




现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
现在牛牛想知道这个数据集中第10行到第20行的用户的常用语言分别是什么,请你帮他输出一下。
输入描述:
数据集直接从当前目录下的Nowcoder.csv文件中读取。

输出描述:
输出该数据集第10行到第20行的常用语言,每行数据单独成行,如下所示:
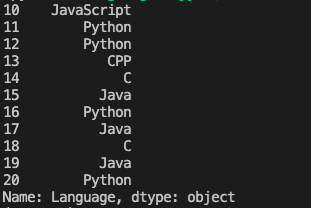
本题涉及pandas基础应用。我们可以通过属性值直接获取对应的数据列,就像例中的df.Language,注意区分大小写,而且无需引号。获取的列数据依然可以看作是DataFrame数据,可以使用loc获取对应的行数据。
import pandas as pd
df=pd.read_csv('Nowcoder.csv')
print(df.Language.loc[10:20])

















 133
133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









