




LangChain
LangChain是一个以 LLM (大语言模型)模型为核心的开发框架,LangChain的主要特性:
- 可以连接多种数据源,比如网页链接、本地PDF文件、向量数据库等
- 允许语言模型与其环境交互
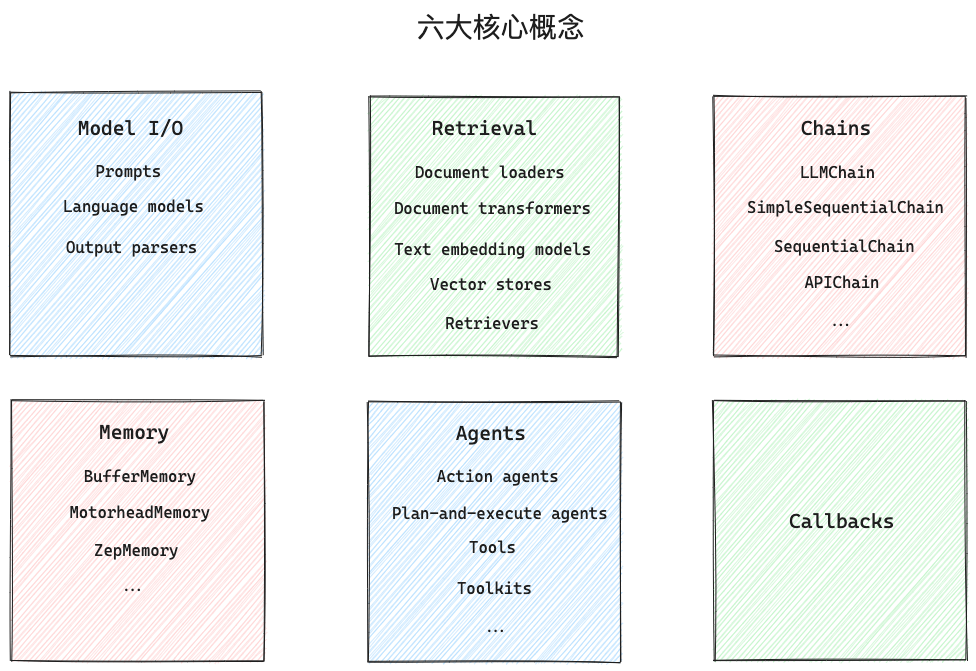
- 封装了Model I/O(输入/输出)、Retrieval(检索器)、Memory(记忆)、Agents(决策和调度)等核心组件
- 可以使用链的方式组装这些组件,以便最好地完成特定用例。
围绕以上设计原则,LangChain解决了现在开发人工智能应用的一些切实痛点。以 GPT 模型为例:
- 数据滞后,现在训练的数据是到 2021年9月。
- token数量限制,如果让它对一个300页的pdf进行总结,直接使用则无能为力。
- 不能进行联网,获取不到最新的内容。
- 不能与其他数据源链接。
另外作为一个胶水层框架,极大地提高了开发效率,它的作用可以类比于jquery在前端开发中的角色,使得开发者可以更专注于创新和优化产品功能。
1、Model I/O
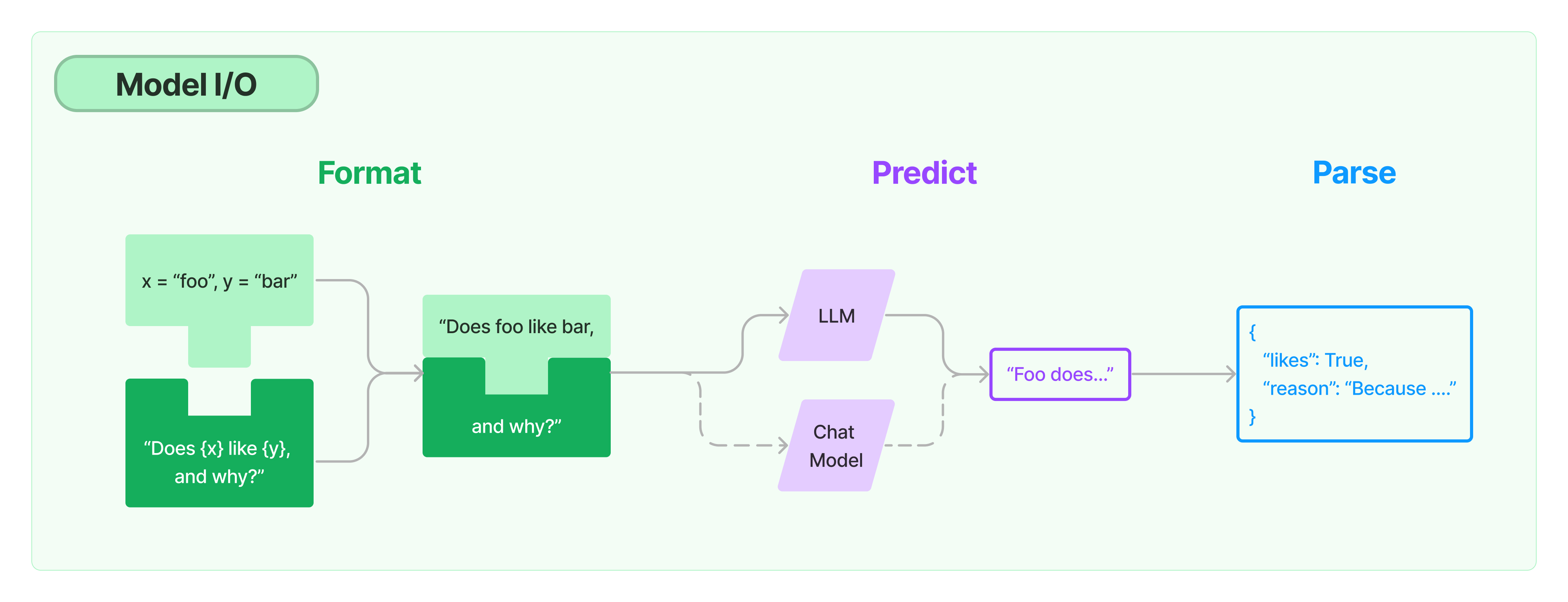
LangChain提供了与任何语言模型交互的构建块,交互的输入输出主要包括:Prompts、Language models、Output parsers三部分。
1.1 Prompts
LangChain 提供了多个类和函数,使构建和使用提示词变得容易。Prompts模块主要包含了模板化、动态选择和管理模型输入两部分。其中:
1.1.1 Prompt templates
提示模版类似于ES6模板字符串,可以在字符串中插入变量或表达式,接收来自最终用户的一组参数并生成提示。
一个简单的例子:
const multipleInputPrompt = new PromptTemplate({
inputVariables: ["adjective", "content"],
template: "Tell me a {adjective} joke about {content}.",
});
const formattedMultipleInputPrompt = await multipleInputPrompt.format({
adjective: "funny",
content: "chickens",
});
console.log(formattedMultipleInputPrompt);
// "Tell me a funny joke about chickens.
同时可以通过 PipelinePrompt将多个PromptTemplate提示模版进行组合,组合的优点是可以很方便的进行复用。比如常见的系统角色提示词,一般都遵循以下结构:{introduction} {example} {start},比如一个【名人采访】角色的提示词:
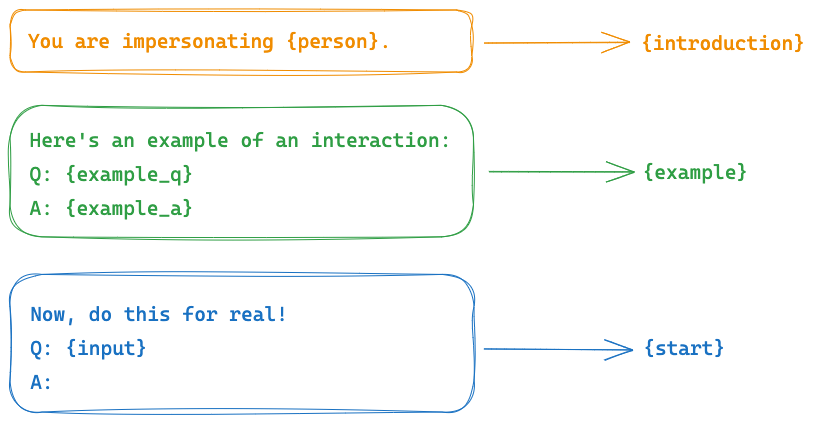
使用PipelinePrompt组合实现:
import { PromptTemplate, PipelinePromptTemplate } from "langchain/prompts";
const fullPrompt = PromptTemplate.fromTemplate(`{introduction}
{example}
{start}`);
const introductionPrompt = PromptTemplate.fromTemplate(
`You are impersonating {person}.`
);
const examplePrompt =
PromptTemplate.fromTemplate(`Here's an example of an interaction:
Q: {example_q}
A: {example_a}`);
const startPrompt = PromptTemplate.fromTemplate(`Now, do this for real!
Q: {input}
A:`);
const composedPrompt = new PipelinePromptTemplate({
pipelinePrompts: [
{
name: "introduction",
prompt: introductionPrompt,
},
{
name: "example",
prompt: examplePrompt,
},
{
name: "start",
prompt: startPrompt,
},
],
finalPrompt: fullPrompt,
});
const formattedPrompt = await composedPrompt.format({
person: "Elon Musk",
example_q: `What's your favorite car?`,
example_a: "Telsa",
input: `What's your favorite social media site?`,
});
console.log(formattedPrompt);
/*
You are impersonating Elon Musk.
Here's an example of an interaction:
Q: What's your favorite car?
A: Telsa
Now, do this for real!
Q: What's your favorite social media site?
A:
*/
1.1.2 Example selectors
为了大模型能够给出相对精准的输出内容,通常会在prompt中提供一些示例描述,如果包含大量示例会浪费token数量,甚至可能会超过最大token限制。为此,LangChain提供了示例选择器,可以从用户提供的大量示例中,选择最合适的部分作为最终的prompt。通常有2种方式:按长度选择和按相似度选择。
按长度选择:对于较长的输入,它将选择较少的示例来;而对于较短的输入,它将选择更多的示例。
...
// 定义长度选择器
const exampleSelector = await LengthBasedExampleSelector.fromExamples(
[
{ input: "happy", output: "sad" },
{ input: "tall", output: "short" },
{ input: "energetic", output: "lethargic" },
{ input: "sunny", output: "gloomy" },
{ input: "windy", output: "calm" },
],
{
examplePrompt,
maxLength: 25,
}
);
...
// 最终会根据用户的输入长度,来选择合适的示例
// 用户输入较少,选择所有示例
console.log(await dynamicPrompt.format({ adjective: "big" }));
/*
Give the antonym of every input
Input: happy
Output: sad
Input: tall
Output: short
Input: energetic
Output: lethargic
Input: sunny
Output: gloomy
Input: windy
Output: calm
Input: big
Output:
*/
// 用户输入较多,选择其中一个示例
const longString =
"big and huge and massive and large and gigantic and tall and much much much much muc 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2257
2257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









