




一、平台介绍
财务自营计费主要承接京东自营数据在整个供应链中由C端转B端的功能实现,在整个供应链中属于靠后的阶段了,系统主要功能是计费和向B端的汇总。
二、问题描述
近年来自营计费数据量大增,有百亿+的数据量,一天中汇总占据了一半的数据库资源。
1、每天从单表千万W+中定位几万数据执行汇总,即全库全表执行group by操作,32库*32表,每天要花12小时处理。
2、汇总期间,系统基本停滞,导致了消息、任务处理慢,积压多,数据无法及时计费。
3、数据库压力大,有随时崩溃的风险。
4、影响供应商体验,大促期间供应商要实时查看销售数据,出战报,系统无法及时响应。
三、原技术介绍
系统汇总核心是依靠MySQL物理机在每库每表通过group by进行,汇总是按费用类型分而治之,每种类型汇总维度不一样,每次如有新的汇总维度引入,需从前到后,写一遍新的汇总逻辑,主要是锁定新维度的数据范围,确定新的group by 字段,之前逻辑还得回归测试,很蠢是吧,我也觉得。
四、解决问题的思路和办法
根据以上的背景和问题,确定大致的解决问题思路
1、首先要脱离MySQL汇总,数据库是很脆弱的,要保护数据库,不然量级一直递增,总有天塌的一天。
2、顺带解决新需求重复开发的弊端。
五、实践过程描述
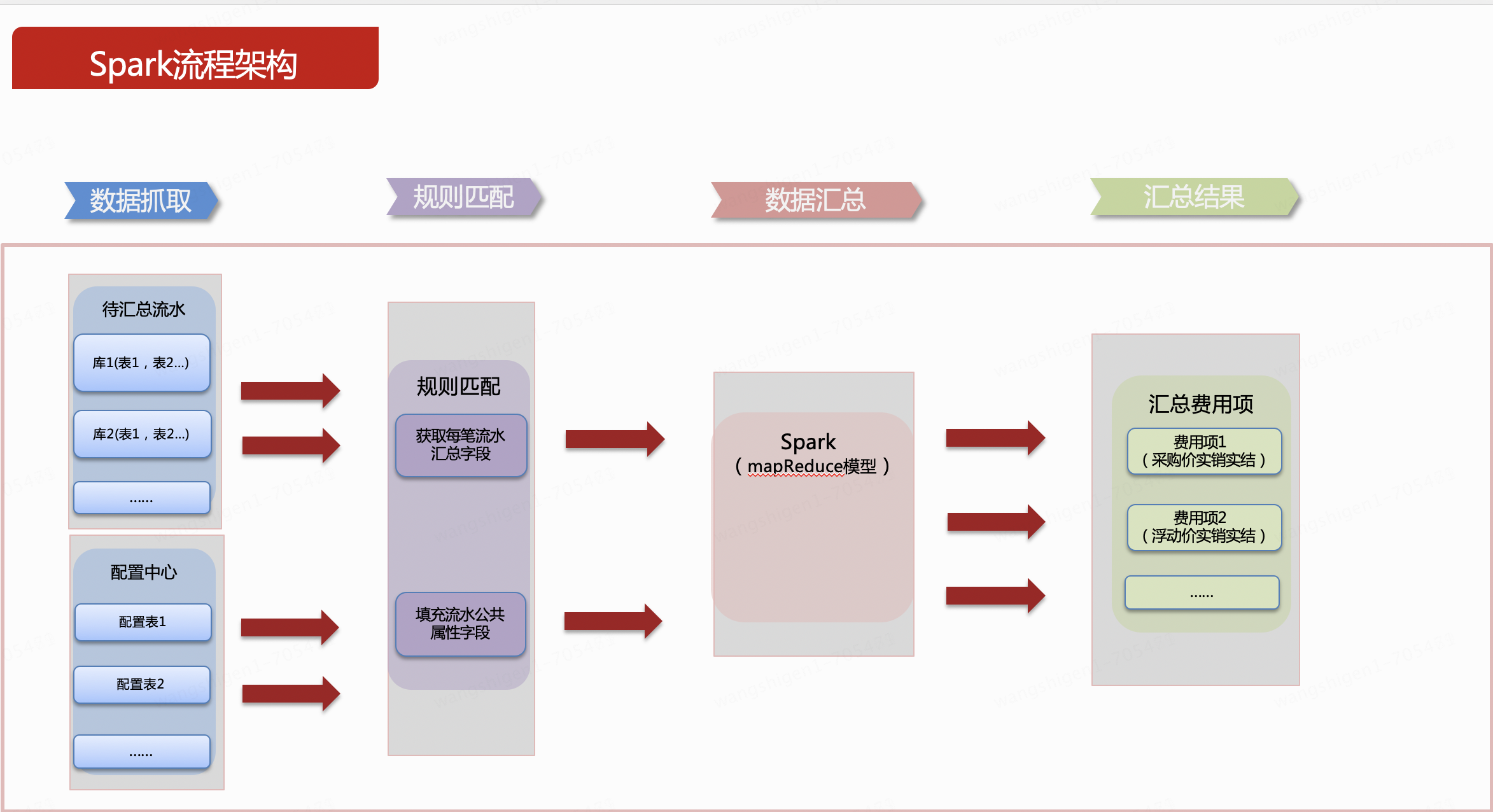
由于量大,业务上允许T+1处理,既然是离线数据处理,一般都能想到spark,spring batch,finlk等,在技术调研阶段,主要考虑成熟性,社区活跃度,主要采用spark技术。按照汇总的流程划分4个步骤。以下内容为了通俗易懂,简化了逻辑进行简单描述下。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2257
2257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









