体动作,实现音频与动画的同步。
- 半身动画制作:从仅生成头部动画扩展到生成包括上半身的动画。
- 简化的控制条件:减少动画生成过程中所需的复杂条件,让动画制作更为简便。
- 手势和表情同步:基于手部姿势序列与音频的结合,生成自然且同步的手势和面部表情。
- 多语言支持:支持中文和英文驱动,根据语言内容生成相应的动画。
技术原理
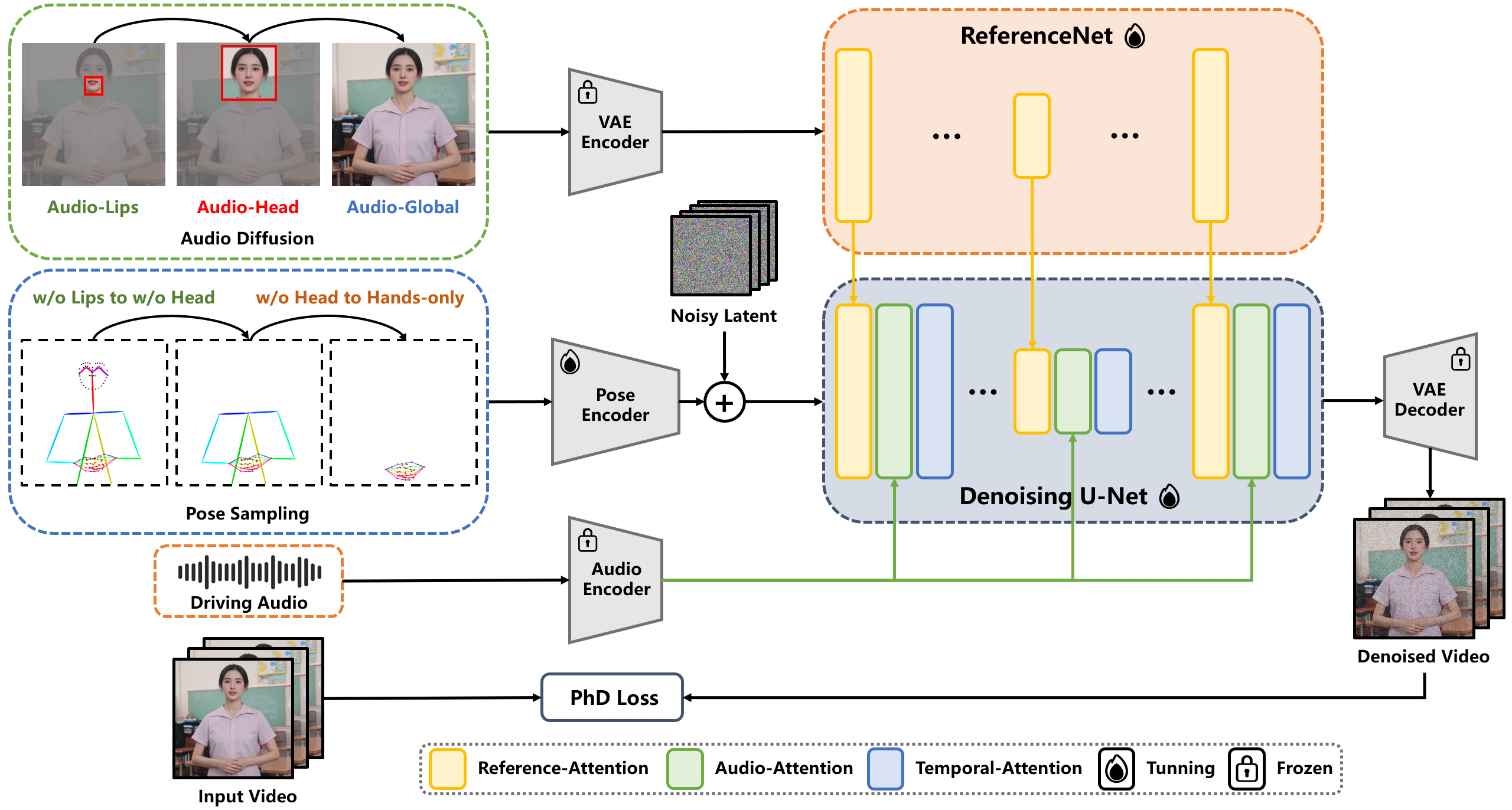
- 音频-姿势动态协调(APDH):
- 姿势采样(Pose Sampling):逐步减少姿势条件的依赖,让音频条件在动画中扮演更重要的角色。
- 音频扩散(Audio Diffusion):将音频条件的影响从嘴唇扩散到整个面部,再到全身,增强音频与动画的同步性。
- 头部局部注意力(Head Partial Attention, HPA):在训练中整合头部数据,增强面部表情的细节,无需额外的插件或模块。
- 特定阶段去噪损失(Phase-specific Denoising Loss, PhD Loss):将去噪过程分为三个阶段:姿势主导、细节主导和质量主导,每个阶段都有特定的优化目标。
- Latent Diffusion Model(LDM):用变分自编码器(VAE)将图像映射到潜在空间,在训练过程中逐步添加噪声,估计并去除每个时间步的噪声。
- ReferenceNet-based Backbone:用ReferenceNet从参考图像中提取特征,将其注入到去噪U-Net中,保持生成图像与参考图像之间的外观一致性。
本次我们直接采用上篇《LLaMA-Factory大模型微调实践 - 从零开始》中的Docker容器进行开源项目EchoMimicV2的开箱体验。
开箱体验
环境要求
- 测试系统环境:Centos 7.2/Ubuntu 22.04, Cuda >= 11.7
- 测试GPU:A100(80G) / RTX4090D (24G) / V100(16G)
- 测试Python版本:3.8 / 3.10 / 3.11
下载代码
git clone https://github.com/antgroup/echomimic_v2
cd echomimic_v2创建conda环境
conda create -n echomimic python=3.10
conda activate echomimic自动化安装部署
sh linux_setup.sh为了加速安装,我们将脚本中关于从huggingface下载的项目地址全部替换为modelscope。

git clone https://www.modelscope.cn/BadToBest/EchoMimicV2.git
git clone https://www.modelscope.cn/zhuzhukeji/sd-vae-ft-mse.git
git clone https://www.modelscope.cn/gqy2468/sd-image-variations-diffusers.git启动demo
为了使容器中地址能被访问,我们修改 Gradio app.py 中的 launch,添加 server_name='0.0.0.0' 。
python app.py
开箱体验
访问 0.0.0.0:7860
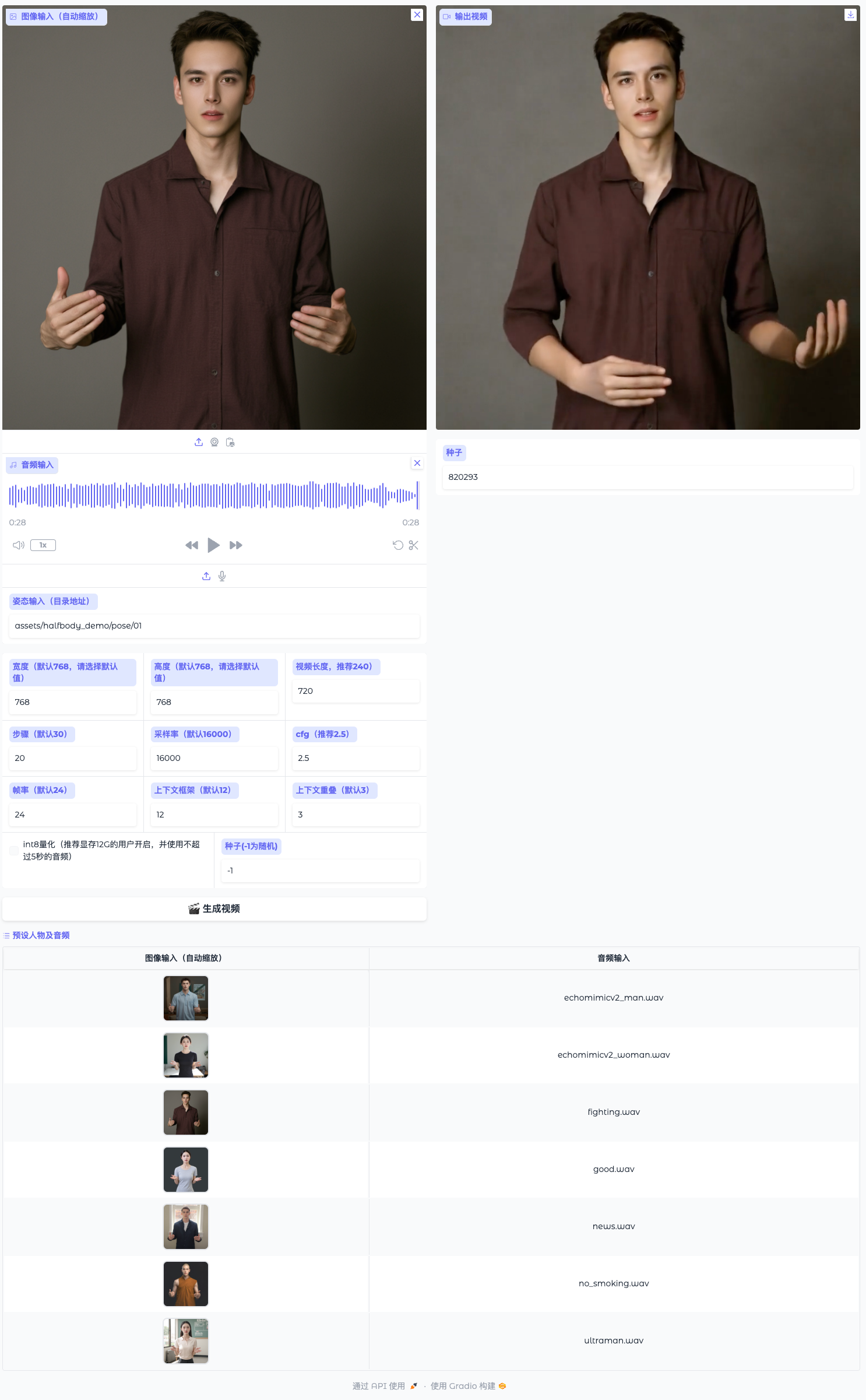
我们从一首AI创作的歌曲中截取了一段28秒的音频,并调整了视频长度到720,大概花了半个小时,生成了一段14秒的数字人动画视频,因为使用了预设人物,效果还不错。如果需要自定义图片可以将主页提供的图作为参考图,使用ControlNet或者图生图生成类似的人像。https://github.com/antgroup/echomimic_v2/discussions/40



















 455
455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









