






目录
Ollama 是一款开创性的人工智能(AI)和机器学习(ML)工具平台,它极大的简化了AI模型的开发和使用过程,Ollama出现的目的是为了解决AI模型的硬件配置和环境搭建的复杂问题:该工具的主要特点包括:(1)功能丰富,使用直观且高效。(2)对用户比较友好,上手无门槛。(3)推动AI普及,扩展AI能力。此外Ollama还会存在一系列的关键优势,它能自动识别并充分利用Windows系统中最优的硬件资源,可以实现针对性能优化,从而确保AI模型更加高效地运行;Ollama 的常驻 API可以和项目无缝对接,而无需额外的复杂设置。在AI开发的过程中,简化了整个硬件流程,降低了诸多技术门槛;接入了比较完整的Ollama模型库,可以提供诸多的进军的“武器”,“武器1”提供文本分析、“武器2”提供图像处理能力,“武器2”提供图像处理能力。“武器3”提供其他AI任务。其主要包含的模型库如下表。详细见library (ollama.com)
| 模型 | 默认参数 | 大小 | 安装命令 | 发布组织 |
| Llama 3.1 | 8B | 4.7GB | ollama run llama3.1 | Meta |
| Gemma 2 | 9B | 5.4GB | ollama run gemma2 | |
| Qwen2 | 7B | 4.4GB | ollama run qwen2 | 阿里巴巴 |
| Mistral | 7B | 4.1GB | ollama run mistral | Mistral AI |
| Phi-3 | 3.8B | 2.2GB | ollama run phi3 | 微软Research |
| LLaVA | 7B | 4.7GB | ollama run llava | 微软Research |
| Command R | 35B | 20GB | ollama run command-r | Cohere |
注明:运行默认参数的模型,其所在服务机必须大于他的默认参数,如7B至少需要8GB的显存
1.Ollama的安装与命令行使用
1.1安装
通过访问Download Ollama on Windows链接,下载OllamaSetup.exe的安装程序,双击安装程序,点击弹出的Install开始安装,等待一段时间后,便可完成安装。安装完成后出现如下图的图标便可使用。在Windows下安装相对比较简单。
1.2软件使用与模型安装
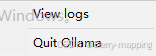
使用的流程是:右键以管理员的身份打开,任务栏会显示对应的图标,点击图标选择View log打开命令行窗口。
然后通过执行命令安装各种模型,安装命令模板为ollama run [modelname],如安装llama3.1则运行ollama run llama3.1便可安装成自己用的模型,具体模型类型如上表单所列,亦或去模型库去找自己想要安装的模型。

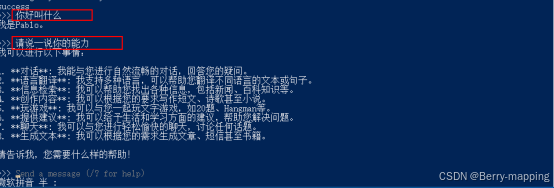
当安装完成后,出现success则表示安装成功,接一下就可以在send a message进行对话了,下一次进入到场景则还是运行同样的命令如ollama run llama3.1便可进行对话。如果想要处理图像的模型,如LLaVA 1.6,则需要ollama run llaval 即可,在对话中输入图像的绝对路径即可,如”D:\GeniusWorld_jhz\AboutProjectText(相关项目文档)\人工智能合集\Ollama大模型管理\70bd98270376.png”根据选择模型的不同来分析这张图片,并提供一些结果,例如图片的内容和分类,以及图片是否经过修改等其他分析。
2.连接到llama API
在正常的应用下,需要将目标应用程序连接到Ollama API中,这样就可以把模型功能整合到自己的软件中,用于相应的功能开发。
2.1环境的配置
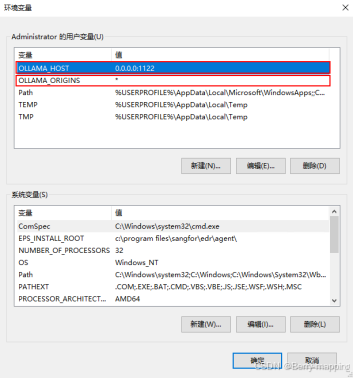
Ollama API 的默认地址为http://localhost:11434,可以在安装Ollama的系统中直接调用,但是如果在其他项目中调用就会存在跨域问题,因此这里可以针对API 的侦听地址和端口修改环境变量,在修改变量前需要退出Ollama,点击任务栏图标,选择Quit Ollama退出后台,这里如果没有退出,修改完之后没有图标了(不知道是不是这个引起的问题),添加更改侦听地址和端口,添加以下环境变量:变量名:OLLAMA_HOST,变量值(端口):0.0.0.0:1122,添加Ollama跨域配置的环境变量:变量名:OLLAMA_ORIGINS,变量值:*,具体配置如下图所示:
设置完环境变量后,需要重启电脑,配置才会生效,输入http://localhost:1122出现如下图所示的内容。则更改配置成功,用这个地址也可以在外部网站进行访问。

2.2API的调用(postman和前端)
使用postman进行调用,通过POST请求路径为:http://localhost:1122/api/generate。JSON传入值为:
{
"model":"llama3.1",
"prompt":"你好,你可以换个名字嘛",
}返回的数据是下面格式:每一个token单独返回,不利于开发。
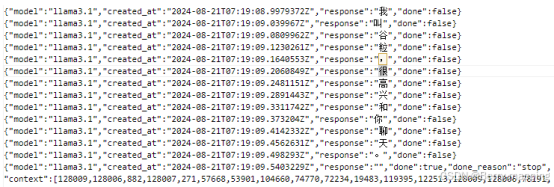
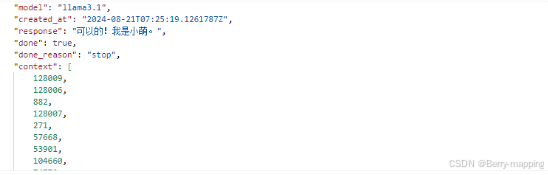
所以要在JSON传入时加入"stream":false 的参数,加入这个值后,传入的值如下:
{
"model":"llama3.1",
"prompt":"你好,你可以换个名字嘛",
"stream":false
}
在前端请求调用时用
let inputValue = "";
inputValue = this.textarea;
const data = {
"model":"llama3.1",
"prompt": inputValue,
"stream":false
};
try {
const response = await this.$axios.post('http://172.30.81.221:1122/api/generate', data);
console.log(response.data);
const mes = response.data["response"];
console.log(mes);
alert(mes);
// console.log(this.textarea)
// 在这里处理返回的数据,根据实际情况进行操作
} catch (error) {
console.error(error);
}3.使用LLaMA-Factory微调模型
3.1搭建相应的环境
3.1.1硬件准备
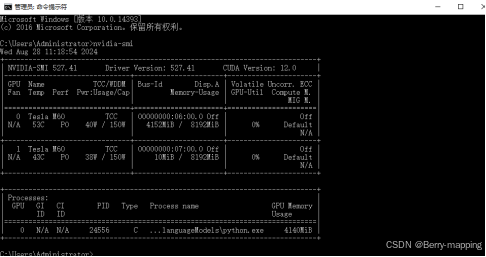
一台操作系统Windows/Linux(本人用的Windows Sever2016)。显卡为Tesla M60(*2)显存为单卡8GB,内存一般为2倍的总显存。具体信息如图:
3.1.2安装CUDA
CUDA根据显卡类型安装对应的版本号,Windows Sever2016CUDA的版本号为12.0;cuDNN(与CUDA版本对应);具体安装详见:
win10+Anaconda+pytorch+CUDA11.1 详细安装指南_pytorch cuda11.1百度网盘-优快云博客 这里有详细的教程,包含安装下载CUDA、cuDNN、环境变量的配置。
3.1.3安装Anaconda3
Anaconda3的官网为https://www.anaconda.com/,特别说明:如果是Windows Server2016需要较低版本的,2024年最新的版本会缺少某个库,可以用2022年的Anaconda。其他版本的网址通过https://repo.anaconda.com/archive/这个链接进行下载。安装点击next即可。
3.1.4在虚拟环境中安装PyTorch CUDA版
打开新安装的Anaconda下的工具点击Anaconda Prompt,新建一个python虚拟环境,conda create -n your_name python=3.11 ,激活activate your_name。
依次输入命令(3条):
conda config --add channels Index of /anaconda/pkgs/free/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --set show_channel_urls yes;这个命令是为下载源(清华源)做准备的
安装pytorch,pytorch官网没有对应的CUDA=12.0的Pytorch,这个显卡的小伙伴可以使用CUDA=11.8,
,官网的安装命令为pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118(注明:此处在LLaMA-Factory使用的时候会保错RuntimeError:use_libuv was requested but PyTorch was build without libuv support),查询了很多资料发现是因为pytorch版本的问题,使用上述安装命令安装的Pytorch的版本为torch=2.4.0,目前支持这个库的pytorch版本为torch=2.3.X,pip install torch==2.3.0 torchvision==0.18.0 torchaudio==2.3.0 --index-url https://download.pytorch.org/whl/cu118,通过上述文章可以安装torch=2.3.0(官网上的不好用,安装命令。仅针对目前使用的这台机器),问题解决的源资料路径为通过上述文章可以安装torch=2.3.0(官网上的不好用,安装命令。仅针对目前使用的这台机器),问题解决的源资料路径为:https://github.com/RVC-Boss/GPT-SoVITS/issues/1357。
安装完之后验证安装:命令依次是:
(1)python(2)import torch(3)torch.cuda.is_available(),如果第三条命令运行完显示结果为true,则表示安装成功。特别说明:import torch时会报错,解决 python出现的[WinError 126] 找不到指定的模块。fbgemm.dll“ or one of its dependencies.
遇到这个问题需要下载个libomp140.x86_64.dll : Free .DLL download. (dllme.com),然后将libomp140.x86_64.dll复制到 \python路径下\Lib\site-packages\torch\lib。
3.1.5安装pycharm
安装地址:https://www.jetbrains.com/pycharm/download/other.html,可以通过这个链接安装不同版本的Pycharm。安装过程按照相应的教程即可。
3.2LLaMA-Factory工具包的下载及其使用
3.2.1工具包的安装
下载地址https://github.com/hiyouga/LLaMA-Factory,安装相应的依赖项pip install -r requirments.txt,按照这安装完会报错(llamafactory-cli’ 不是内部或外部命令,也不是可运行的程序 或批处理文,解决方案:pip install -e .[metrics]),然后启动webui(python src/webui.py或者llamafactory-cli webui),然后会自然跳到训练设置界面:
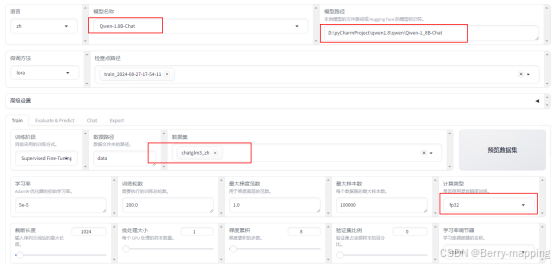
https://github.com/RVC-Boss/GPT-SoVITS/issues/1357。上述界面可以按照自定义设置,其中数据集部分需要自己自定义数据集格式,目前支持的数据集格式为目前我们支持 Alpaca 格式和 ShareGPT 格式的数据集。具体可以看数据处理 - LLaMA Factory。
微调一般使用 Alpaca 格式,其格式具体为:

其中instruction 列对应的内容为人类指令, input 列对应的内容为人类输入, output 列对应的内容为模型回答。将这一文件保存为chat_zh,json,然后需要在dataset_info中注册一下。

至此,准备工作已经完成。
3.2.2模型的微调
进入训练界面之前需要设置显卡数量:set CUDA_VISIBLE_DEVICES=0,,这样设置就是启动第一块显卡,如果有二三个显卡则设置为0,1,2(注意:如果不设置,默认使用多个显卡,不设置分布训练的话torch.distributed.DistNetworkError会报客户端请求超时900s)。启动webui,按照自定义设置就好,此外,模型的路径要下载到本地才能用。一般提供
![]()
一般是通过安装modelscope(pip install -i https://pypi.tuna.tsinghua.edu.cn/simple modelscope),进行安装,安装完直接运行就可以把模型下载到本地,模型一般都会比较大,需要下载到空间比较充足的位置。地址示例可以为:qwen/Qwen-7B-Chat-Int4。其中模型中的7B,1.8B代表模型的参数量,7B大约为70亿的参数量,同理1.8B大约为18亿的参数量,需要显存的话至少需要16GB。注意:显存不够的话会直接报CUDA内存溢满等问题,无法继续训练。按照单机单卡进行训练的流程如下:
(1)训练阶段
按照Train设置数据路径,数据集,并且可以预览数据集,设置学习率、训练轮数、以及批量的大小,根据实际情况以及硬件配置进行设置。具体参数说明见https://blog.youkuaiyun.com/m0_69655483/article/details/138229566。
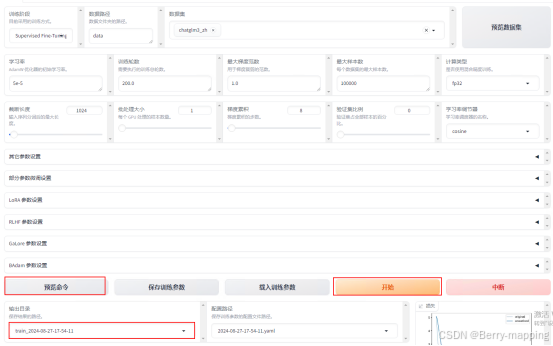
完成配置点击预览命令,点击开始开始训练。
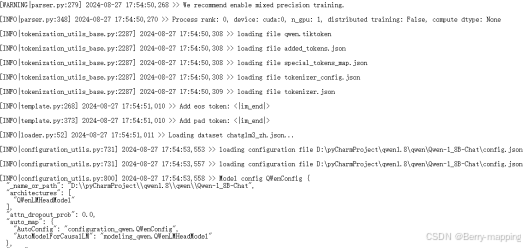
训练完成后,在LLaMa-Factory/saves找到对应的保存路径。
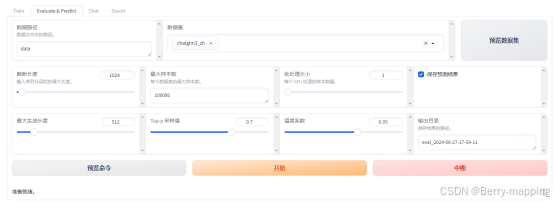
(2)模型的预测和评估
选择验证集和数据集,完成模型的评估,数据选择验证数据集和预览数据集。
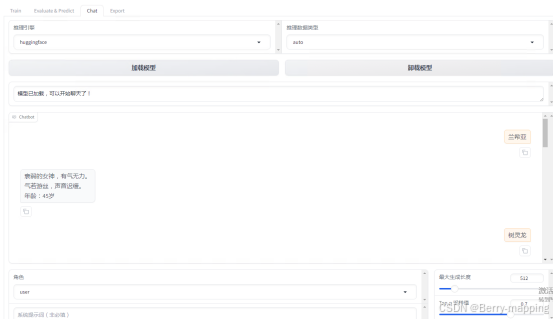
(3)Chat测试阶段
在检查点设置刚刚生成的模型,推理模型按照图中的配置完成模型的聊天,点击加载模型。等模型加载完成之后。便可使用对话。
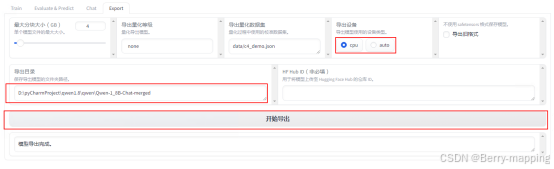
(1)模型导出阶段
设置模型的导出目录以及模型的导出设备,点击开始导出生成对应的名称。
导出的模型结构如下图:
3.2.3模型导入到ollama中
需要下载llama.cpp文件包,同样经过git clone https://github.com/ggerganov/llama.cpp.git, 将这个文件克隆到本地,通过pip install -r requirements.txt。安装对应的依赖包,此外还需要执行cd gguf-py ,pip install --editable 执行命令python convert_hf_to_gguf.py "D:\pyCharmProject\qwen1.8\qwen\Qwen-1_8B-Chat-merged"完成对模型的转换,转换的结果为.gguf文件,接下来建立 Modelfile 文件,在这个文件中输入FROM D:\pyCharmProject\qwen1.8\qwen\Qwen-1.8B-Chat-F32.gguf,保存即可,使用命令行 ollama create qwen1.8Test -f D:\pyCharmProject\bbb.Modelfile,建立新的模型。

出现success表示建立成功。,然后运行模型ollama run qwen1.8Test,进行模型对话。
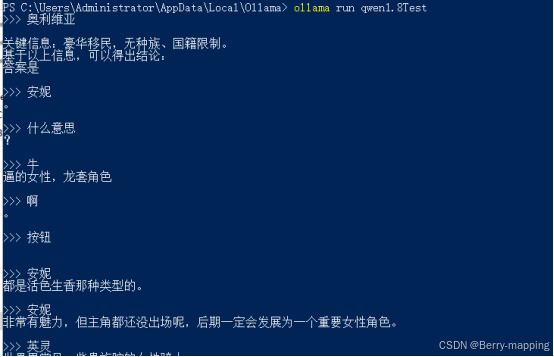
这个结果明显训练或配置的有部分问题,导致问答概念混乱(大概是TEMPLATE 和 PARAMETER 的内容如何定义,需要查看各个模型页面的相关说明这个问题),解决问题后会及时更新。有问题欢迎各位小伙伴指导。


















 2932
2932

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









