



目录
环境信息
集群配置:
本次搭建集群为 3 master + 3 worker(worker包含一台 3090 gpu节点),版本 v1.30.4
机器列表:
| ip | 角色 | 系统 | 内核 |
| 10.144.11.1 | master1 | centos7.9 | 4.20.0-1 |
| 10.144.11.2 | master2 | centos7.9 | 4.20.0-1 |
| 10.144.11.3 | master3 | centos7.9 | 4.20.0-1 |
| 10.144.11.4 | worker | centos7.9 | 4.20.0-1 |
| 10.144.11.5 | worker, gpu | centos7.9 | 4.20.0-1 |
初始化环境准备
注: 初始化环境操作需在所有机器上执行
机器初始化:
关防火墙:
# systemctl stop firewalld
# systemctl disable firewalld
&&
# systemctl stop iptables
# systemctl disable iptables
关闭selinux
# sed -i 's/enforcing/disabled/' /etc/selinux/config # 永久
# setenforce 0 # 临时
关闭swap
# swapoff -a # 临时
# sed -ri 's/.*swap.*/#&/' /etc/fstab # 永久
将桥接的IPv4流量传递到iptables的链
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
sysctl --system # 生效
# 配置节点名称hosts解析
大多人选择修改机器名称实现集群节点以 master1 2 3 worker 1 2 3命名
但因修改机器名对司内资产统计或其他业务的影响,博主选择直接使用现有机器名作为节点名称
在hosts中配置机器名与ip地址对应关系即可:
cat > /etc/hosts << EOF
10.144.11.1 hostname001
10.144.11.2 hostname002
10.144.11.3 hostname003
10.144.11.4 hostname004
10.144.11.5 hostname005
EOF
依赖组件安装
containerd安装
提供两种安装containerd方式:
1. 离线安装(网络限制)
# 联网机器拉取后转存到集群机器
wget https://github.com/containerd/containerd/releases/download/v1.7.22/cri-containerd-cni-1.7.22-linux-amd64.tar.gz
wget https://raw.githubusercontent.com/containerd/containerd/main/containerd.service
# 解压安装
sudo tar Cxzvf /usr/local cri-containerd-cni-1.7.22-linux-amd64.tar.gz
# 安装 systemd 服务文件
sudo mv containerd.service /usr/lib/systemd/system/
2. yum源安装(通公网)
# 添加 Docker 官方仓库
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
# 更新 yum 缓存
sudo yum makecache
# 安装 containerd.io 包
sudo yum install -y containerd.io
或可查询后指定版本安装
yum list containerd.io --showduplicates| sort
调整containerd配置:
# 生成默认配置文件
sudo mkdir -p /etc/containerd
sudo containerd config default | sudo tee /etc/containerd/config.toml
# 启用 systemd cgroup 驱动(如果使用 systemd)
sudo sed -i 's/SystemdCgroup = false/SystemdCgroup = true/' /etc/containerd/config.toml
#镜像仓配置:
[plugins."io.containerd.grpc.v1.cri".registry.configs]
[plugins."io.containerd.grpc.v1.cri".registry.configs."$your-registry".auth]
username = "$username"
password = "$password"
#若使用内部镜像仓,记得修改pause镜像仓地址
sandbox_image = "$your-registry/pause:3.9"
# 启动containerd:
systemctl daemon-reload
systemctl start containerd
systemctl enable containerd
踩坑:
后续cordns报错
Listen: listen tcp :53: bind: permission denied
调整containerd配置
将enable_unprivileged_ports 改成true
重启containerdkubectl、kubelet、kubeadm安装
# 配置yum源
# 创建 Kubernetes 仓库文件-本次使用阿里源
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
EOF
# 查询版本列表
yum list kubeadm --showduplicates| sort
yum list kubeadm --showduplicates| sort
yum list kubeadm --showduplicates| sort
#安装
yum install kubelet-1.30.4-150500.1.1 kubeadm-1.30.4-150500.1.1 kubectl-1.30.4-150500.1.1 -y
systemctl enable kubelet
#该步骤可能会遇到报错
Error: Package: kubelet-1.30.4-150500.1.1.x86_64 (kubernetes)
Requires: conntrack
You could try using --skip-broken to work around the problem
# 安装依赖包conntrack即可
yum install conntrack-tools.x86_64其他依赖组件安装
#需安装libseccomp包,不然会报网络问题
yum install libseccomp-2.5.1-1.el8.x86_64.rpm
#安装cni网络组件
tar -C /opt/cni/bin -xzf cni-plugins-linux-amd64-v1.5.1.tgz
#######稍后补全组件拉取路径#######
负载均衡实现
搭建haproxy、keepalived,实现高可用及负载均衡
#centos
yum install haproxy keepalived
# haproxy负载均衡配置,3master配置一样
/etc/haproxy/haproxy.cfg
----开始----
global
maxconn 2000
ulimit-n 16384
log 127.0.0.1 local0 err
stats timeout 30s
defaults
log global
mode http
option httplog
timeout connect 5000
timeout client 50000
timeout server 50000
timeout http-request 15s
timeout http-keep-alive 15s
frontend monitor-in
bind *:33305
mode http
option httplog
monitor-uri /monitor
frontend k8s-master
bind 0.0.0.0:9443
bind 127.0.0.1:9443
mode tcp
option tcplog
tcp-request inspect-delay 5s
default_backend k8s-master
backend k8s-master
mode tcp
option tcplog
option tcp-check
balance roundrobin
default-server inter 10s downinter 5s rise 2 fall 2 slowstart 60s maxconn 250 maxqueue 256 weight 100
server hostname001 10.144.11.1:6443 check
server hostname002 10.144.11.2:6443 check
server hostname003 10.144.11.3:6443 check
----结束----
# keepalived 高可用配置,准备一个vip ,其他节点修改本地ip地址和权重即可
/etc/keepalived/keepalived.conf
-----开始------
global_defs {
router_id LVS_DEVEL
}
vrrp_script chk_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 5
weight -5
fall 2
rise 1
}
vrrp_instance VI_1 {
state MASTER
interface bond4 #本机网卡名
mcast_src_ip 10.144.11.1 #本机ip地址
virtual_router_id 51
priority 103 #本机权重,权重越大,优先级越高
nopreempt
advert_int 2
authentication {
auth_type PASS
auth_pass K8SHA_KA_AUTH
}
virtual_ipaddress {
10.144.1.248 #VIP虚拟地址配置
}
track_script {
chk_apiserver
} }
-----结束------
/etc/keepalived/check_apiserver.sh 配置,3master一致
-----开始------
#!/bin/bash
err=0
for k in $(seq 1 3)
do
check_code=$(pgrep haproxy)
if [[ $check_code == "" ]]; then
err=$(expr $err + 1)
sleep 1
continue
else
err=0
break
fi
done
if [[ $err != "0" ]]; then
echo "systemctl stop keepalived"
/usr/bin/systemctl stop keepalived
exit 1
else
exit 0
fi
-----结束------
# 启动&开机自启
systemctl start haproxy && systemctl enable haproxy
systemctl start keepalived && systemctl enable keepalived
# 验证1: vip及端口是否存在
netstat -lnpt |grep 9443
ip a |grep bond
#验证2: stop掉keepalived,查看vip是否会飘到其他节点
systemctl stop keepalived
集群搭建
集群初始化
初始化先在master1执行,后续节点通过join添加
#生成默认kubeadm配置
kubeadm config print init-defaults > kubeadm-config.yaml
#调整配置
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 10.144.11.1
bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
imagePullPolicy: IfNotPresent
name: SCSP00745
taints: null
---
apiServer:
certSANs:
- 10.144.11.1
- 10.144.11.2
- 10.144.11.3
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
controlPlaneEndpoint: "10.144.11.248:9443"
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: artifact.com/tfai/k8s #配置自己的镜像仓库
kind: ClusterConfiguration
kubernetesVersion: 1.30.4
networking:
dnsDomain: sail-cloud.cluster.local
serviceSubnet: 10.96.0.0/12
podSubnet: 10.244.0.0/16
#提前拉取镜像
sudo kubeadm config images list --config kubeadm-config.yaml #适用于私有仓库查看
sudo kubeadm config images pull --config kubeadm-config.yaml #适用于私有仓库拉取
kubeadm config images list --kubernetes-version=v1.30.4
kubeadm config images pull --kubernetes-version=v1.30.4
# 执行集群初始化
kubeadm init --config kubeadm-config.yaml --upload-certs
#记录join语句
添加master:
kubeadm join 10.144.11.248:9443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:5ca13dfb065115d496f38a2f875e11cce5d269fc780bcea15e9fc59915b43d60 \
--control-plane --certificate-key 4dae5da59f83edf9b0fb7a815ac3315d7504d6c0dd78ba3bdfb31de744a1663b
添加worker:
kubeadm join 10.144.11.248:9443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:5ca13dfb065115d496f38a2f875e11cce5d269fc780bcea15e9fc59915b43d60
#语句过期或未保留,用以下语句生成token:
kubeadm token create --print-join-command
# master的certificate-key过期生成,默认24h有效期
kubeadm init phase upload-certs --upload-certs
集群网络组件安装
# 网络组件calico 使用operater搭建
wget https://raw.githubusercontent.com/projectcalico/calico/v3.25.2/manifests/tigera-operator.yaml
wget https://raw.githubusercontent.com/projectcalico/calico/v3.25.2/manifests/custom-resour
ces.yaml
# kubectl create -f tigera-operator.yaml
# kubectl create -f custom-resources.yaml
#问题记录,涉及到镜像拉取问题,需修改calico镜像拉取地址
#修改crd
kubectl edit installation default -n calico-system
#新增 -与calicoNetwork 同级
registry: artifact.com/k8s/
查看集群pod状态:
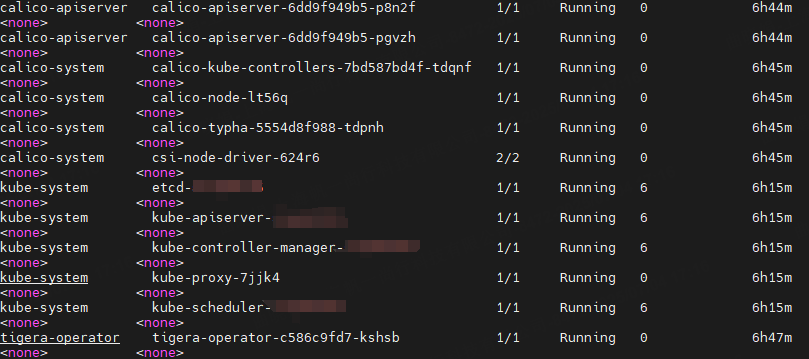
新增master节点
在两个master节点上执行:
#执行加入集群命令行
kubeadm join 10.144.11.248:9443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:5ca13dfb065115d496f38a2f875e11cce5d269fc780bcea15e9fc59915b43d60 \
--control-plane --certificate-key 4dae5da59f83edf9b0fb7a815ac3315d7504d6c0dd78ba3bdfb31de744a1663b新增worker节点
在两个worker节点上执行:
#执行加入集群命令行:
kubeadm join 10.144.11.248:9443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:5ca13dfb065115d496f38a2f875e11cce5d269fc780bcea15e9fc59915b43d60查看节点及pod状态

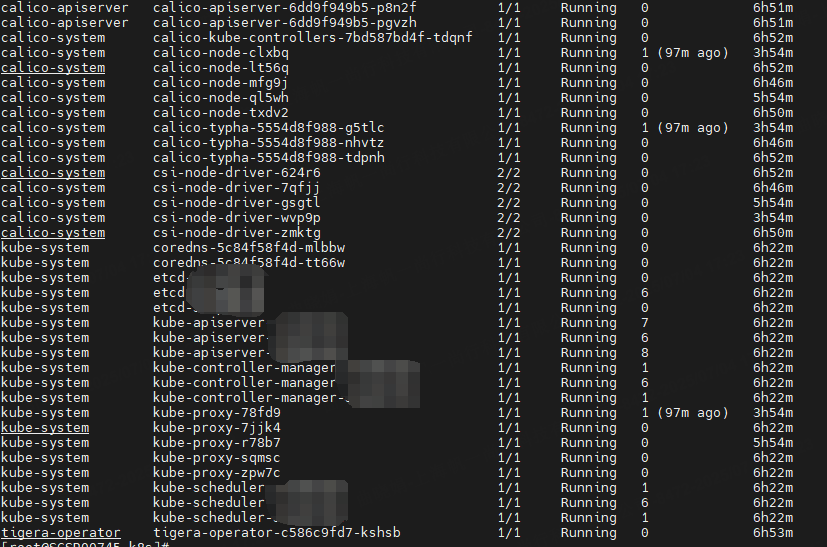
-------------------------------------------------- 补充 ---------------------------------------------------------
1. etcd状态检查命令:
etcd使用控制平面堆叠部署方式,在三个master节点上呈现的进程参数值不一致,所以担心etcd集群的状态会不会有问题,进程呈现形式是:
堆叠架构图也贴上:
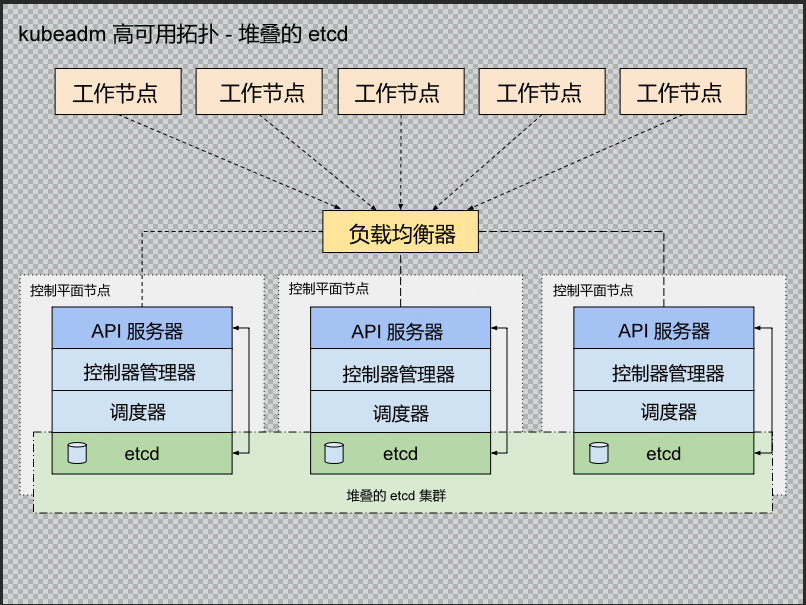
进程呈现形式:
master1的etcd进程 --initial-cluster 信息只包含自己的,master2包含1 和 2的,master3包含1 2 3的
etcd状态查询:
进到任一etcd容器中,使用etcdctl命令查询
ETCDCTL_API=3 etcdctl \
--cert /etc/kubernetes/pki/etcd/peer.crt \
--key /etc/kubernetes/pki/etcd/peer.key \
--cacert /etc/kubernetes/pki/etcd/ca.crt \
--endpoints https://$etcd1:2379 \
endpoint status --cluster -w table # 查看集群详细状态,包括领导节点# 其他
member list # 查看集群成员列表
endpoint health --cluster # 快速检查集群是否健康
案例: 详细信息,集群中只有一个节点上还leader,其他false

后续补充gpu运行时及plugin安装步骤,以及模型使用k8s中gpu节点调度场景。。。。

















 1415
1415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









