







一. AOBERT:用于多模态情感分析的多模态合一BERT InforFus2023
1 Abstract
1.1 Motivation
(1)多模态情绪分析利用文本、视觉和语音等各种模式来预测情绪。由于这些模态具有独特的特征,因此开发了用于融合特征的方法。
但是,不能保证整体模态特征,因为传统的融合方法有一些模态内和模态间的损失。
(2)该模型同时在两个任务上进行了预训练:多模态掩码语言建模 (MMLM) 和对齐预测 (AP)。可以使用两个预训练任务来确定模态之间的依赖性和相关性。
(1)传统的话语级:在之前的研究中,Early-Fusion LSTM (EF-LSTM) 和 Late-Fusion LSTM (LF-LSTM) 被用于输入阶段和预测阶段以融合来自不同模态的信息。然而,这些方法对于反映模态间和模态内[2]是无效的。
(2)基于注意力的:由于交叉变换器方法假设每种模态的贡献相同,因此它使用的文本信息比其他方法少;因此难以达到令人满意的性能[8]。
(3)基于门控机制的:门控机制用于调整模态贡献的比例,需要比以前的方法更多的计算[3]。因此,需要先进的方法来有效地组合来自多模态的信息。
(4)基于模态转换的:模型被训练为使用单个变压器学习两种模式。最重要的模态并不总是相同的,即使一个陈述以多种形式出现。因此,尽可能多地使用多模态信息进行情感分析是很有用的。但是,很难简单地增加模态的数量。
1.2 Method
为了解决这个问题,我们提出了 AOBERT(All-modalities-in-One BERT),这是一种单流转换器,可以处理三种模式(文本、视觉和语音)作为一个网络的输入,用于情感分析和情绪检测。
我们还介绍了使用多模态掩码语言建模生成可以反映每种模态特征的联合表示的方法(MMLM)和受 BERT [12] 启发的对齐预测(AP)。
1.3 Results
AOBERT 在 CMU-MOSI、CMU-MOSEI 和 UR-FUNNY 数据集上取得了最先进的结果。
此外,验证模态组合、MMLM 和 AP 的效果以及融合方法的消融研究证实了所 提出模型的有效性。
2. Related Work
2.1 情感分析
情感分析 [1] 是从文本中提取人们的情感或意见的任务。
传统的 NLP 方法(例如词袋)在处理长句子或专门文本时存在缺点。通过结合循环深度学习方法和微调大型语言模型,如 BERT 和 GPT-3 [13],可以克服这些问题。
最近,研究了基于方面的情感分析 (ABSA) [14] 和特定领域的情感分析 [15、16]。 ABSA 是一项复杂的任务,用于识别与文本特定方面相关的情绪。特定领域的情感分析通常应用于金融和生物医学领域。
2.2 多模态情感分析
MSA 主要侧重于整合多种资源,例如文本、视觉和语音信息,以理解人类情感。组合特征是必要的,因为它们为同一来源提供平行信息,并且对于消除情感行为的歧义很有用。以往关于 MSA 的研究通常集中在与情绪有更直接相关性的变异因素上。例如,Sentic Blending [17] 融合了模态来掌握与多模态内容相关的情绪。
通过在输入和预测阶段融合数据来进行多模态研究,例如 Early-Fusion [18] 和 Late-Fusion [19]。 Early-Fusion在输入阶段整合了各个模态的功能。但是,它可以抑制模态内的交互并导致模态具有必须存在于同一时间步长的同步问题。 Late-Fusion 将每个模态作为一个独立的模型组成,并对模型的结果应用多数表决或加权平均方法。因为每个模态都作为一个独立的网络存在,所以忽略了模态之间的相互作用。
已经进行了研究以获得联合表示来解决这些问题。 Graph-MFN [20] 使用图架构和内存使用方法来获得联合表示。 MCTN 使用分层循环翻译获得联合表示。但是,由于上述模型使用了 RNN 架构,因此存在长期依赖问题导致的信息丢失。近年来,NLP领域使用基于self-attention的transformer模型来解决长期依赖问题。为了在多模态领域采用,transformer 被用作交叉 transformer。结果,通过使用交叉变压器进一步提高了性能。例如,MTMM-ES [21] 在使用上下文模态间注意的多任务学习框架中同时预测情绪和情感。
单流转换器学习了多模式合一网络,以解决其他多模式研究中交叉转换器的问题。例如,data2vec [9] 使用基于教师强制和屏蔽方法的自我监督学习。它在各种多模态领域展示了结果。 SpeechT5 [10] 使用语音和文本作为一种输入,在众多语音领域表现良好。基于多模态 BERT 的对话系统 [11] 根据上下文生成多模态响应。
3. 模型细节
3.1 问题定义
在这项研究中,情绪分析和情绪检测是使用三种模式进行的:文本、视觉和语音。输入模态 X 定义如下:
XT∈RdT×L,XV∈RdV×L,XS∈RdS×L
X_{T} \in R^{d_{T} \times L}, X_{V} \in R^{d_{V} \times L}, X_{S} \in R^{d_{S} \times L}
XT∈RdT×L,XV∈RdV×L,XS∈RdS×L
其中 XT、XV 和 XS 分别指的是文本、视觉和语音。这些是长度为 L 的向量,维度分别为 dT、dV 和 dS。因为 L 是输入大小的固定长度,所以小于 L 的某些输入将包含零填充以适应大小。AOBERT 仅使用模态对,例如 (XT, XV)、(XT, XS),其中文本用作锚模态(anchor)。模态对定义如下:
T=(XT)V′=(XT,XV)S′=(XT,XS)
T=\left(X_{T}\right) V^{\prime}=\left(X_{T}, X_{V}\right) S^{\prime}=\left(X_{T}, X_{S}\right)
T=(XT)V′=(XT,XV)S′=(XT,XS)
其中 T、V ′ 和 S ′ 在一个训练步骤中同时处理。接下来,模态对同时进行反向传播。模型的输出包括两个结果:情感和情绪。情感 (YS) 和情绪 (YE) 基于文本标签。 YS 是 [-3, +3] 范围内的实数,YE 分为 1 或 0,表示是否出现。有关情绪和情绪输出的详细信息,请参见第 4.1 节。
3.2 总体结构
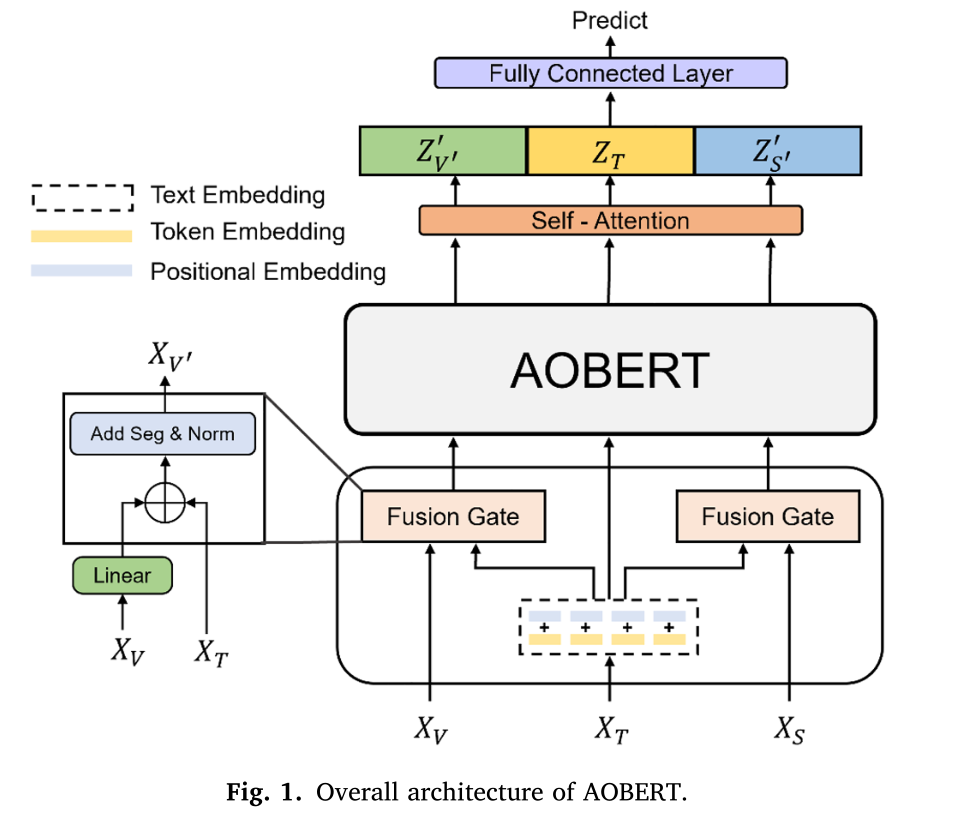
AOBERT 的总体架构如图 1 所示。所提出的模型可以分为三个部分。
第一部分是**“Joint Embedding”,它在 AOBERT 部分之前连接了 V ′ 和 S ′ 等模态对**。V ′ 和 S ′ 由 Joint Embedding 中的**“Fusion Gate”**生成。
第二部分是 AOBERT,它对文本、视觉和语音模式使用单流转换器模型。在 AOBERT 中,模型同时在两个任务上进行预训练:MMLM 和 AP。
MMLM 的灵感来自 vanilla BERT 中的 Masked Language Model (MLM),可以处理多模态数据。 AP 类似于 vanilla BERT 中的下一句预测(NSP)。
NSP 是理解句子关系的任务。同样,AP 可以通过预测多模态数据是否配对来理解模态关系。最后一部分是用于情感分析和情感检测的分类器。
3.2.1 联合嵌入
Joint Embedding 由text embedding 和Fusion Gate 组成。 Text embedding 包括 token embedding 和 positional embedding,分别将 Text XT 的单词 token 转换为实数,为 Text 提供位置信息。但是,由于 Vision XV 和 Speech XS 不具有顺序特性,因此不需要进行位置嵌入。所提出的模型使用香草 BERT的token嵌入和位置嵌入,文本嵌入的输出用作 Fusion Gate 的输入。
3.2.2 融合门
AOBERT 使用三对 T、V’ 和 S’ 作为输入。 V ′ 和 S ′ 由 Fusion Gate 生成,T 用作锚模态。首先,线性层匹配文本和其他模态之间的维度。随后,将两种不同的模态连接起来,并添加段嵌入来区分它们。最后,执行层归一化。结构如下:
A⊕B=([A;B′]+ Segment )B′=Linear(B)XV′=LN(XT⊕XV),XS′=LN(XT⊕XS)
\begin{array}{l}
A \oplus B=\left(\left[A ; B^{\prime}\right]+\text { Segment }\right) \\
B^{\prime}=\operatorname{Linear}(B) \\
X_{V^{\prime}}=L N\left(X_{T} \oplus X_{V}\right), X_{S^{\prime}}=L N\left(X_{T} \oplus X_{S}\right)
\end{array}
A⊕B=([A;B′]+ Segment )B′=Linear(B)XV′=LN(XT⊕XV),XS′=LN(XT⊕XS)
其中 A ⊕ B 定义为“融合 A 和 B”,其中 A 表示文本模态,B 表示另一种模态,例如 (1) 中的 Vision 或 Speech。由于其特点,这些模式具有不同的维度。但是,由于AOBERT将Text modality设置为anchor modality,所以其他modality的维度会根据Text而变化。具体来说,B通过式(2)中的Linear投影与A拼接。A和B’按照项[A; B‘]中的序列长度组合后,添加了段嵌入(Segment)。
Segment embedding 用于区分 token 属于 vanilla BERT 的句子。因此,它由A和B的0和1组成。同样,AOBERT使用Segment Embedding来区分模态。最后,LN 是具有正则化维度 dT 的 LayerNorm。XV’和XS’的尺寸和长度为 RT×2LR^{T \times 2 L}RT×2L。相比之下,XT 的长度为 L。
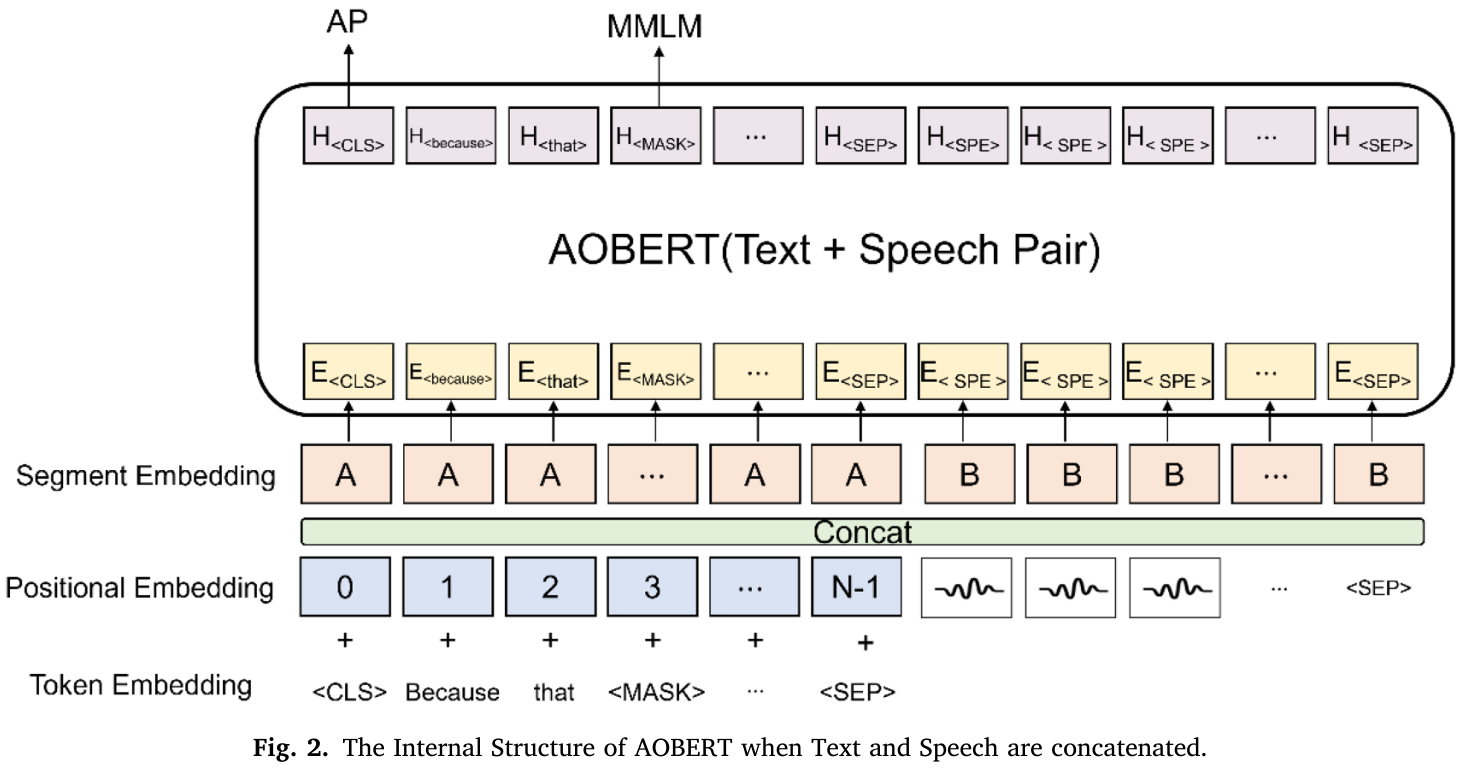
3.3 AOBert
AOBERT的内部结构如图2所示,E tokens是Joint Embedding的结果,AOBERT的输出是H token。
在 H token中,H⟨CLS⟩H_{\langle C L S\rangle}H⟨CLS⟩ 在 Pooler 处使用下游任务,Pooler 使用全连接层和 tanh 激活函数。T、V′、S′三对经过Pooler处理后,可以得到ZT、ZV′、ZS′如下:
Z{T,v′,s′}=tanh( Linear (H<CLS⟩{T,v′,s′})
Z_{\left\{T, v^{\prime}, s^{\prime}\right\}}=\tanh \left(\text { Linear }\left(H_{<C L S\rangle_{\left\{T, v^{\prime}, s^{\prime}\right\}}}\right)\right.
Z{T,v′,s′}=tanh( Linear (H<CLS⟩{T,v′,s′})
3.3.1 多模态掩码语言建模 (MMLM)
MMLM 任务类似于 BERT 中的 MLM 任务。但是,主要区别在于通过仅屏蔽文本来捕获文本与另一种模态之间的依赖关系。
预训练时,输入的token以15%的概率被随机mask,然后被随机mask1的tokens会被特殊的token[MASK]替代。具体而言,[MASK]可以为随机的token,也可以在原来的token的基础上分别以80%、10%和10%的概率保持不变。
最后,该模型经过训练,可以根据未屏蔽的文本标记和来自其他模态的其他标记来预测屏蔽的标记。
3.3.2 对齐预测(AP)
除了 MMLM 之外,我们还提出了 AP 任务,其灵感来自 BERT 中的 NSP 任务。因为 V ′ 和 S ′ 包含两种不同的模态,所以应用 AP 来理解模态之间的关系。例如,V’对中的XT和XV是从训练数据中选择的。 XV 与实际 XT 成对的概率为 50% (IsPair),而 XV 与实际 XT 不成对的概率为 50% (UnPair)。 “IsPair”和“UnPair”分别表示 1 和 0。
3.3.3 分类器和最终预测
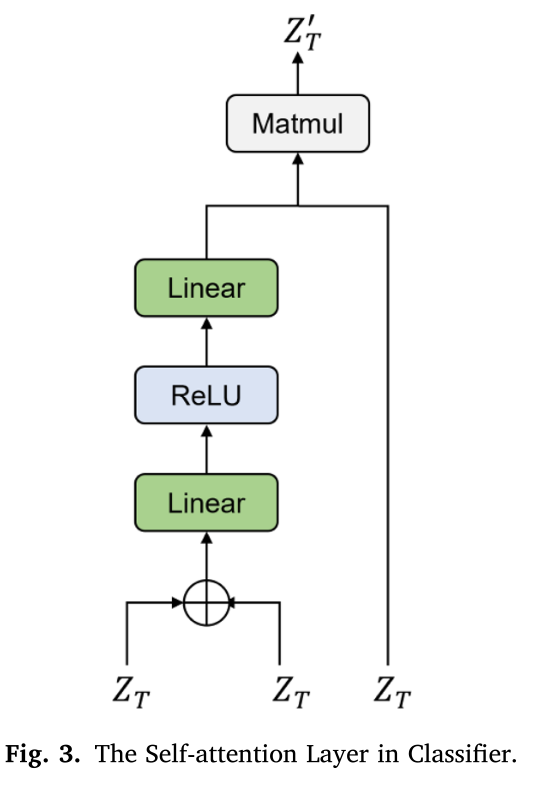
为了获得有意义的联合展示,在 ZT、ZV 和 ZS 上应用了一个自我注意层,这是从 H⟨CLS⟩H_{\langle C L S\rangle}H⟨CLS⟩ 派生的每组对。[CLS] token 仅用于分类任务。自注意力层如图 3 所示,它是 ZT 的一个例子。最后,将每对的多模态联合表示连接起来并馈送到全连接层以预测结果。使用以下公式:
ZT′= Linear (ReLU( Linear (ZT⊕ZT)))⋅ZT
Z_{T}^{\prime}=\text { Linear }\left(\operatorname{ReLU}\left(\text { Linear }\left(Z_{T} \oplus Z_{T}\right)\right)\right) \cdot Z_{T}
ZT′= Linear (ReLU( Linear (ZT⊕ZT)))⋅ZT
3.4 损失函数
情感分析和情感检测使用不同的损失函数,它们由 Ljoint 和 Ltask 的总和组成。 Ljoint是指联合损失函数,包括MMLM和AP预训练任务。 MMLM 和 AP 任务使用 CrossEntropy 损失函数,分别表示为 LMMLM 和 LAP。 Ljoint 计算如下:
Ljoint =LMMLM+LAP
L_{\text {joint }}=L_{M M L M}+L_{A P}
Ljoint =LMMLM+LAP
因为 Ljoint 是三对计算的,所以有 LT、LV′ 和 LS′ 三种类型。此外,LT 没有 LAP。最终损失计算为 Ltask 与三个联合损失的平均值之和。模型的整体学习是通过最小化 (7) 来执行的。
L=Ltask +(LT+LV′+LS′)3
L=L_{\text {task }}+\frac{\left(L_{T}+L_{V^{\prime}}+L_{S^{\prime}}\right)}{3}
L=Ltask +3(LT+LV′+LS′)
Ltask 是依赖于任务的损失。由于情绪分析是一项回归任务,Ltask 使用均方误差 (MSE) 损失函数。相比之下,CrossEntropy 损失函数用于情绪和幽默检测。
Ltask =−1N∑i=0N−1yi⋅logy^i=1N∑i=0N−1∥yi−y^i∥22
L_{\text {task }}=-\frac{1}{N} \sum_{i=0}^{N-1} y_{i} \cdot \log \widehat{y}_{i}=\frac{1}{N} \sum_{i=0}^{N-1}\left\|y_{i}-\widehat{y}_{i}\right\|_{2}^{2}
Ltask =−N1i=0∑N−1yi⋅logyi=N1i=0∑N−1∥yi−yi∥22
4. 结果

5. 自己的思考
可以使用diffusion模型也做一个AGI替代这个AOBERT



















 3528
3528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









