



本文整理自 IvorySQL 2025 生态大会暨 PostgreSQL 高峰论坛的演讲分享,演讲嘉宾:Florents Tselai。
引言
从 SQL 到 AI,从数据库操作到大模型推理,技术在不断进化。本文将探讨如何在保持稳定性的前提下,利用 SQL 与 AI 接口实现高效、可靠的数据处理。
关于作者
Florents Tselai 拥有数据分析与数据工程背景,早年就读于商学院,随后逐步转向数据工程领域,专注于 PostgreSQL 扩展开发与 AI 数据处理。
曾为欧洲及美国多家企业提供数据咨询服务,目前担任 希腊政府 AI 孵化计划的技术顾问。其研究方向涵盖 PostgreSQL 可扩展性、ETL 工具设计与 AI 数据接口优化。
代表作品:
- PostgreSQL 扩展
- 统计类:pgxicor, vasco
- ETL 工具:pgPDE, pgJQ
创新项目:
- spat:让 PostgreSQL 像 Redis 一样使用共享内存的高性能存储扩展
- pghaicker:基于 AI 的 pgsql-hackers 邮件摘要工具
背景:从复杂中回归极简
极简主义 = 经验 + 麻烦。
复杂的运维流程与多系统环境常使开发过程面临协作障碍与效率损耗。长期的项目实践与问题积累,逐渐催生出一种“极简主义”技术理念——在复杂中求简,以最少且最可靠的工具应对最多的场景。
SQL、Bash 与 Python 成为跨环境开发的核心支撑,体现了高稳定性、高效率与强可移植性的技术哲学。
接口的演进:从 SQL 到 AI
在软件开发与数据分析中,接口(Interface)是核心概念。
SQL:可靠的数据接口
SQL 是数据操作中最稳定、最可靠的核心工具,自 1970 年代以来,它通过标准化方式将人类需求转化为数据库执行计划,实现从查询到报表的完整流程。
SQL 的接口特性:
- 描述“想要什么”,而非“如何实现”。
- 数据表提供直观可视化表示。
- 标准化操作(尽力而为)。
- 从查询到报表完整流程。
- 隐藏底层复杂性。
- EXPLAIN PLAN 提供有限洞察。
AI:自然语言与推理的新接口
AI 接口是 SQL 接口理念的延伸与升级。与 SQL 类似,AI 将人类意图转化为可执行操作,但能够理解自然语言,进一步降低操作门槛。
AI 的接口特性:
- 理解自然语言描述:可生成查询或执行计划,实现直观的人机交互。
- 执行与智能推理:除了生成执行计划,还可处理复杂数据和逻辑推理。
- 延续 SQL 接口哲学:只需描述需求,系统负责实现,但方式更自然、更智能。
从 SQL 到 AI,这一演进体现了接口的核心理念:让人类与系统交互更直观、高效,同时隐藏底层复杂性。AI 接口不仅延伸了 SQL 的能力,也为未来的数据分析与应用开发提供了新的可能。
核心转变:从执行计划到推理计划
在高级用户操作 AI 的实践中,可以观察到执行计划与推理计划的一一对应关系。用户通过一个提示词得到结果,再将结果组合或优化,这本质上是在编排推理逻辑,而不仅是执行操作。这些结果可以作为缓冲或中间状态,实现更高效的任务管理。
现状批判:LLM 框架的陷阱
复杂的生态与过度抽象
- 对普通用户而言,AI 操作像魔法,简化了复杂任务。
- 对数据工程师或开发者而言,部署和操作仍然复杂,需要理解系统底层逻辑。
这一差异反映了用户体验的便利性与开发者实际操作复杂性之间的落差。
当前大模型生态尚未稳定,技术迭代速度过快,主要表现为:
- 行业仍缺乏统一标准与稳定范式。
- 经验方法更新频率高,难以长期复用。
- HOW-TO 类资料常因工具与版本更新而被替代。
- 各模型都声称性能领先,但实际效果依赖具体场景。
- 不同 LLM 框架试图定义自己的标准路径,却往往引入更高的复杂度和学习成本。
历史的押韵:LLM Frameworks = ORMs
LLM 框架类似 80 年代的 ORM(对象关系映射):
- ORM 虽提供了 SQL 的抽象封装,但底层执行原理仍需掌握。
- LLM 框架提供抽象化接口,但早期依赖可能掩盖底层逻辑。
- 当前框架过度封装、复杂化流程,使开发者容易迷失。
LLM 框架虽便利,但存在显著问题:
- 过度自信与复杂化 —— 框架自认为万能,却增加不必要的复杂性;
- 死板抽象 —— 多层封装让问题难以理解;
- Java 式设计泛化 —— 流程被强制框架化,增加学习成本;
- “想要香蕉?先建宇宙” —— 为完成简单任务,需要经历冗长复杂步骤;
- 强制流程 —— 框架规定操作步骤,限制灵活性;
- 阻碍学习 —— 用户依赖框架而非理解底层逻辑;
- 产生挫败感 —— 框架让用户觉得无法掌控,体验不佳。
整体结论:LLM 框架目前仍是辅助工具,开发者不应盲目依赖,应理解底层原理并培养核心技能。
SQL 依然是最稳定的答案
面对快速发展的 AI 技术生态,开发者常常需要寻找稳定可靠的解决方案。尽管出现了各种新兴工具和框架,SQL 依然被证明是数据访问和处理的核心接口。
SQL 自诞生以来数十年,始终保持其核心价值。尽管有人宣称 SQL 已过时,每隔十年总有新论断出现,但 SQL 的基础地位从未动摇,其声明式语法和标准化特性使其在复杂系统中长期可靠。
SQL 不仅仅是查询语言,更可以视作系统的编排者。在处理复杂数据流程时,SQL 能将不同任务和操作整合为清晰的执行计划,从而简化系统协调和资源管理的复杂性。
在 AI 应用中,模型的推理流程与 SQL 的执行计划存在对应关系。通过 SQL 的结构化操作,可以对 AI 推理过程进行有效映射与管理,使数据处理和推理逻辑保持一致性。
回归本质:AI 即相似度搜索
当前大模型(LLM)及各类 AI 应用,从底层机制来看,核心都可以归结为“相似度搜索”。其基本流程是:
- 将输入文本切分成 tokens;
- 通过向量化模型生成向量表达;
- 存储的数据向量进行相似度比对,
- 最终根据得分返回结果。
这一过程并不神秘,模型能力的差异主要取决于数据规模与训练质量。
在实际应用中,系统会在数据库内存储多种信息片段,并不断围绕“向量—相似度—检索”循环工作。从业务角度看,AI 的执行流程更像是“声明—比对—迭代”的模式:给定输入,不断检索最接近语义结果,再多轮迭代优化。
核心机制
当前 AI 技术生态中最常见的术语如 tokens、vectors、documents,均围绕相似度检索机制展开。
- tokens:文本最小单元
- vectors:语义向量表示
- documents:文档或数据片段
Postgres 早已具备的能力
尽管今天的向量检索听起来前沿,但对于数据库从业者而言,这一思想并非全新。PostgreSQL 在十余年前就已经通过全文检索(Full Text Search)实现了类似能力。例如:
SELECT 'a fat cat sat on a mat'::tsvector @@ 'cat & rat'::tsquery;
全文检索的流程同样依赖文本分词、构建词典、生成向量化表示,并在查询时根据词项匹配进行判定。不同之处仅在于:
- 过去依赖的是本地语料构建的词典与向量;
- 现在依托的是规模更大的语言模型语料与向量空间。
从技术原理上看,这两者在语义表达与匹配流程上的一致性非常明显。因此,LLM 并不是完全改变数据库世界的“新物种”,而是将“相似度检索”做到规模更大、语义更丰富、泛化能力更强。
AI 实战:上下文即一切
多层封装的体系结构
现代 AI 应用普遍构建在大模型框架之上,外层工具与平台不断叠加新的包装与接口,形成“套娃式”的技术结构。绝大多数产品并非从零实现,而是围绕底层模型进行 API 封装、功能抽象与产品化组合。
底层核心:llama.cpp
在这些封装层的最底部,llama.cpp 等核心实现承担模型推理的基础执行职责。其高性能、轻量化与良好兼容性,使其成为大量应用的实际运行基础。围绕相关代码库,社区生态与开源许可问题也构成技术讨论的重点。
上下文的重要性
在实际使用中,影响模型效果的关键因素依然是上下文处理能力。上下文长度决定了模型能够加载的数据量,也直接影响推理结果的完整性与连续性。在早期上下文窗口有限的阶段,复杂的数据裁剪与拼接流程不可避免;而随着上下文上限不断提升,数据组织方式与调用策略也随之调整。
构建提示词 = 数据连接的艺术
在大模型应用中,上下文构建已成为决定模型效果的核心环节。模型能够输出高质量结果的前提,是输入数据经过精确筛选、裁剪与组织。实际业务中,这一过程本质上是数据 Join 的组合工程。
在客户服务、电商等常见场景中,约 80% 的工作是从数据库中挑选关键字段,包括商品描述、用户属性、业务要点等,并剔除无关内容。通过将这些信息压缩为清晰的文本表示后,即可形成模型的输入上下文。该过程强调数据组织能力,而非复杂算法。
基于字符串的模板化构建方式
上下文的构建主要依赖字符串拼接与模板化处理。SQL 的格式化函数、标准的字符串模板引擎等工具即可完成大部分处理需求。相比构建复杂脚本或 Notebook 环境,这种方式更直接、更高效,并满足绝大多数生产实践场景。
将复杂度交给模型处理
在设计提示词或业务流时,不必在应用层堆叠大量逻辑判断或格式规约。大模型具备强大的推理与补全能力,适合承担复杂推断工作。应用层应主要聚焦于准备精简、准确的输入数据,将复杂度交由模型处理,从而提升系统整体效率与可维护性。
Everything in PostgreSQL:减少链路
通过 PostgreSQL 的扩展生态,可以将多种形态的数据处理直接集成到数据库内部,从而减少跨系统的数据搬运、降低额外的同步压力,并提升整体系统稳定性。
解析 PDF:非结构化数据提取
借助 pgPDF 扩展,PostgreSQL 能够直接读取本地或远端 PDF 文件并将其解析为文本。示例如下:
github.com/Florents-Tselai/pgPDF
CREATE EXTENSION pgpdf;
SELECT '/path/to/my.pdf'::pdf;
执行 HTTP 请求:获取外部数据
利用 http 扩展,可以在 PostgreSQL 内直接发起 API 请求,例如:
CREATE EXTENSION http;
SELECT http_post('http://myprovider');
这一能力使数据库能够直接完成部分外部数据的获取流程,从而减少应用端的多次 I/O 往返,降低数据链路的复杂性。需要注意的是,HTTP 请求存在阻塞和失败的可能,因此更适合在非核心业务节点或离线库中使用。
将文本解析、外部 API 请求等操作整合到数据库内部,可以减少:
- 数据在系统间传输带来的延迟
- 应用层的额外逻辑与依赖
- 由于链路增长导致的失败点
从而提升整个数据链路的可靠性与可维护性。
Unix 哲学在现代数据处理中的价值
Unix Philosophy
Unix 哲学强调以最小单元构建工具,通过清晰的接口协同完成复杂任务。这一思想在当下依然具有实践意义,特别是在数据密集型场景中。
“Do One Thing Well” 与文本接口
Unix 哲学的核心原则包括:
- 工具专注于单一功能
- 文本作为通用接口
在 LLM 与数据库协作的场景中,文本仍然是最稳定、最易组合的接口形式。这也使得传统工具链在新的技术背景下依然适用。
管道化的工具组合
遵循 Unix 的方式,小工具之间通过管道组合,能够以极低的复杂度完成高效的数据处理流程。
常见工具组合方式
在实际工程中,以下工具链可以覆盖大量数据拉取、处理与写入场景:
- curl:用于获取本地或远程 API 数据
- jq:处理 JSON 结构
- xargs(含并行执行):用于批量或并行处理
- psql:直接与 PostgreSQL 交互
这些工具组合后,可以在极少代码量的前提下实现高效的流水线式处理。
示例:真实项目示例
以下示例来自实际项目,通过 Makefile 驱动整套数据处理流程:
- 生成时间区间;
- 拉取与分组数据;
- 构建 JSON 数据;
- 向量化处理(如使用某 embedding 模型);
- 将结果写回 PostgreSQL。
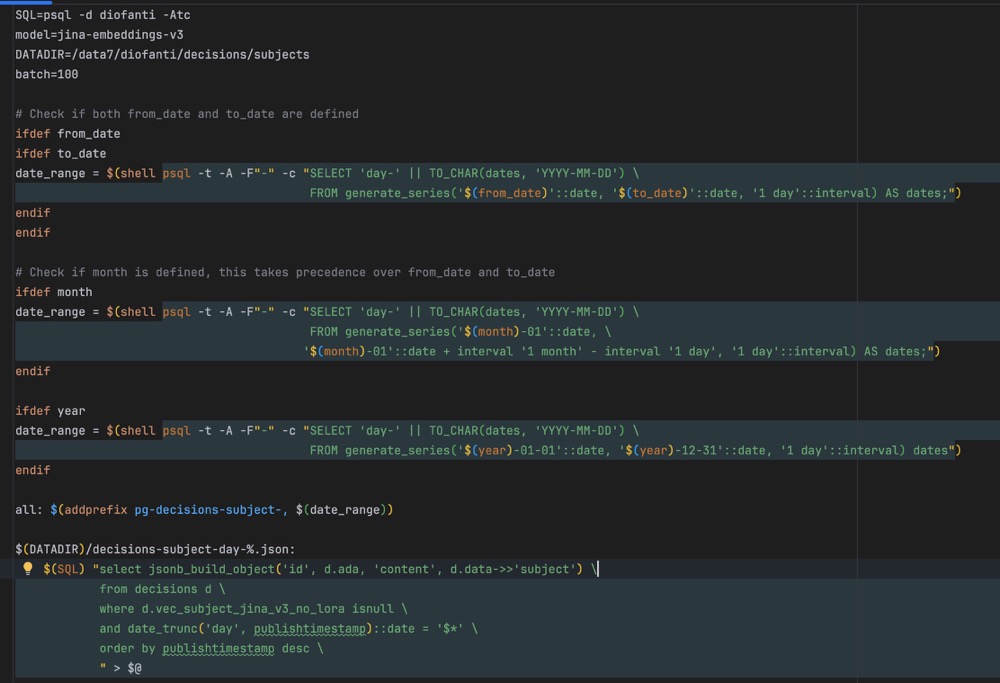
整个流程以 JSON 作为中间格式,以 PostgreSQL 作为状态与结果的统一存储,避免了额外的数据搬移与逻辑分散。
示例:命令行操作 PostgreSQL 实现数据流水线
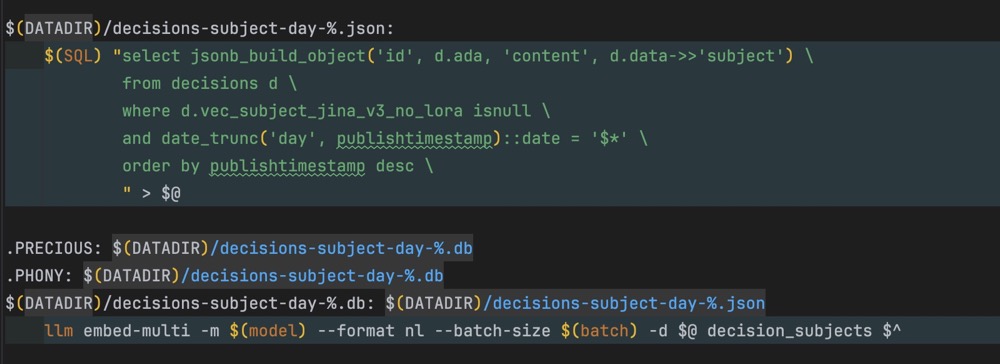
在实际项目中,通过命令行工具直接操作 PostgreSQL,实现数据处理自动化:
- 使用 % 通配符灵活查询数据。
- 本地 LLM 对数据进行处理,如生成每日聚合结果。
- 为每一天生成独立 PostgreSQL 数据库,将结果写入数据库。
- 利用命令行管道直接写回数据库,实现数据流闭环,无需额外搬移。
示例:LLM 结合的处理逻辑
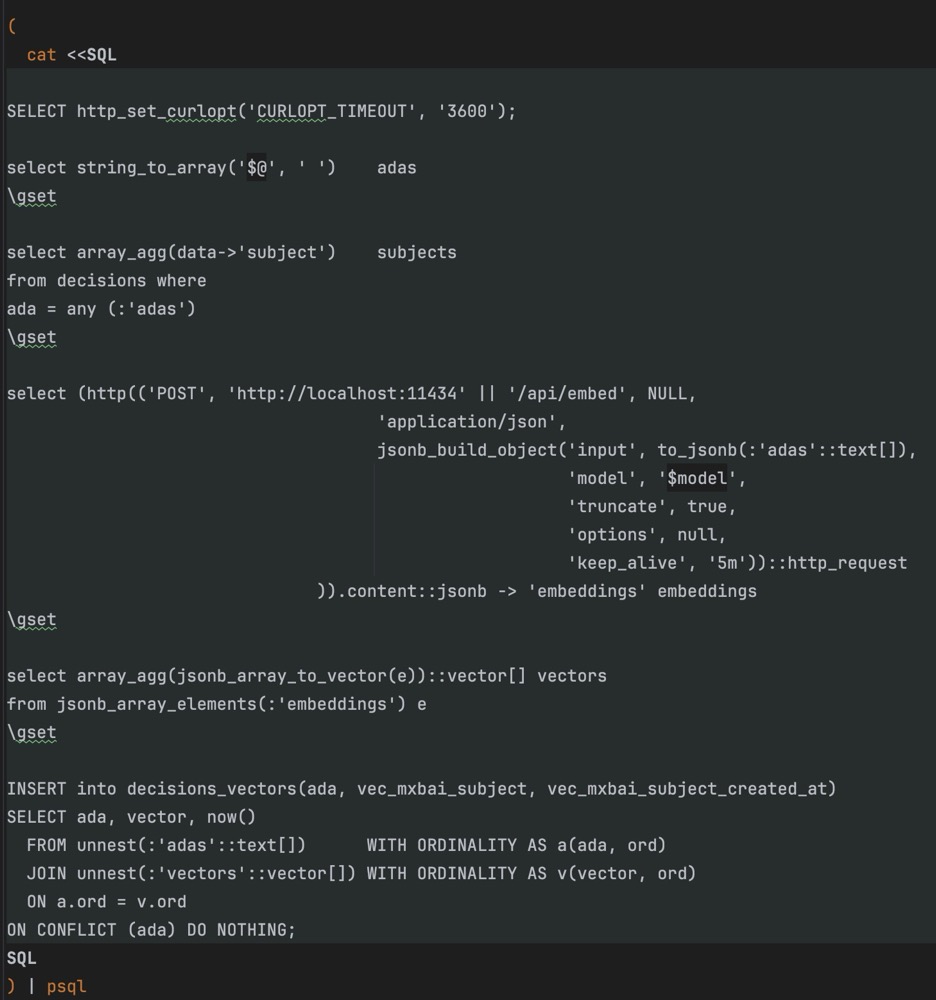
本地 LLM 对文本、集合或结构化数据进行处理和聚合,生成有用信息并向量化,结果直接写入 PostgreSQL。利用数据库索引和聚合能力完成优化,实现从数据处理到存储的自动化闭环。
结语
SQL 与 AI 的结合展示了简化复杂、提升效率的价值。理解底层原理并合理运用工具,才能在快速变化的技术生态中保持掌控与高效。

















 5602
5602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









