




 本文深入探讨了高并发分布式应用中的缓存策略,包括本地缓存和分布式缓存的比较,如Guava、Caffeine、Ehcache、Redis、memcached等产品的特性,以及大型互联网企业如何构建多层级缓存架构。
本文深入探讨了高并发分布式应用中的缓存策略,包括本地缓存和分布式缓存的比较,如Guava、Caffeine、Ehcache、Redis、memcached等产品的特性,以及大型互联网企业如何构建多层级缓存架构。
在高并发分布式应用中缓存从来都是必要的,而且从来都是综合应用本地缓存和分布式缓存提高性能的。
【1】本地缓存
本地缓存即缓存和应用在同一个进程里,是基于JVM的缓存,应用生则生,应用死则亡。
常见产品有Guava、Caffeine和Ehcache。三者对比如下:
| 对比项 | Guava | Caffeine | Ehcache |
|---|---|---|---|
| 是否开源 | Y(Google) | Y(apache) | Y(Terracotta) |
| 级别 | 轻量 | 轻量 | 重量级 |
| 知名度 | Java开发者必备 | Spring5 | Hibernate |
| 缓存算法 | LRU | W-TinyLFU | LRU、LFU FIFO |
| JDK版本 | >=1.6 | >=1.8 | >=1.5 |
| 持久化支持 | 不支持 | 不支持 | 支持(商业) |
| 集群解决方案 | 无 | 无 | 有(商业) |
| Spring Cache支持 | 不支持 | 支持 | 支持 |
| 性能监控 | 不带 | 不带 | 提供(JMX 页面) |
【2】分布式缓存
常见的有Redis、memcached。关于二者相关知识参考博文:Redis/Memcache那些事。
二者具体对比如下:
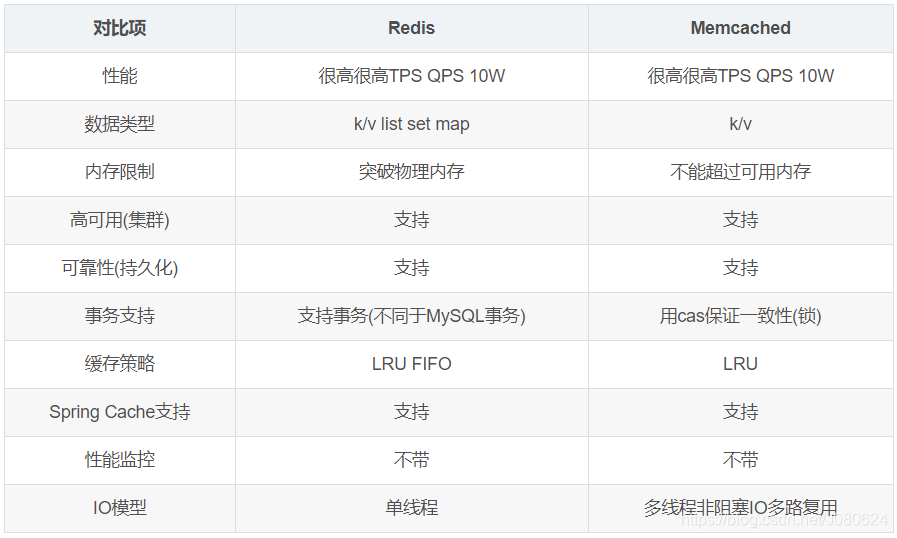
【3】本地缓存VS分布式缓存
对比如下:
| 对比项 | 本地缓存 | 分布式缓存 |
|---|---|---|
| 概念 | 缓存和应用在同一个进程里,是基于JVM的缓存 | 单独的组件与应用分离 |
| 社区成熟 | 非常高 | 非常高 |
| 性能 | 很高 单机 | 高 需要TCP协议交互 |
| 黏度 | 紧耦合 | 松耦合 |
| 适用环境 | 单机 | 单机/集群环境 |
| 高可用 | 应用生则生,应用亡则亡 | 集群抱团 |
| 应用共享 | 不能共享 | 可以共享 |
【4】本地缓存VS分布式缓存VS数据库
使用不同方案获取50K数据进行10次测试对比表格如下:
| 缓存方式 | 数据总量 | 总响应时长(毫秒) | 第一次响应(毫秒) | 测试次数 | 平均响应时长 |
|---|---|---|---|---|---|
| 数据库中读取 | 50K | 83 | 12 | 10 | 8.3ms |
| 分布式缓存使用redis | 50K | 7 | 0.8 | 10 | 0.7ms |
| 本地应用缓存使用Guava | 50K | 0.133 | 0.011 | 10 | 0.013ms |
| 本地应用缓存直接使用map | 50K | 0.129 | 0.011 | 10 | 0.0129毫秒 |
【5】企业缓存常见方案
① 大型互联网企业如何选择缓存
大型互联网企业在选择缓存技术时,会基于多个因素来决定最合适的缓存策略和工具。以下是选择缓存时通常考虑的关键点:
1. 性能需求
- 读写频率: 如果应用主要是读密集型,可以选择具有高速读取能力的缓存,如Redis或Memcached。
- 数据量大小: 对于小数据量,本地缓存如Guava Cache或Caffeine可能是好的选择;大数据量则更倾向于分布式缓存。
2. 可扩展性
- 分布式架构: 需要考虑缓存的水平扩展能力,分布式缓存如Redis Cluster、Memcached、Hazelcast等能够支持大规模的扩展需求。
3. 数据一致性
- 一致性模型: 选择缓存时,需考虑其提供的一致性模型,如强一致性、最终一致性等。
- 同步策略: 如何在缓存和数据库间保持数据同步,以及如何处理缓存穿透、击穿、雪崩等问题。
4. 高可用性
- 冗余和故障转移: 分布式缓存应具备主从复制、哨兵或集群模式以保证高可用性。
- 故障恢复: 快速的数据恢复机制是必要的,以减少系统宕机时间。
5. 成本效益
- 成本: 考虑硬件成本、运维成本以及可能的云服务费用。
- 资源利用率: 选择能够高效利用资源的缓存方案。
6. 安全性
- 数据安全: 确保缓存数据的安全,包括加密传输和存储。
- 访问控制: 控制谁可以访问缓存,防止未授权访问。
7. 技术栈兼容性
- 语言和平台支持: 选择与现有技术栈兼容的缓存技术。
- 集成难度: 评估与现有系统的集成难度和复杂度。
8. 社区和生态系统
- 成熟度: 技术的成熟度和稳定性。
- 社区支持: 活跃的社区意味着更好的文档和支持。
9. 监控和运维
- 监控工具: 是否有现成的监控和管理工具。
- 运维成本: 包括自动化运维、备份和恢复机制。
10. 业务场景
- 特定需求: 根据业务场景选择最适合的缓存策略,例如静态数据、会话数据、实时数据等。
例子
- 本地缓存: Guava Cache 或 Caffeine,适用于较小规模且需要快速访问的数据。
- 分布式缓存: Redis 和 Memcached,适用于大规模数据和高并发场景。
- 文件缓存: Nginx 的缓存模块,适用于静态内容的缓存。
- 数据库层面的缓存: MySQL 的 Query Cache,虽然不推荐用于现代系统,但在某些场景下仍有其价值。
在实际操作中,大型互联网企业往往不会只使用单一的缓存技术,而是构建一个多层级、混合型的缓存架构,结合本地缓存、分布式缓存和数据库缓存等不同层级的缓存,以满足不同场景的需求。
② 常见缓存架构
如下表所示:
| 层级 | 常见产品 | 缓存解决方案 | 缓存技术 |
|---|---|---|---|
| 应用层 | 浏览器 | 浏览器缓存 本地缓存 | HTTP缓存协商 cookie sqlite websql |
| 网络层 | 网络路由 | CDN | Squid等 |
| 负载层 | Nginx Apache 等 | 动静分离 反向代理 | 基于Http服务器 |
| 服务层 | Java应用 | 动态页面静态化 应用缓存 分布式缓存 MyBatis缓存 | freemarker velocity Thymeleaf Ehcache Guava Caffeine Redis Memcached MyBatis一级二级缓存 |
| 数据库 | Oracle MySQL | 缓冲区 Buffer Pool | 数据库缓存机制 |
③ 多级缓存方案示例
确实,大型互联网企业为了应对高并发、大数据量和复杂的业务场景,往往会采用多层级、混合型的缓存架构。下面是一个示例架构,说明了不同层次和类型的缓存如何协同工作:
1. 客户端缓存(Client-Side Caching)
- 实现方式: 浏览器缓存、移动应用本地存储(如SQLite或Realm)。
- 用途: 存储用户界面状态、频繁访问的小型数据集,如用户偏好、最近浏览的商品列表。
- 优势: 减少网络往返时间,提升用户体验。
2. 本地缓存(In-Process Caching)
- 实现方式: Java中的Guava Cache, .NET中的MemoryCache, Python中的LRUCache。
- 用途: 存储热点数据、计算结果,如用户信息、商品详情。
- 优势: 低延迟,快速访问,无需网络通信。
3. 分布式缓存(Distributed Caching)
- 实现方式: Redis、Memcached、Ignite、Hazelcast。
- 用途: 跨服务器共享数据,存储高并发访问的大数据集,如热门文章、商品库存信息。
- 优势: 水平扩展,高可用性,适合处理大规模数据和高并发请求。
4. 数据库缓存(Database Level Caching)
- 实现方式: SQL Server的Buffer Pool、MySQL的Query Cache(不推荐)、NoSQL数据库如MongoDB的内存缓存。
- 用途: 缓存数据库查询结果,减少磁盘I/O,加速数据读取。
- 优势: 减轻数据库服务器的压力,提高数据库性能。
5. CDN缓存(Content Delivery Network Caching)
- 实现方式: 使用第三方CDN服务,如Cloudflare、Akamai。
- 用途: 缓存静态资源(如图片、CSS、JS文件),地理位置分散的动态内容。
- 优势: 加速全球范围的内容分发,减轻源服务器负担。
6. 智能缓存策略
- 实现方式: 结合多种缓存技术和策略,如缓存预热、缓存失效策略、缓存数据的分级存储。
- 用途: 根据业务需求和数据特性智能选择缓存策略,如热点数据使用Redis,冷数据使用廉价的分布式文件系统。
- 优势: 最大化缓存效率,降低总体成本。
在这样的多层级缓存架构中,每一层都有其特定的作用和优化点,共同构成一个高效、可扩展的缓存系统。这种架构能够适应复杂多变的互联网环境,提供稳定的服务质量和优秀的用户体验。
什么是SpringCache?
参考博文:
SpringBoot - Spring缓存默认配置与运行流程
SpringBoot - 缓存入门详解与注解使用实例


















 2429
2429




 到【灌水乐园】发言
到【灌水乐园】发言









