



PostgreSQL 以固定大小的数据块(Page)存储数据,默认大小为 8 KB。当客户端执行更新或插入操作时,PostgreSQL 并不会立即将变更写入磁盘,而是先将相关数据页加载到共享内存(Shared Buffers)中,在内存中完成修改,并将该页面标记为“脏页”。所谓“脏页”,是指内存中的页面版本已经新于磁盘上的对应版本。
在向客户端返回操作结果之前,PostgreSQL 会先将变更记录写入预写日志(Write-Ahead Log,WAL),以保证即使数据库发生崩溃也能恢复数据一致性。但实际的数据文件并不会立刻更新,只有在检查点(Checkpoint)触发或后台写进程执行刷新时,脏页才会被写回磁盘。
在此之前,脏页会持续累积在内存中,直到通过以下三种机制之一被刷新:
- 后台写进程(
Background Writer,BGWriter):一个常驻后台进程,在可用的干净缓冲区数量下降时,持续将脏页写入磁盘。 - 检查点进程(Checkpointer):在触发检查点时(如达到
checkpoint_timeout或 WAL 超过max_wal_size),将所有脏页刷新到磁盘。 - 后端进程(Backend):在紧急情况下(如共享缓冲区几乎全部为脏页),普通后端进程会自行写脏页,可能导致用户查询阻塞。
理解并合理控制脏页的刷新时机与方式,是优化 PostgreSQL 性能的关键。
脏页为何影响性能
脏页会从多个方面影响数据库性能:
1. 检查点期间的 I/O 峰值
检查点发生时,所有脏页都必须被刷新到磁盘。如果脏页数量较多,会在短时间内产生大量磁盘 I/O,影响其他查询性能。checkpoint_timeout、checkpoint_completion_target 和 max_wal_size 等参数决定了检查点触发的频率以及刷新脏页的节奏。
2. 后端写入带来的查询阻塞
当共享缓冲区被大量脏页占满,而 BGWriter 无法及时清理时,后端进程将被迫自行写盘,直接阻塞正在执行的用户查询。为避免此类情况,应通过合理的内存与刷新参数配置,让 BGWriter 承担绝大多数写入工作。实践中通常包括:
- 为
shared_buffers分配足够内存; - 调整
bgwriter_delay、bgwriter_lru_maxpages、bgwriter_lru_multiplier、bgwriter_flush_after等参数,使脏页持续、平稳地写入磁盘; - 通过增大
checkpoint_timeout、提高checkpoint_completion_target以及增大max_wal_size,减少检查点引发的突发写入。
3. 吞吐量与崩溃恢复时间的权衡
较少的刷新频率(如较大的 checkpoint_timeout)可以降低 I/O 开销,但会增加数据库崩溃后需要回放的 WAL 数量;更频繁的刷新可以加快恢复速度,但可能降低运行时性能。合理的参数配置需要根据实际业务负载在两者之间取得平衡。
PostgreSQL 管理脏页的核心机制
后台写进程(Background Writer,BGWriter)
BGWriter 是一个独立进程,其目标是在后台持续写出脏页,保持一定数量的干净缓冲区可用。根据官方文档描述:
- 当共享缓冲区中可用的干净页面数量低于阈值时,BGWriter 会写出部分脏页并将其标记为干净。
- 若同一页面在一个检查点周期内被多次修改,可能会被多次写盘,从而增加总体 I/O。
BGWriter 的主要配置参数(位于 postgresql.conf)包括:
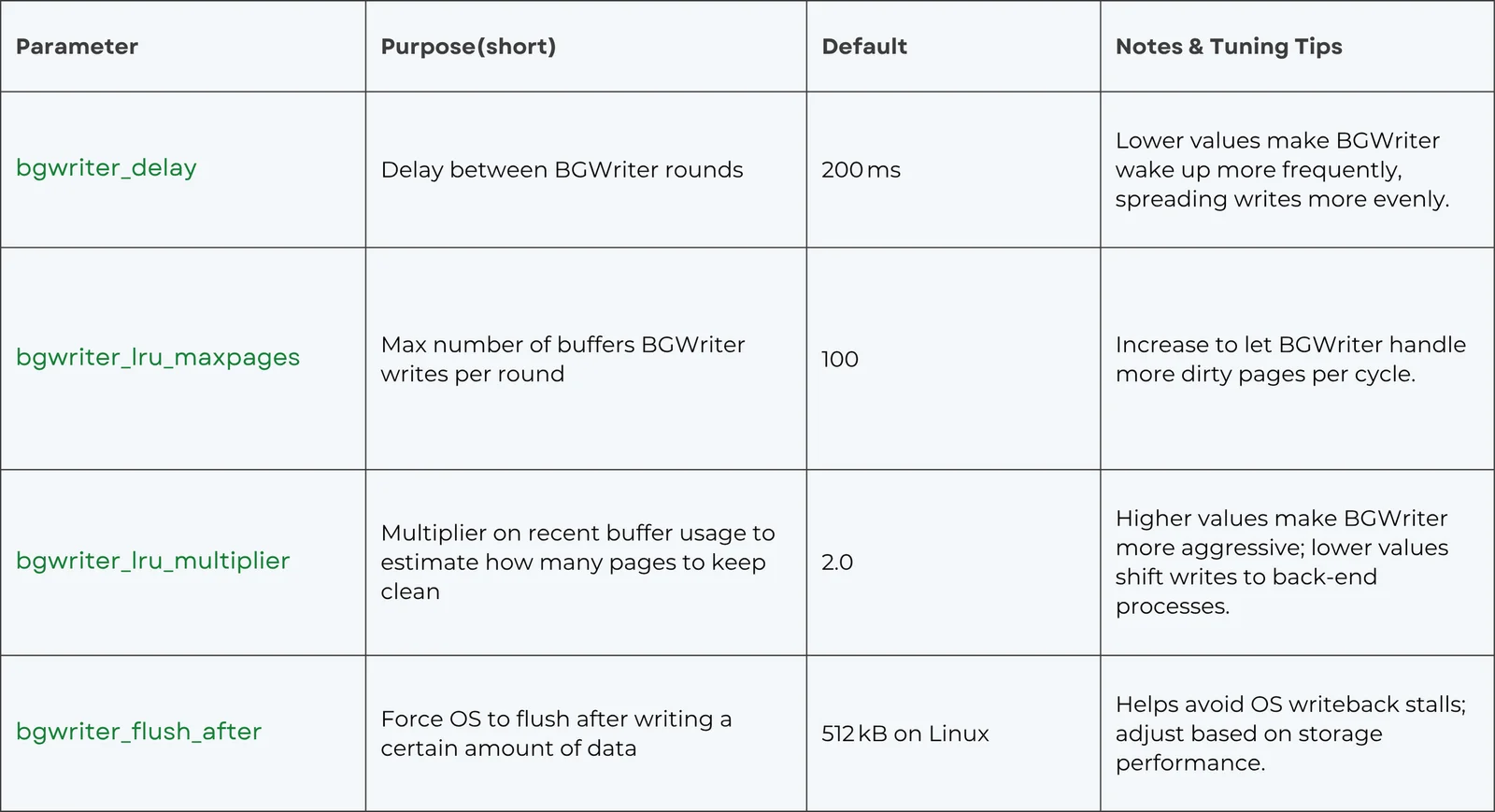
调优建议:
如果在 pg_stat_bgwriter 中观察到后端进程写盘较多,应适当提高 bgwriter_lru_maxpages 和 bgwriter_lru_multiplier;若 BGWriter 本身导致 I/O 过高,则可适当降低相关参数。通过调整 bgwriter_delay,在写入频率与 CPU 开销之间取得平衡。
检查点(Checkpointer)
检查点触发时,PostgreSQL 会将所有脏页写入磁盘,并在 WAL 中记录检查点位置。合理调整检查点参数有助于平滑 I/O 压力:
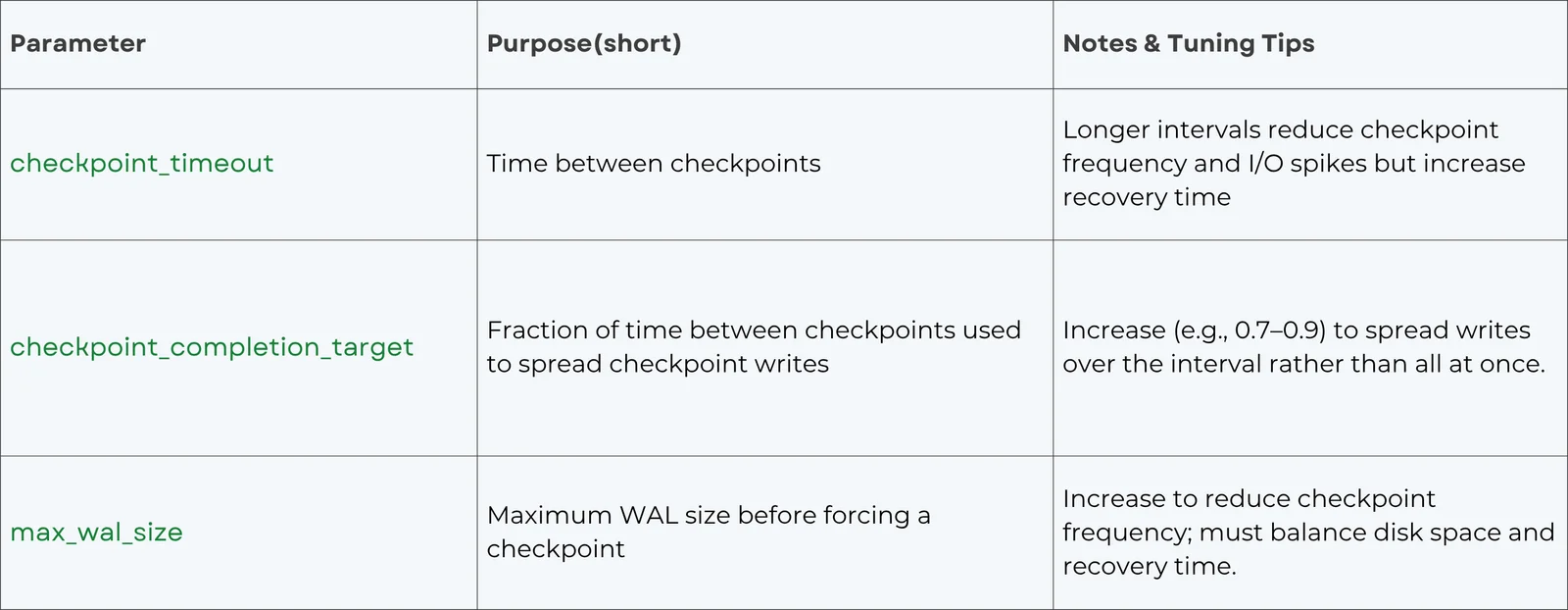
通过增大 checkpoint_timeout 和 checkpoint_completion_target,可以将写入分散到更长时间窗口内;max_wal_size 决定了自动检查点的触发时机,从而间接影响脏页刷新频率。
共享缓冲区(Shared Buffers)
shared_buffers 决定了 PostgreSQL 可用于缓存数据页和存放脏页的内存大小。该参数直接影响页面在内存中的停留时间以及写盘频率。
在专用数据库服务器上,通常建议将其设置为物理内存的 25%~ 40%。当 shared_buffers 较大时,往往需要相应提高 max_wal_size,以避免检查点过于频繁。
shared_buffers 过小会导致脏页频繁被淘汰,引发后端写盘;设置过大则可能在检查点时一次性刷新大量页面,造成 I/O 峰值。合理的 shared_buffers 配合 BGWriter 调优,可以显著减少后端写入。
自动清理(Autovacuum) 与 冻结清理(Vacuum Freeze)
自动清理(Autovacuum)在更新可见性信息或冻结元组(Freeze)时,也会产生脏页。应确保 Autovacuum 运行频率足以防止表膨胀,但又不过于激进,以免产生不必要的写入。可根据业务负载调整 autovacuum_vacuum_cost_limit 和 autovacuum_vacuum_scale_factor。在 SSD 环境下,适当提高 Autovacuum 强度通常是有益的。
面向性能的调优实践
1. 先监控,再调优
通过 pg_stat_bgwriter 重点关注以下指标:
buffers_checkpoint:检查点写出的脏页数量。buffers_clean:BGWriter 写出的页面数量。buffers_backend:后端进程写出的页面数量。
目标是将 buffers_backend 控制在接近 0 的水平。
2. 合理配置共享缓冲区大小
以物理内存的 25% 作为起点,根据负载特征调整:
- 若业务场景以读操作为主,可适当增大共享缓冲区。
- 若写操作导致检查点产生大幅性能波动,则需调小共享缓冲区。
3. 调整 BGWriter 参数
- 降低
bgwriter_delay参数值(如设置为 100 毫秒),提高后台写入器的唤醒频率。 - 针对高写入负载场景,增大
bgwriter_lru_maxpages(建议取值范围 200–1000)与bgwriter_lru_multiplier(建议取值范围 3–4)参数,提升单次周期内的脏页处理能力。 - 将
bgwriter_flush_after参数设为与存储系统最佳写入粒度匹配的值;对于固态硬盘,512KB–1MB 为推荐取值区间。
4. 优化检查点行为
- 增大
checkpoint_timeout参数,降低检查点触发频率(建议取值范围 15–60 分钟)。 - 将
checkpoint_completion_target参数提升至 0.7–0.9,使检查点的写入操作均匀分布。 - 增大 max_wal_size 参数,避免检查点被过度频繁触发。
5. 避免后端写入
当 buffers_backend 持续增长时,应优先增加 shared_buffers 或增强 BGWriter 的写盘能力。后端写盘往往是查询延迟的主要来源。
6. 操作系统层面优化
- Linux 系统中,应避免
vm.dirty_background_ratio和vm.dirty_ratio设置过高,以免内核长时间累积脏页,造成突发写回。 - 关闭透明大页(THP),并在内存充足的服务器上启用静态大页(Huge Pages),以提升整体性能。
7. 持续评估与迭代
不同业务负载差异较大,应结合 pg_stat_activity、pg_stat_bgwriter 以及 PostgreSQL 17 引入的 pg_stat_io 等视图,持续评估调优效果,并逐步调整参数。
总结
“脏页”本质上是 PostgreSQL 内存中等待写回磁盘的已修改数据页。通过脏页机制,PostgreSQL 能够合并写入操作,并借助 WAL 保证崩溃安全性。但如果相关参数配置不当,脏页处理可能引发 I/O 峰值和查询延迟。
深入理解共享缓冲区、后台写进程、检查点与 WAL 的协同机制,并合理调优 bgwriter_delay、bgwriter_lru_maxpages、bgwriter_lru_multiplier、checkpoint_timeout、shared_buffers 等关键参数,有助于在保障数据可靠性的同时,实现平稳、可预测的数据库性能。
原文链接:
https://stormatics.tech/blogs/what-are-dirty-pages-in-postgresql
作者:Umair Shahid

















 1976
1976

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









