







 这篇博客深入讲解了MySQL数据库的基础知识,包括数据库定义、分类,重点介绍了SQL的DDL(数据定义语言)、DML(数据操作语言)、DQL(数据查询语言)和DCL(数据控制语言)。详细阐述了如何创建、删除和管理数据库与表,以及如何执行插入、更新和删除操作。此外,还讨论了事务的概念、特性以及在MySQL和Java中的事务管理。
这篇博客深入讲解了MySQL数据库的基础知识,包括数据库定义、分类,重点介绍了SQL的DDL(数据定义语言)、DML(数据操作语言)、DQL(数据查询语言)和DCL(数据控制语言)。详细阐述了如何创建、删除和管理数据库与表,以及如何执行插入、更新和删除操作。此外,还讨论了事务的概念、特性以及在MySQL和Java中的事务管理。
1.数据库定义:
本质上就是一个文件系统.通过标准的sql对数据进行curd操作,数据库管理系统大白话就是一个软件
2.数据库分类:
关系型数据库:
存放实体与实体之间的关系的数据库(就是二维表)
实体:
用户 订单 商品
关系:
用户拥有订单
订单包含商品
非关系型数据库:存放的是对象(redis) NO-sql(not only sql)
软件名 厂商 特点
mysql oracle 开源的数据库
oracle oracle 大型的收费的数据库
DB2 IBM 大型的收费的数据库
sqlserver 微软 中大型的收费的数据库
sybase sybase(powerdesigner)
3.SQL:
1.概念: 结构化查询语句
2.作用: 管理数据库.3.sql的分类:
DDL:数据定义语言
操作对象:数据库和表
关键词:create alter drop
DML:数据操作语言
操作对象:记录
DQL:数据查询语言(非官方)
DCL:数据控制语言
操作对象:用户 事务 权限
4.登录数据库
登录数据库:
mysql -uroot -p密码(root)我这里设置的额

5.DDL:数据定义语言(对数据库和表)
主要关键词:create alter drop
数据库:
1.创建数据库:
create database database12.删除数据库:
drop database database13.查看所有数据库表:
show databases;表:
1.创建表:
create table user ( id int primary key auto_increment, username varchar(20) );2.修改表名:
alter table user1 rename to user2;3.添加字段:
alter table user add password varchar(20);4.修改字段名:
alter table user change password pwd varchar(20);5.修改字段描述:
alter table user modify pwd int;6.删除表:
drop table user常用命令:
切换或者进入数据库: use 数据库名称;
查看当前数据库下所有表: show tables;
查看表结构:desc 表名;
查看建表语句:show create table 表名;
6.DML:数据操作语言(记录行)
主要关键词:insert update delete
1.插入
方式1 insert into 表名(字段名,字段名1...) values(字段值,字段值1...); eg: insert into user (username,id) values('jack',100); 方拾2 insert into 表名 values(字段值1,字段值2...,字段值n); eg: insert into user values(1,'tom'); 注意:对方式2 默认插入全部字段, 必须保证values后面的内容的类型和顺序和表结构中的一致 若字段类型为数字,可以省略引号2.修改:
update user set username='jerry' where username='jack';3.删除:
delete from user where id = '1';
7.DQL:数据查询语言
主要关键词:select
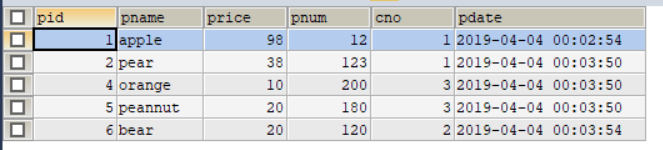
格式: select ... from 表名 where 条件 group by 分组字段 having 条件 order by 排序字段 ase|desceg:现在有一张products表格
基本查询
1.查询商品名和商品价格
select pname,price from products;2.查询所有商品都有那些价格.
-- 去重操作 distinct -- 格式: select distinct 字段名,字段名2 from 表名 select price from products; select distinct price from products;
3.将所有商品的价格+10元进行显示.(别名),但不改变在数据库中的值
select price+10 from products;
select price+10 'newprice' from products; 注意引号必须加
条件查询
1查询商品名称为apple的商品所有信息
select * from products where pname = 'apple';2..查询商品价格>60元的所有的商品信息
select * from product where price>60;3.查询商品名称中包含”e”的商品
-- 模糊匹配
-- 格式: 字段名 like "匹配规则";
-- 匹配内容 %
"龙" 值为龙
"%龙" 值以"龙"结尾
"龙%" 值以"龙"开头
"%龙%" 值包含"龙"
-- 匹配个数 "__" 占两个位置select * from products where pname like "%e%";
4.查询价格为38,68,98的商品
两种方式 select * from products where price = 38 or price = 68 or price=98; select * from products where price in(38,68,98);5.注意:
where后的条件写法:
* > ,<,=,>=,<=,<>(不等于),!=
* like 使用占位符 _ 和 % _代表一个字符 %代表任意个字符.
* select * from product where pname like '%新%';
* in在某个范围中获得值.
* select * from product where pid in (2,5,8);
* between 较小值 and 较大值
select * from products where price between 50 and 70;
高级查询
排序查询:
1.查询所有的商品按价格进行排序.(asc-升序,desc-降序)
select * from products order by price desc;2.查询名称有 e 的商品的信息并且按价格降序排序.
select * from products where pname like '%e%' order by price desc;聚合函数:
******* sum(),avg(),max(),min(),count();
1.获得所有商品的价格的总和:
select sum(price) from products;2.获得商品表中价格的平均数:
-- round(值,保留小数位)
select round(avg(price),2) from products;3.获得商品表中有多少条记录
select count(*) from products;分组:使用group by
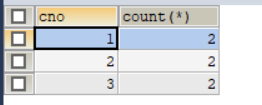
1.根据cno字段分组,分组后统计商品的个数.
select cno,count(*) from products group by cno;
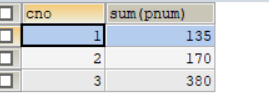
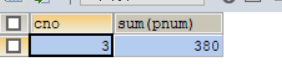
2.根据cno分组,分组统计每组商品的总数量,并且总数量> 200;
select cno,sum(pnum) from products group by cno;
select cno,sum(pnum) from products group by cno having sum(pnum)>200;
注意:
where和having区别:
1.where 是对分组前的数据进行过滤 having 是对分组后的数据进行过滤
2.where 后面不能使用聚合函数,having可以




8.数据类型:(了解)
java mysql
byte tinyint
short smallint
int int(★)
long bigint
char/String varchar(★)|charvarchar:可变长度 mysql的方言 varchar(20): 存放abc 只会占用三个
char:固定长度 char(20) 存放abc 占用20个
boolean tinyint|int 代替
float|double float|double
注意:
double(5,2):该小数长度为5个,小数占2个 最大值:999.99
java.sql.Date date 日期
java.sql.Time time 时间
java.sql.Timestamp timestamp(★) 时间戳 若给定值为null,数据库会把当前的系统时间存放到数据库中
datetime(★) 日期+时间(java中是没有的)date中
java.lang.date是父->java.util.date->java.sql.date(子)
java.sql.Clob(长文本) mysql的方言(text)
java.sql.Blob(二进制) blob
9.约束
1.作用:
为了保证数据的有效性和完整性2.mysql中常用的约束:主键约束(primary key) 唯一约束(unique) 非空约束(not null) 外键约束(foreign key)
主键约束:
被修饰过的字段唯一非空
注意:一张表只能有一个主键,这个主键可以包含多个字段方式1:建表的同时添加约束 格式: 字段名称 字段类型 primary key
方式2:建表的同时在约束区域添加约束
所有的字段声明完成之后,就是约束区域了create table pk01( id int, username varchar(20), primary key (id) );方式3:建表之后,通过修改表结构添加约束
create table pk02( id int, username varchar(20) ); //alter table pk02 add primary key(字段名1,字段名2..); alter table pk02 add primary key(id,username);//联合主键,只有两者同时不一样才有效
唯一约束:(了解)
被修饰过的字段唯一,对null不起作用 方式的和上类似
方式1:建表的同时添加约束 格式: 字段名称 字段类型 unique方式2:建表的同时在约束区域添加约束
方式3:建表之后,通过修改表结构添加约束
eg:
create table un( id int unique, username varchar(20) unique );insert into un value(10,'tom');-- 成功insert into un value(10,'jack');-- 错误 Duplicate entry '10' for key 'id'
非空约束(了解)
特点:被修饰过的字段非空
方式:
create table nn( id int not null, username varchar(20) not null );
10.truncate的使用
格式:
truncate 表名; 干掉表,重新创建一张空表
和delete from 区别:
delete属于DML语句 truncate属于DDL语句
delete逐条删除 truncate干掉表,重新创建一张空表1.创建一个user表
create table user( id int primary key auto_increment, username varchar(20) );2.插入数据
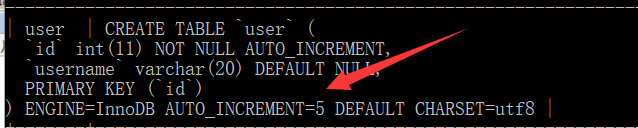
insert into user values(1,"jianqi"); insert into user values(4,"tom");3.显示建表语句
show create table user
你会发现里面的自增=5
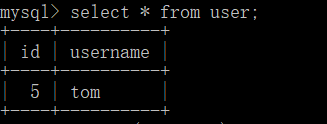
4.删除user delete方式
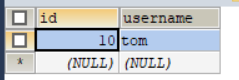
在往里面插入数据 null ,tom
insert into user values(null,"tom");
此时的id不是从1开始的,直接为5,所以delete只是删除了数据,没有删除整个表
auto_increment 自增
要求:
1.被修饰的字段类型支持自增. 一般int
2.被修饰的字段必须是一个key 一般是primary key
11.实体:
网上商城的实体:
用户 订单 商品 分类
常见关系:
一对多. 用户和订单 分类和商品
多对多. 订单和商品 学生和课程
一对一. 丈夫和妻子
ER图可以描述实体于实体之间的关系
实体用矩形表示
属性用椭圆表示
关系用菱形表示举例1:
关系:1-----》多
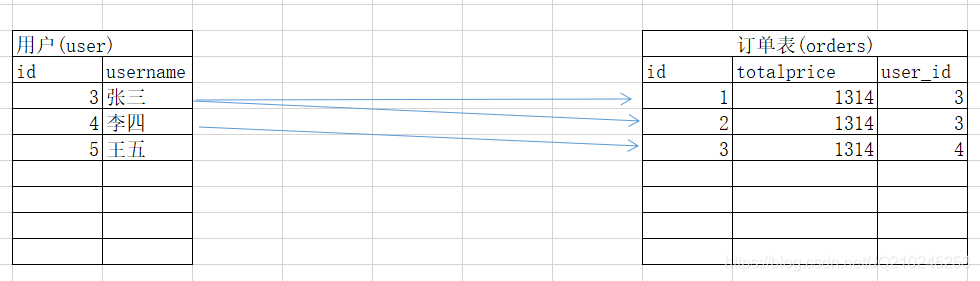
1.创建两张表,一个用户,一个订单
一般像这种的用户是主表,订单是从表
-- 创建用户表 create table user( id int primary key auto_increment, username varchar(20) ); -- 创建订单表 create table orders( id int primary key auto_increment, totalprice double, user_id int );
2.情景模拟:
在没有加外键的时候,加入删除uer表中的数据,但是此时订单中不会有影响,就会造成有些数据称为垃圾值
删除user中的李四时,orders中的user_id就会变成垃圾值
所以:为了保证数据的有效性和完整性,添加约束(外键约束).
在多表的一方添加外键约束
格式:
alter table 多表名称 add foreign key(外键名称) references 一表名称(主键);alter table orders add foreign key(user_id) references user(id);3.添加了外键约束之后有如下特点:★
1.主表中不能删除从表中已引用的数据
2.从表中不能添加主表中不存在的数据4.开发中处理一对多:★
在多表中添加一个外键,名称一般为主表的名称_id,字段类型一般和主表的主键的类型保持一致,
为了保证数据的有效性和完整性,在多表的外键上添加外键约束即可.
举例2:
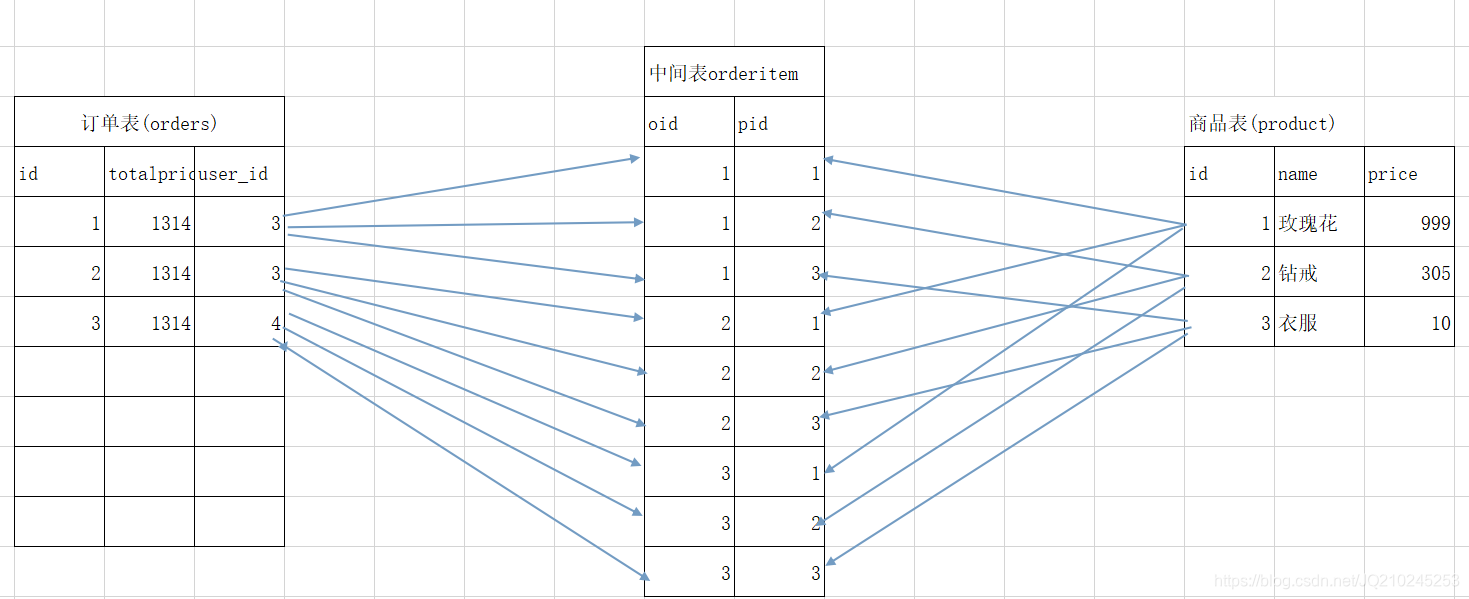
关系:多----》多
1.创建订单表和中间表
create table product( id int primary key auto_increment, name varchar(20), price double ); -- 创建中间表 create table orderitem( oid int, pid int );
关系如下:
开发中处理多对多:★
引入一张中间表,存放两张表的主键,一般会将这两个字段设置为联合主键,这样就可以将多对多的关系拆分
成两个一对多了
为了保证数据的有效性和完整性
需要在中间表上添加两个外键约束即可.如下所示:
-- 添加外键约束 alter table orderitem add foreign key(oid) references orders(id); alter table orderitem add foreign key(pid) references product(id);
12.多表查询
1.笛卡尔积:了解
多张表无条件的联合查询.没有任何意思
select a.*,b.* from a,b;2.内连接:★
格式1:显式的内连接 推荐 select a.*,b.* from a [inner]可省略 join b on ab的连接条件 格式2:隐式的内连接 select a.*,b.* from a,b where ab的连接条件
创建的user表
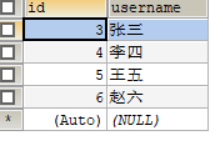
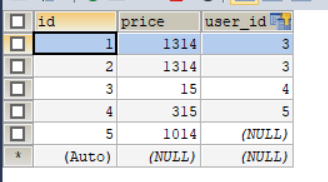
创建的orders表
//给订单表添加外键约束 ALTER TABLE orders ADD CONSTRAINT user_fk FOREIGN KEY (user_id) REFERENCES USER(id);查询用户的订单,没有订单的用户不显示:
隐式内连接: select user.*,orders.* from user ,orders where user.id=orders.user_id; 显示内连接: select user.*,orders.* from user join orders on user.id=orders.user_id;3 .外连接:★
左外连接:★ select a.*,b.* from a left [outer] join b on 连接条件; 意思: 先展示join左边的(a)表的所有数据,根据条件关联查询 join右边的表(b),符合条件则展示出来,不符合以null值展示. 右外连接: select a.*,b.* from b right [outer] join a on 连接条件; 意思: 先展示join右边的表(a)表的所有数据,根据条件关联查询join左边的表(b),符合条件则展示出来,不符合以null值展示.查询所有用户的订单详情
左外连接: user在左 select user.*,orders.* from user left join orders on user.id=orders.user_id;
13.子查询
一个查询依赖另一个查询
查看用户为张三的订单详情
1.先查询张三的id
select id from User where username = '张三';// 3
2.select * from orders where user_id = ?;
两个合二为一
select * from orders where user_id = (select id from User where username = '张三');
查询出订单的价格大于300的所有用户信息。
1.先查询出订单价格>300的用户的id
select user_id from orders where price >300;//(3,3,5,null)
2.select * from user where id in(3,3,5,null);
两个合二为一: select * from user where id in(select user_id from orders where price >300);
查询订单价格大于300的订单信息及相关用户的信息。
内连接:
select orders.*,user.* from orders,user where user.id=orders.user_id and orders.price>300 ;
子查询: 是将一个查询的结果作为一张临时表
select user.*,tmp.* from user,(select * from orders where price>300) as tmp where user.id=tmp.user_id;
给表起别名
格式: 表 [as] 别名
DCL:用户 权限 事务
1.事务的概念:
就是一件完整的事情,包含多个操作单元,这些操作要么全部成功,要么全部失败.
例如;转账:包含转出操作和转入操作.
2.事务的特性:
ACID
原子性:事务里面的操作单元不可切割,要么全部成功,要么全部失败
一致性:事务执行前后,业务状态和其他业务状态保持一致.
eg:转账的话前后总的钱数是一定的
隔离性:一个事务执行的时候最好不要受到其他事务的影响
持久性:一旦事务提交或者回滚.这个状态都要持久化到数据库中
3.不考虑隔离性会出现的读问题★★
脏读:在一个事务中读取到另一个事务没有提交的数据
不可重复读:在一个事务中,两次查询的结果不一致(针对的update操作)
虚读(幻读):在一个事务中,两次查询的结果不一致(针对的insert操作)
- 通过设置数据库的隔离级别来避免上面的问题(理解)
- read uncommitted 读未提交 上面的三个问题都会出现
- read committed 读已提交 可以避免脏读的发生
- repeatable read 可重复读 可以避免脏读和不可重复读的发生
- serializable 串行化 可以避免所有的问题
4.mysql中的事务:
mysql中事务默认是自动提交,一条sql语句就是一个事务.
开启手动事务方式
方式1:关闭自动事务.(了解)
set autocommit = off;
方式2:手动开启一个事务.(理解)
1start transaction;-- 开启一个事务
2commit;-- 事务提交
3rollback;-- 事务回滚
扩展:
oracle中事务默认是手动的,必须手动提交才可以.
场景模拟:为什么要用事务?
例如:创建一个数据库和表
create database day08;
use day08;
create table account(
name varchar(20),
money int
);
insert into account values('aa','1000');
insert into account values('bb','1000');
完成 aa给bb转500;
update account set money = money - 500 where name='aa';
update account set money = money + 500 where name='bb';
但是用此操作另外一个用户没有加钱,如果断电怎么办,就没有办法,所以用到事务解决办法:
1.开启事务之后
2.完成上面转账操作,
3.在提交事务才可以完成转账代码演示:
start transaction;
update account set money = money - 500 where name='aa';
update account set money = money + 500 where name='bb';commit;
才可以完成转账操作
5. java中的事务:
Connection接口的api:★★★★★★★★
1.setAutoCommit(false);//手动开启事务,注意false才是说动开启,true的话是自动。
2.commit():事务提交
3.rollback():事务回滚
扩展:了解 Savepoint还原点
void rollback(Savepoint savepoint) :还原到那个还原点
Savepoint setSavepoint() :设置还原点
6.事务总结:
6.1事务的特性:★★★ ACID
原子性:事务里面的操作单元不可切割,要么全部成功,要么全部失败
一致性:事务执行前后,业务状态和其他业务状态保持一致.
eg:转账的话前后总的钱数是一定的
隔离性:一个事务执行的时候最好不要受到其他事务的影响
持久性:一旦事务提交或者回滚.这个状态都要持久化到数据库中
6.2 不考虑隔离性会出现的读问题★★
1.脏读:在一个事务中读取到另一个事务没有提交的数据
2.不可重复读:在一个事务中,两次查询的结果不一致(针对的update操作)
3.虚读(幻读):在一个事务中,两次查询的结果不一致(针对的insert操作)
通过设置数据库的隔离级别来避免上面的问题(理解)
read uncommitted 读未提交 上面的三个问题都会出现
read committed 读已提交 可以避免脏读的发生
repeatable read 可重复读 可以避免脏读和不可重复读的发生
serializable 串行化 可以避免所有的问题
了解
演示脏读的发生:
将数据库的隔离级别设置成 读未提交
set session transaction isolation level read uncommitted;
查看数据库的隔离级别
select @@tx_isolation;
避免脏读的发生,将隔离级别设置成 读已提交
set session transaction isolation level read committed;
不可避免不可重复读的发生.
避免不可重复读的发生 经隔离级别设置成 可重复读
set session transaction isolation level repeatable read;
演示串行化 可以避免所有的问题
set session transaction isolation level serializable;
相当于锁表的操作.只有转账方提交事务后这边才可以收到钱
四种隔离级别的效率
read uncommitted>read committed>repeatable read>serializable
四种隔离级别的安全性
read uncommitted<read committed<repeatable read<serializable
开发中绝对不允许脏读发生.
mysql中默认级别:repeatable read
oracle中默认级别:read committed
java中控制隔离级别:(了解)
Connection的api
void setTransactionIsolation(int level)
level是常量


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









