




 本文介绍了神经网络语言模型,包括NNLM和RNNLM,探讨了它们在克服统计语言模型缺点上的作用。此外,还详细阐述了词向量的不同表示方法,如One-hot、词袋模型、TF-IDF到分布式表示,并重点讨论了词向量工具word2vec中的CBOW和Skip-gram模型。最后,提到了词向量在各种自然语言处理任务中的应用和选择模型的建议。
本文介绍了神经网络语言模型,包括NNLM和RNNLM,探讨了它们在克服统计语言模型缺点上的作用。此外,还详细阐述了词向量的不同表示方法,如One-hot、词袋模型、TF-IDF到分布式表示,并重点讨论了词向量工具word2vec中的CBOW和Skip-gram模型。最后,提到了词向量在各种自然语言处理任务中的应用和选择模型的建议。
神经网络语言模型
用句子SSS的概率p(S)p(S)p(S)来定量刻画句子。
统计语言模型是利用概率统计方法来学习参数p(wi∣w1…wi−1)p(w_i|w_1\dots w_{i-1})p(wi∣w1…wi−1),神经网络语言模型则通过神经网络学习参数.
统计语言模型的缺点
- 平滑技术错综复杂且需要回退至低阶,使得该模型无法面向更大的n元文法获取更多的词信息.
- 基于最大似然估计的语言模型缺少对上下文的泛化,如观察到蓝汽车和红汽车不会影响出现黑汽车的概率.
神经网络语言模型
根据所用的神经网络不同,可以分为
- NNLM模型(DNN)
- RNNLM模型(RNN)
NNLM
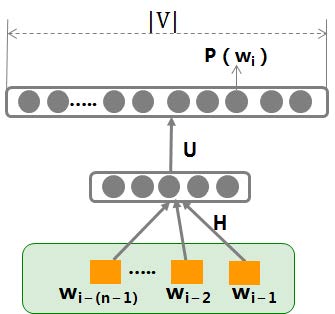
输入:X:wi−1X:w_{i-1}X:wi−1
输出:p(wi∣wi−1)p(w_i|w_{i-1})p(wi∣wi−1)
参数:θ=H,U,b1,b2\theta = {H,U,b^1,b^2}θ=H,U,b1,b2
运算关系:
p(wi∣wi−1)=exp(y(wi))∑k=1∣V∣exp(y(vk))y(wi)=b2+U(tanh(XH+b1))p(w_i|w_{i-1}) = \frac{\exp(y(w_i))}{\sum_{k=1}^{|V|}\exp(y(v_k))}\\ y(w_i) = b^2 + U(\tanh(XH+b^1)) p(wi∣wi−1)=∑k=1∣V∣exp(y(vk))exp(y(wi))y(wi)=b2+U(tanh(XH+b1))
目标函数:
采用log损失L(Y,P(Y∣X))=−logP(Y∣X)L(Y,P(Y|X)) = - \log P(Y|X)L(Y,P(Y∣X))=−log
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1063
1063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









