



本文整理自 IvorySQL 2025 生态大会暨 PostgreSQL 高峰论坛的演讲分享,演讲嘉宾:李传成,walminer 作者。
本文内容主要包括:
- 逻辑解码的基本原理
- 高级逻辑解码特性
- walminer 数据恢复实战
- walminer pgto server 实战
逻辑解码的基本原理
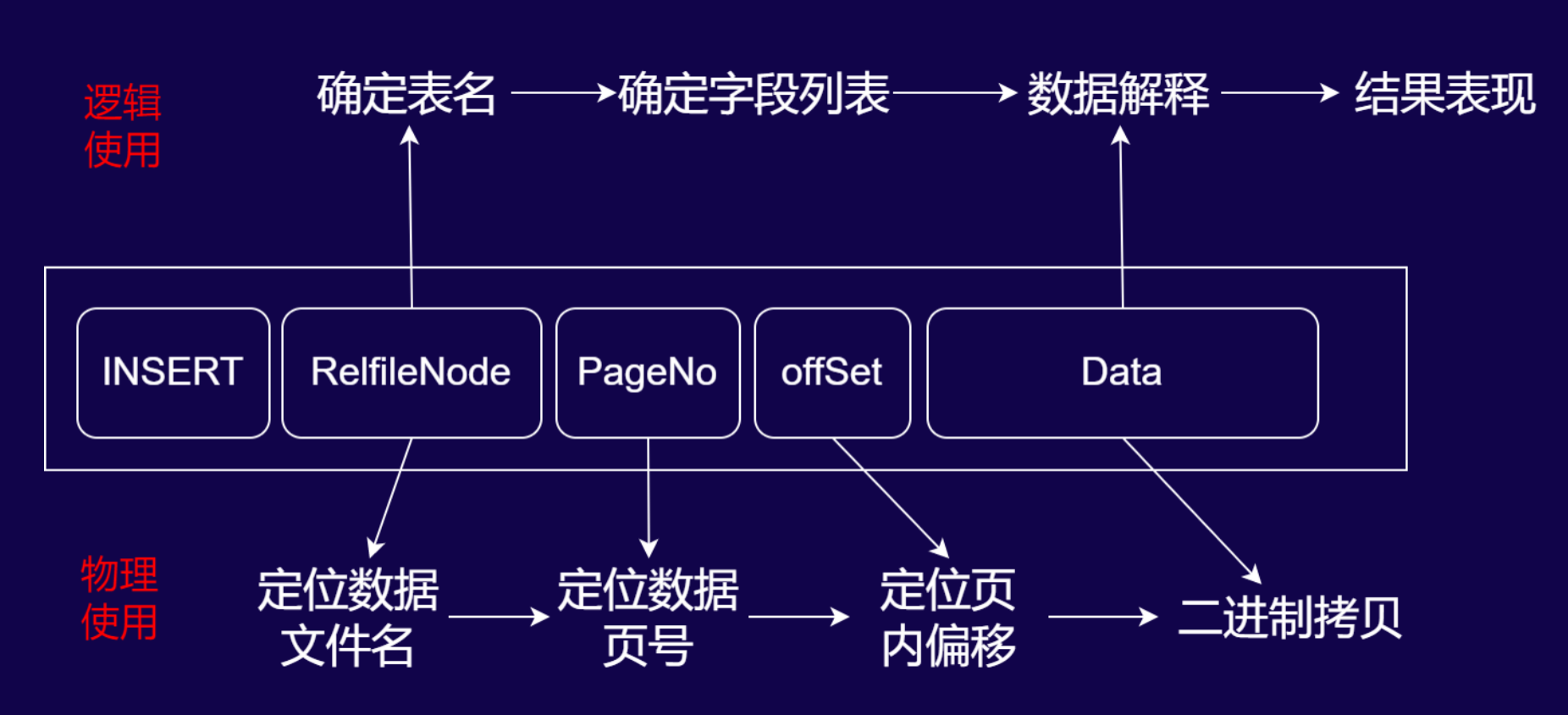
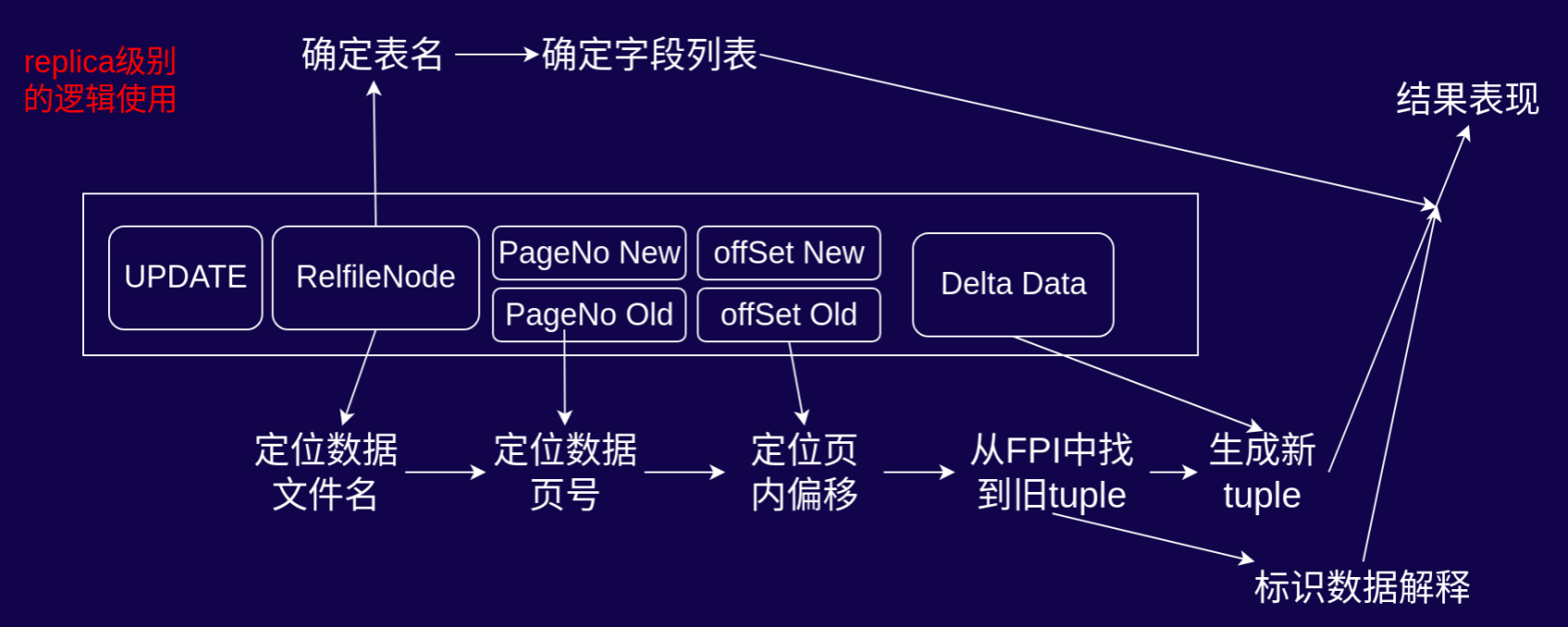
数据库 INSERT 操作的 WAL 日志解析与使用流程
物理使用(二进制回放流程)
当数据库执行INSERT操作时,WAL 日志会记录以下关键信息,用于物理层面的数据回放:
- RelfileNode:定位数据文件名(对应数据库中存储表数据的物理文件,如带后缀的表文件标识)。
- PageNo:定位数据页号(确定数据在物理文件中的具体页位置)。
- offSet:定位页内偏移(确定数据在页内的具体位置)。
- Data:存储 INSERT 操作的二进制数据内容。
流程逻辑为:通过RelfileNode找到数据文件 → 由PageNo定位到文件内的页 → 借助offSet确定页内数据位置 → 最终对Data进行二进制拷贝,完成物理层面的日志回放(如备库同步、数据库重启恢复时的底层数据还原)。
逻辑使用(可读数据解析流程)
若需将 WAL 日志解析为人类可读的逻辑数据,流程如下:
- 确定表名:通过
RelfileNode关联数据库数据字典(如 PostgreSQL 的系统表),查询其对应的模式(Schema)和表名。 - 确定字段列表:根据表名,从系统表(如
pg_attribute)中获取该表的字段定义(字段名、类型等)。 - 数据解释:基于字段列表,解析
Data中存储的二进制数据,还原出 INSERT 操作的具体数据内容(如“插入了哪些列、对应什么值”)。 - 结果表现:通过解码插件(如
wal2json、test_decoding的格式化输出),将解析结果以可读形式呈现(如 JSON、文本格式)。
数据库 DELETE 操作的 WAL 日志解析与使用流程
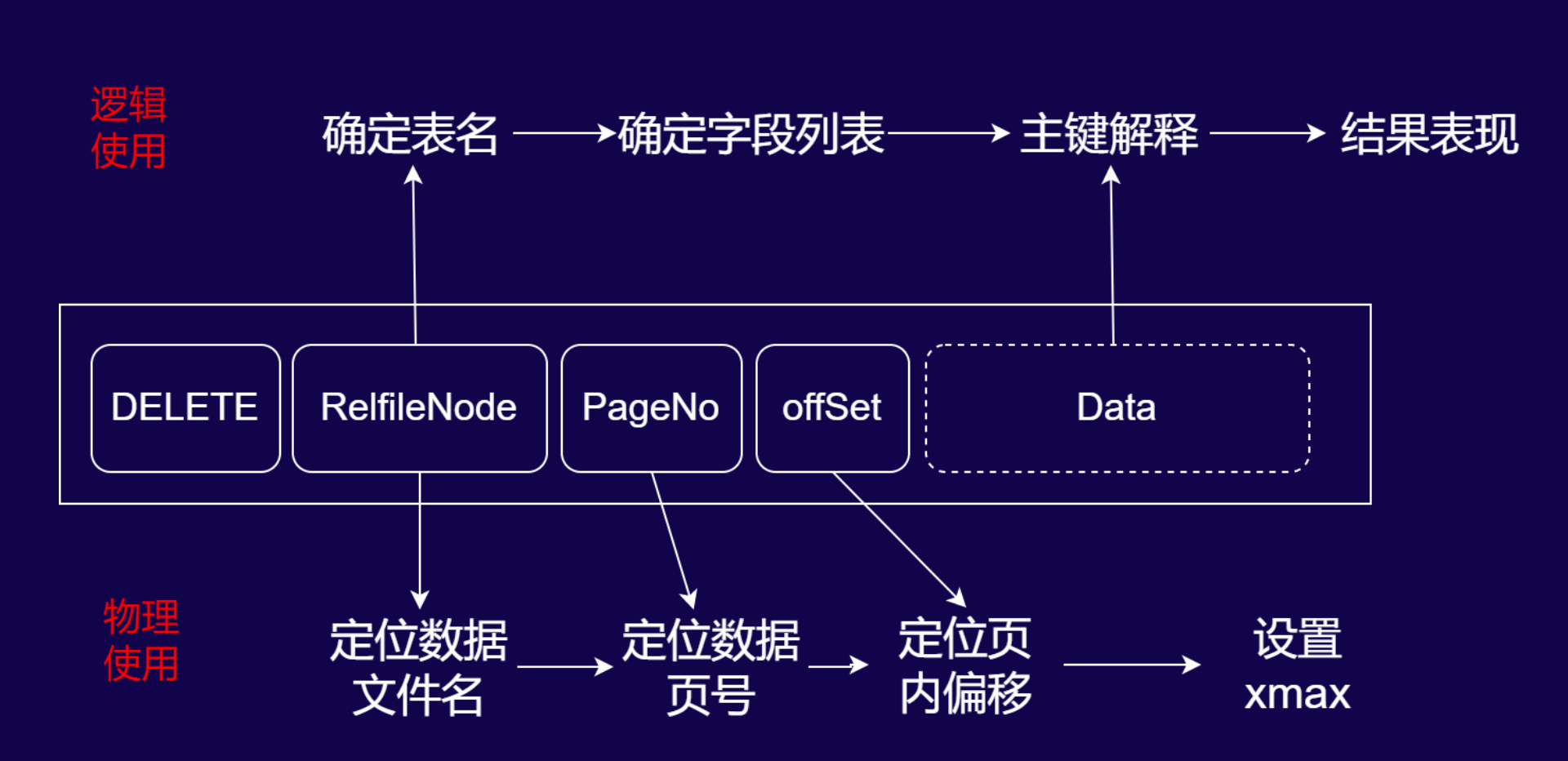
WAL 日志结构说明
DELETE 操作的 WAL 记录由以下核心元素构成:
- DELETE 标识:明确操作类型为删除。
- RelfileNode:用于定位数据文件的唯一标识。
- PageNo:数据页在物理文件中的编号。
- offSet:页内偏移量,精准定位待删除行。
- Data(可选):内容随 WAL 级别(物理/逻辑)动态变化,逻辑日志中通常包含主键定位信息。
物理使用:底层删除标记流程
物理层面的 WAL 回放用于实现数据的底层删除标记,流程如下:
- 定位数据文件:通过
RelfileNode确定对应的物理数据文件。 - 定位数据页:借助
PageNo找到文件内的目标数据页。 - 定位行偏移:通过
offSet定位页内待删除的行。 - 标记删除:对目标行的头部设置
xmax(事务标识),完成物理层面的删除标记(该流程用于数据库恢复、备库同步等场景,保障底层数据结构的一致性)。
逻辑使用:可读删除条件解析流程
若需将 DELETE 日志解析为人类可读的逻辑操作,流程如下:
- 确定表名:通过
RelfileNode关联数据字典(如 PostgreSQL 系统表),确定操作的目标表。 - 确定主键字段列表:DELETE 操作仅需主键字段即可唯一定位行,因此需解析表的主键定义。
- 主键解释:从日志中提取主键的具体值,还原出“删除哪一行”的逻辑条件。
- 结果表现:通过解码插件(如
wal2json)将结果格式化为可读形式(例如“DELETE FROM 表名 WHERE 主键=XXX”)。
数据库 UPDATE 操作的 WAL 日志解析与性能影响
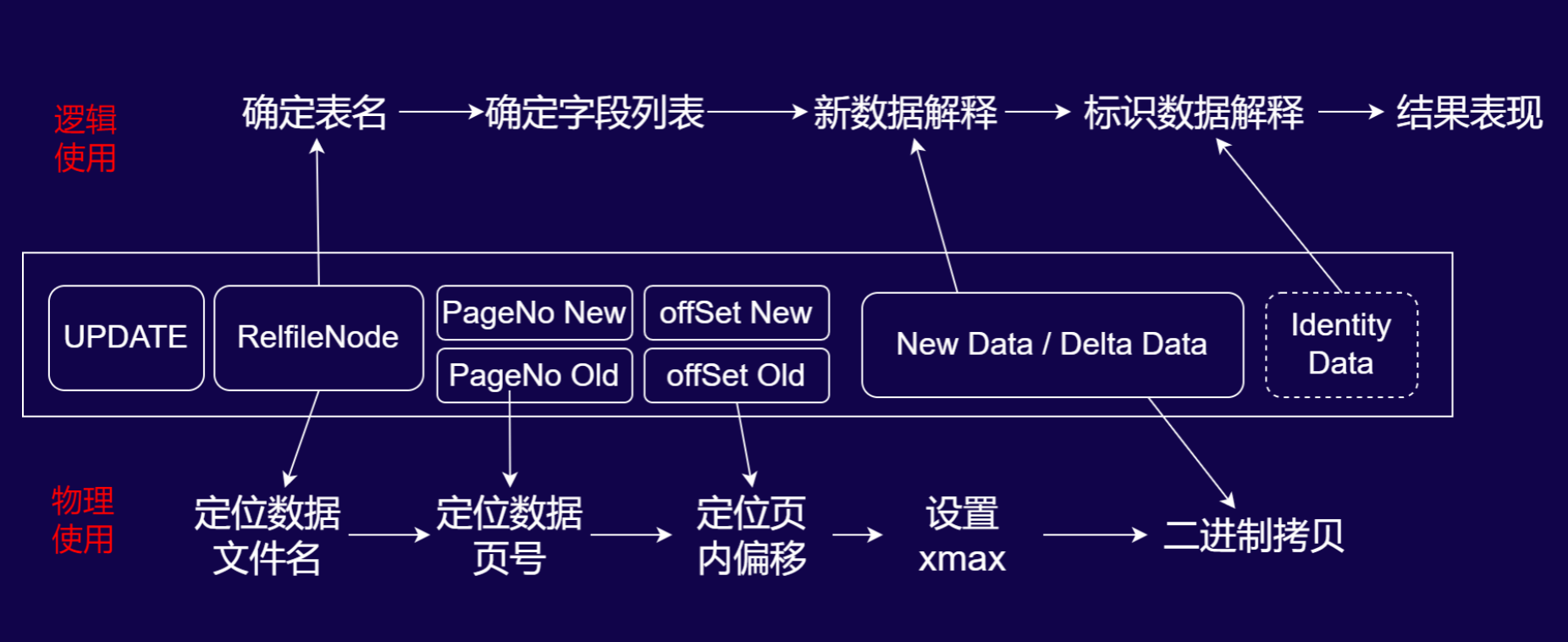
UPDATE 的 WAL 日志结构(“旧行删除 + 新行插入”的组合设计)
UPDATE 操作的 WAL 记录包含以下核心元素,体现“旧行标记删除、新行插入”的底层逻辑:
- UPDATE 标识:明确操作类型为更新。
- RelfileNode:定位数据文件的唯一标识。
- PageNo Old/offSet Old:定位旧行在物理文件中的页和偏移。
- PageNo New/offSet New:定位新行在物理文件中的页和偏移。
- New Data / Delta Data:存储新行的完整数据或仅变更的增量数据。
- Identity Data(可选):独立存储用于条件判断的标识字段(如主键)。
物理使用:底层更新的二进制流程
物理层面的 WAL 回放严格遵循“旧行标记删除 + 新行二进制插入”的步骤:
- 旧行标记删除:通过
PageNo Old和offSet Old定位旧行,设置其xmax(事务标识),完成逻辑删除标记。 - 新行二进制写入:通过
PageNo New和offSet New定位新行位置,将New Data/Delta Data以二进制形式直接拷贝写入;若为 Delta Data(增量数据),则先提取旧行基础数据,覆盖变更字段后再完成新行写入。
逻辑使用:数据解析与日志膨胀风险
逻辑层面需将 UPDATE 日志解析为可读的更新操作,同时需关注逻辑日志级别下的 WAL 膨胀问题:
- 表与字段定位:通过
RelfileNode关联数据字典确定表名,再从系统表中获取该表的全数字段列表(逻辑日志级别下,无论实际更新字段多少,均会存储全字段数据)。 - 新数据与标识数据解释:
New Data:逻辑日志级别下,即使仅更新 1 个字段,也会存储表中所有字段的新值(这是 WAL 日志膨胀的核心诱因)。Identity Data:独立存储用于条件判断的标识字段(如主键);若表的标识级别配置为full,还会额外存储所有旧字段值,进一步放大日志体积。
- 日志膨胀案例:以“100 字段表仅更新 1 个字段”为例,逻辑日志会存储 100 个新字段值 +(若为 full 标识级别)100 个旧字段值 + 独立的 Identity Data,导致 WAL 日志膨胀率达 200%以上,对存储和性能影响显著。
WAL 记录的内容变种
INSERT 操作在不同 WAL 级别下的日志结构与差异

1. 核心概念说明
- FPI(Full Page Image):全页镜像,PostgreSQL 在 WAL 中记录的整页数据,用于应对“页面撕裂”场景的恢复一致性。
- replica 级别/系统表:面向物理复制或系统表操作的 WAL 配置,聚焦底层数据的物理一致性。
- logical 级别:面向逻辑解码(如数据审计、逻辑复制)的 WAL 配置,需解析出人类可读的逻辑操作。
2. replica 级别(或系统表)的 INSERT 日志结构
根据是否包含 FPI,日志结构分为两种:
- 不带 FPI:日志包含
INSERT标识、RelfileNode(数据文件标识)、PageNo(页号)、offSet(页内偏移)、Data(新插入的二进制数据)。该结构用于常规插入场景,依赖 WAL 的增量记录保障一致性。 - 带 FPI:日志包含
INSERT标识、RelfileNode、PageNo、offSet、FPI(整页数据镜像)。此时不存储Data,恢复时直接通过 FPI 覆盖整页,适用于“页面撕裂风险高”的场景(如 checkpoint 间隔大时)。
3. logical 级别(逻辑解码)的 INSERT 日志结构
逻辑级别下的 INSERT 日志存在数据冗余设计:
- 带 FPI 时,日志同时包含
FPI(整页数据)和Data(新插入数据)。从设计合理性看,FPI 本身已包含页面数据,本可直接用于逻辑解码的信息提取,却额外存储Data,造成 WAL 日志膨胀。 - 该冗余对性能的影响与
checkpoint配置强相关:若checkpoint配置密集(触发 FPI 的场景少),则性能影响微乎其微;若checkpoint间隔大(FPI 频繁触发),则可能因冗余加剧 WAL 写入压力,此时优化该设计(复用 FPI 进行逻辑解码)可带来一定性能提升。
DELETE 操作在不同 WAL 级别下的日志结构与差异

1. 核心概念回顾
- FPI(Full Page Image):全页镜像,用于物理层面的页面一致性恢复。
- Identity Data:标识数据(如主键),用于逻辑解码时唯一定位被删除的行。
- replica 级别/系统表:聚焦物理复制或系统表操作的 WAL 配置,保障底层数据物理一致性。
- logical 级别:面向逻辑解码的 WAL 配置,需解析出可读的删除条件。
2. replica 级别(或系统表)的 DELETE 日志结构
根据是否包含 FPI,日志结构分为两种:
- 不带 FPI:日志包含
DELETE标识、RelfileNode(数据文件标识)、PageNo(页号)、offSet(页内偏移)。该结构下,DELETE 操作仅需定位行后设置xmax(事务标识)即可完成物理层面的删除标记,无需额外数据存储。 - 带 FPI:在上述基础上加入
FPI(全页镜像)。此时通过 FPI 覆盖整页来保障“页面撕裂”场景下的物理一致性,恢复时直接以全页镜像还原数据。
3. logical 级别(逻辑解码)的 DELETE 日志结构
逻辑级别下的 DELETE 日志需满足“可读删除条件”的解析需求,结构如下:
- 不带 FPI:日志包含
DELETE、RelfileNode、PageNo、offSet,并额外加入Identity Data(标识数据,如主键)。Identity Data用于逻辑解码时明确“删除哪一行”的条件(如DELETE FROM 表名 WHERE 主键=XXX)。 - 带 FPI:同时包含
FPI(保障物理恢复)和Identity Data(服务逻辑解码)。FPI 满足底层页面一致性,Identity Data 满足逻辑行定位需求,二者结合支撑物理与逻辑的双重场景。
UPDATE 操作在不同 WAL 级别下的日志结构与逻辑解码要点
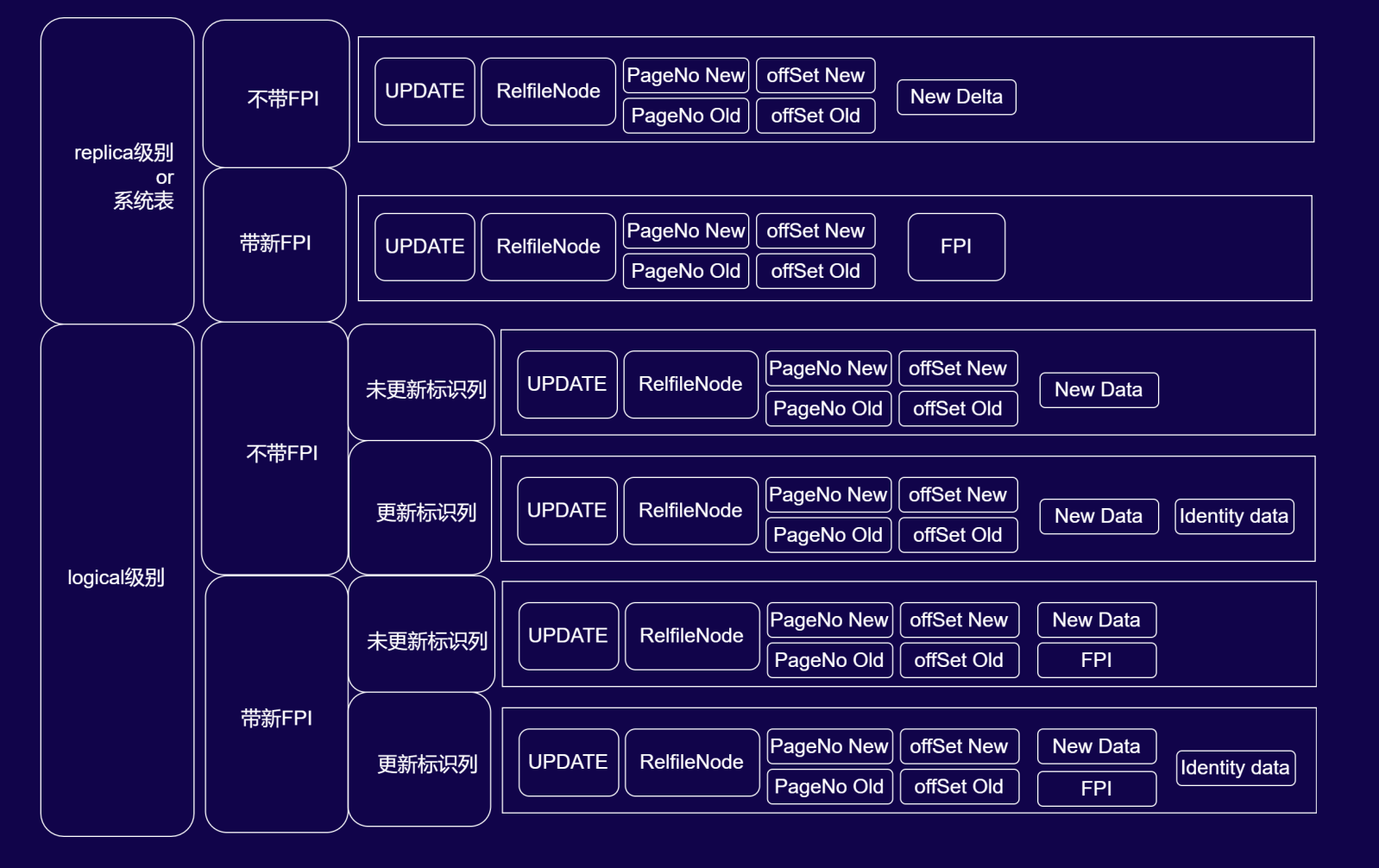
1. replica 级别(或系统表)的 UPDATE 日志结构
UPDATE 在 replica 级别下的日志可理解为“INSERT + DELETE”的物理层面组合,结构分为两种:
- 不带 FPI:日志包含
UPDATE标识、RelfileNode(数据文件标识)、PageNo New/offSet New(新行定位)、PageNo Old/offSet Old(旧行定位)、New Delta(新行的增量数据)。仅记录变更的增量信息,保障物理复制的高效性。 - 带 FPI:将
New Delta替换为FPI(全页镜像),通过整页覆盖实现“页面撕裂”场景下的物理一致性恢复,此时不存储增量数据,直接依赖 FPI 完成新行的二进制写入。
2. logical 级别(逻辑解码)的 UPDATE 日志结构(按“是否带 FPI”“是否更新标识列”细分)
逻辑级别下的 UPDATE 日志因标识列是否更新和是否启用 FPI呈现复杂差异,这也是逻辑解码易踩坑的核心场景:
- 不带 FPI:
- 未更新标识列:日志包含
UPDATE、RelfileNode、新旧PageNo/offSet、New Data(新行全量数据)。因标识列未更新,逻辑解码时可直接从New Data中提取标识列(如主键),无需额外存储旧数据。 - 更新标识列:在上述基础上新增
Identity Data(标识数据,如更新后的主键)。此时标识列被修改,需单独存储新标识以明确“更新后的数据归属”,逻辑解码时通过Identity Data定位新行的标识条件。
- 未更新标识列:日志包含
- 带 FPI:
- 未更新标识列:日志包含
UPDATE、RelfileNode、新旧PageNo/offSet、New Data、FPI。FPI保障物理层面的页面一致性,New Data服务逻辑解码的新行数据解析。 - 更新标识列:在上述基础上再新增
Identity Data,同时满足“物理页面恢复(FPI)”“新行数据解析(New Data)”“标识列变更定位(Identity Data)”三重需求。
- 未更新标识列:日志包含
3. 逻辑解码的避坑要点
在解析 logical 级别 UPDATE 日志时,需重点关注标识列是否更新:
- 若未更新标识列,
New Data中已包含标识信息,无需额外依赖旧数据即可定位行。 - 若更新标识列,需通过
Identity Data明确新标识,否则易因标识列变更导致数据关联错误。
这一设计细节是 PostgreSQL 为平衡“逻辑可读性”与“存储效率”的权衡,也是逻辑解码开发中需重点理解的技术坑点——只有明确标识列的更新状态,才能准确解析“更新了哪一行、更新后的数据是什么”的逻辑语义。
高级逻辑解码实现
我们常遇到以下三个问题:
- logical 日志级别带来的 wal 膨胀
- UNDO 语句生成
- DDL 变更捕获
如何解决这 3 个问题呢?那么就要依靠高级逻辑解码实现。
在物理复制中,使用磁盘上切实存在的 tuple 作为变更受体完成 delete 或者 update 操作,而在逻辑解码中因为无法确定的在当前 wal 中找到 tuple 变更受体。因而需要额外记录大量的新旧数据来完成逻辑变更数据的确定。
PG 依赖 FPW 体系,这意味着当前 WAL 记录前序相对不远的 WAL 中,一定存在本 WAL 修改的 page 的全页。这将使在 replica wal 级别下做逻辑解码变为可能。
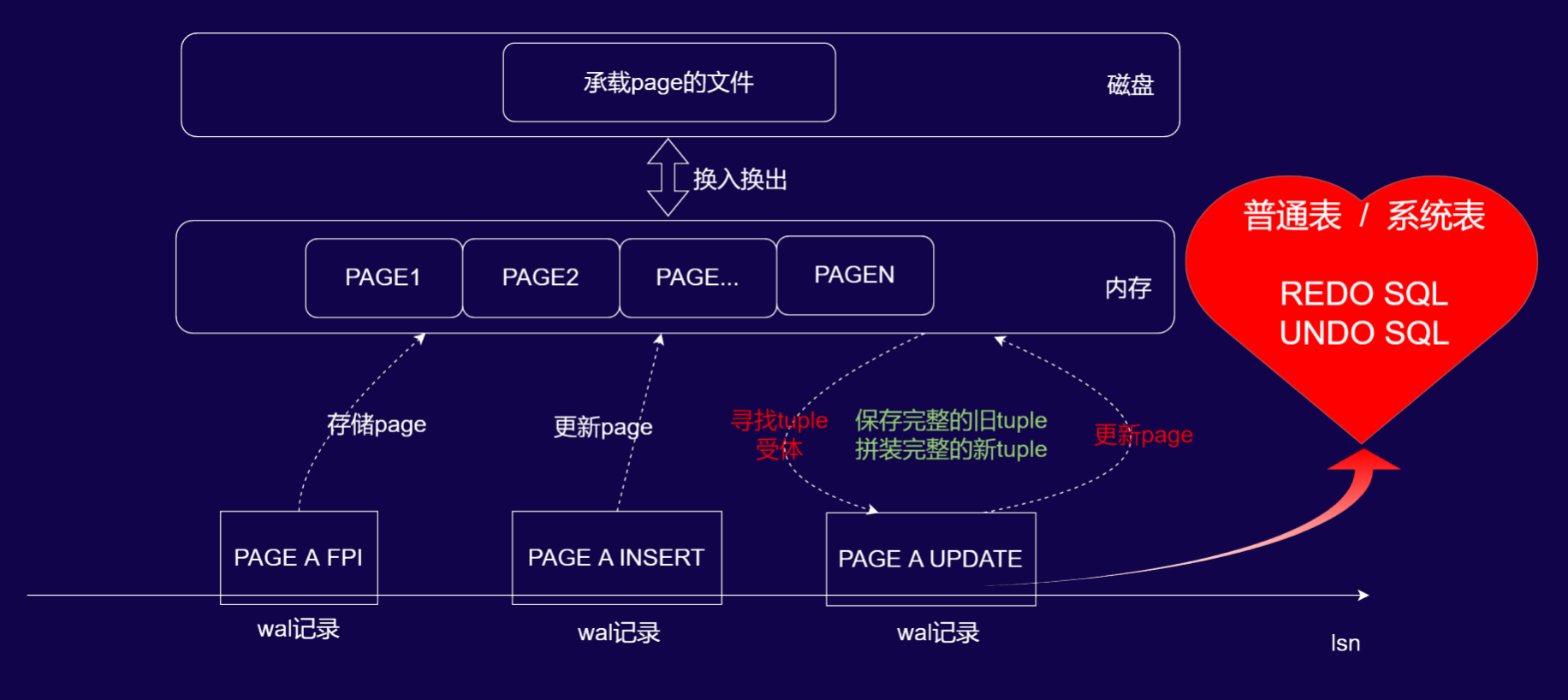
基于 WAL 日志的分层存储与内存管理机制,逻辑解码工具可通过以下流程,在 logical 级别下实现REDO SQL 与 UNDO SQL 的生成:
-
FPI 内存缓存
当工具解析到带 FPI(全页镜像)的 WAL 记录(如
PAGE A FPI)时,会将该 FPI 对应的页数据完整缓存至内存,建立“页标识-全页数据”的映射关系,为后续元组(tuple)定位提供基础。 -
同页操作的旧 tuple 定位
当解析到针对同一 page(如 PAGE A)的写入类 WAL 记录(如
PAGE A INSERT或PAGE A UPDATE)时,工具从内存缓存的 FPI 中定位到操作对应的旧 tuple(元组)(即“寻找 tuple 受体”的过程)。 -
新旧 tuple 拼装与 SQL 生成
- 基于旧 tuple 的结构,结合 WAL 记录中的新数据(如 INSERT 的 Data、UPDATE 的 New Delta),拼装出完整的新 tuple。
- 利用旧 tuple 生成UNDO SQL(用于回滚操作),利用新 tuple 生成REDO SQL(用于重演操作),从而在 logical 级别下完成逻辑解码,实现数据变更的语义级解析。、
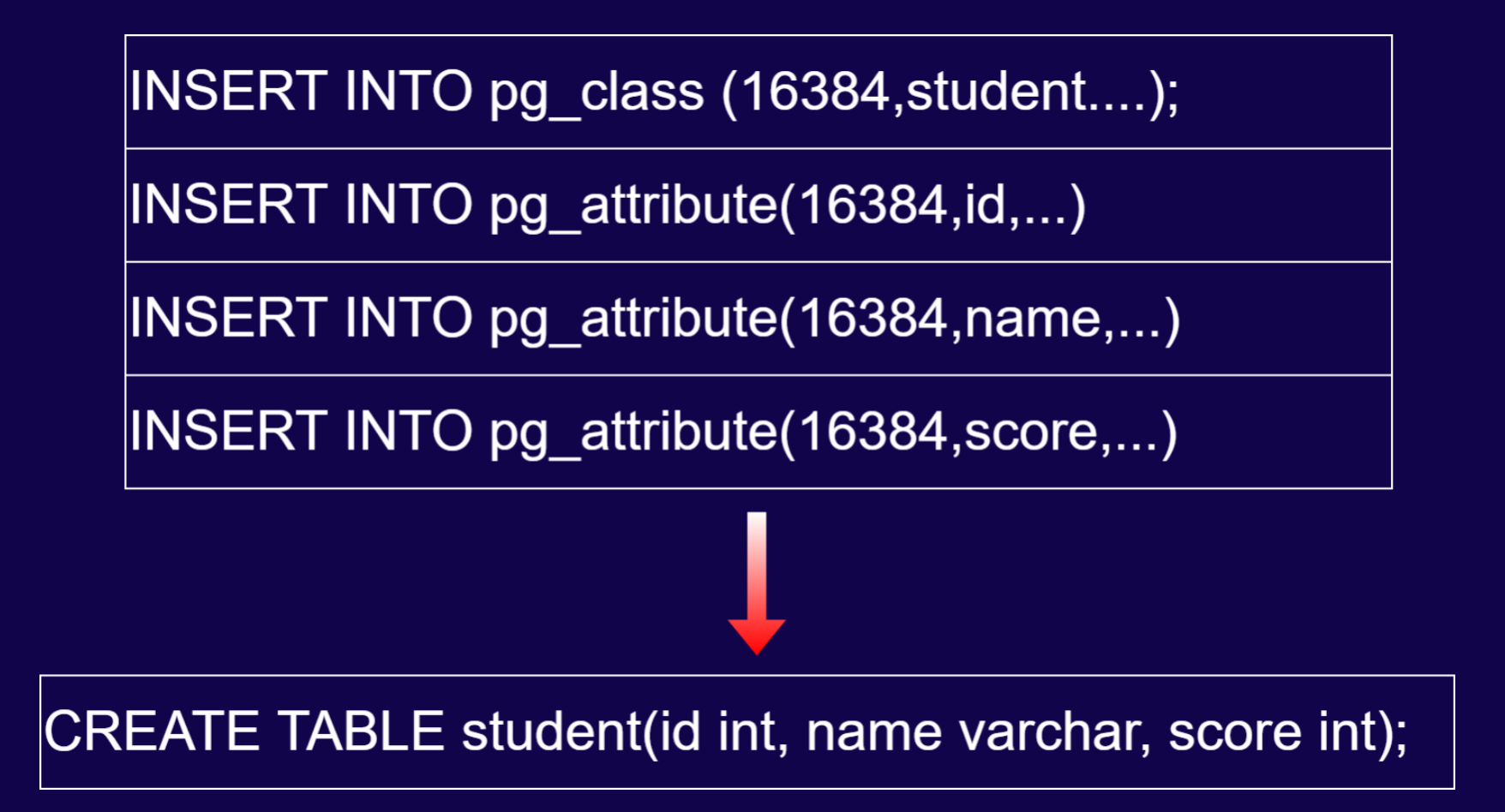
上述操作既能解析普通表,也能解析系统表,那么我们也可以解析出一条语句来。
向 pg_class 中插入一条数据,其 oid 如上图所示,向 pg_attribute 中插入一行数据,其字段如上图所示。那么我们即可拼出上图最下方的 DDL。
基本上所有的 DDL 都可以通过这种方式去找到复原方法,这就是在 replica 级别完成 DDL 解码的过程。
WALMINER
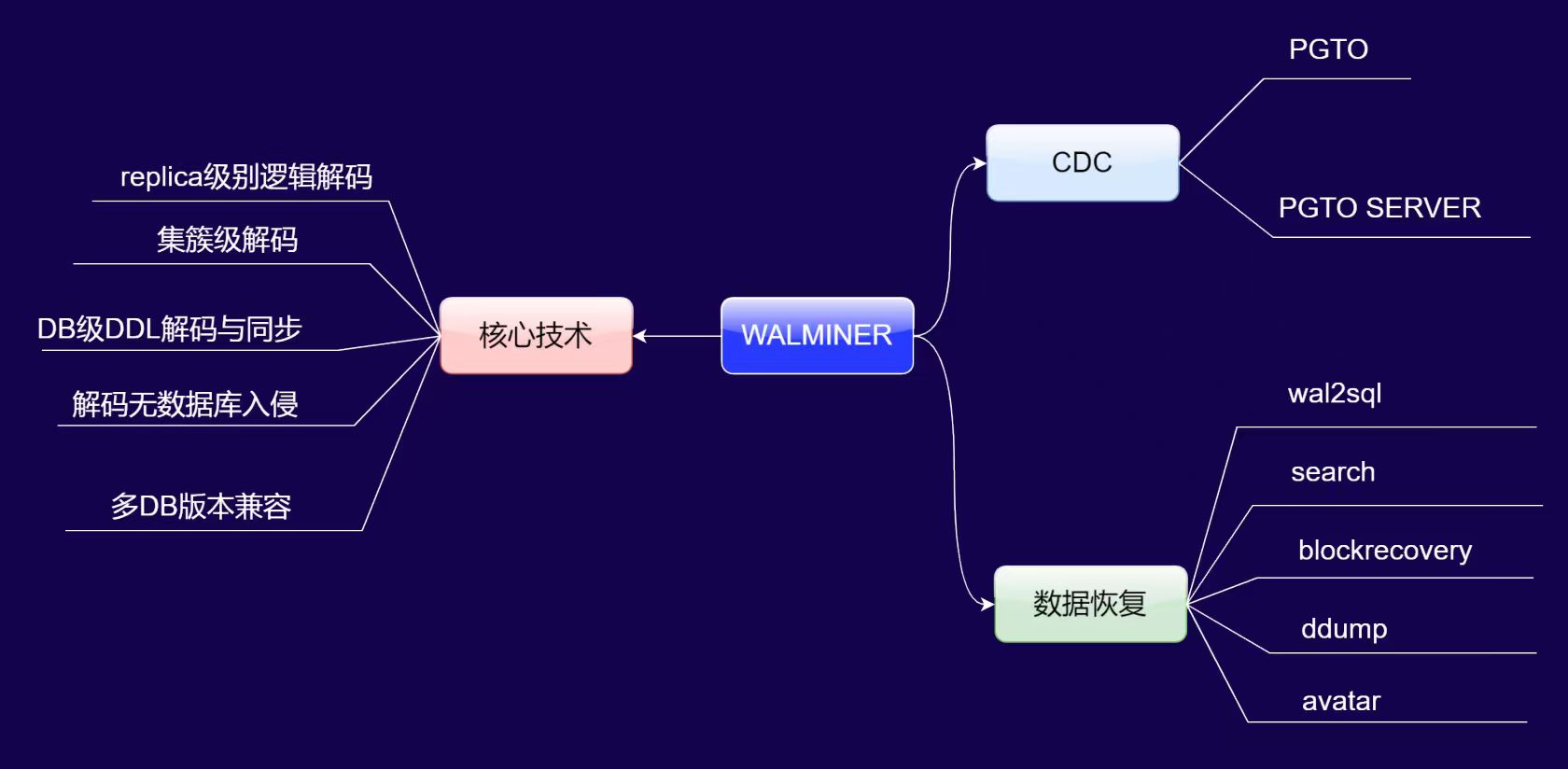
WALMINER 的核心技术与产品应用
一、核心技术优势
WALMINER 的核心技术突破体现在以下四点:
- replica 级别逻辑解码与实例级批量处理:可在 replica 日志级别完成逻辑解码,且支持“一次读取 WAL 日志,完成多 DB 实例(如 DB1、DB2、DB3)的批量解码”,效率显著提升。
- DB 级 DDL 动态识别与同步:无需预先生成数据字典,对新创建的数据库、表等 DDL 操作可自动识别,业务侧无需执行初始化或订阅修改操作,适配性极强。
- 无数据库入侵设计:作为独立工具,不依赖数据库内部能力,可脱离 PG 运行环境部署,对数据库资源无侵占,避免了传统解码工具对数据库性能的影响。
- 多版本全兼容:单工具支持 PG 10 至 PG 18 全系列版本的 WAL 日志解码,降低了多版本环境下的工具适配成本。
二、产品应用场景
基于核心技术,WALMINER 衍生出CDC(变更数据捕获)和数据恢复两大产品方向:
1. CDC(变更数据捕获)
- PGto:端到端的数据同步 demo 方案,仅需两条命令即可完成跨 PG 版本(如 PG 10→PG 17)的数据同步,操作极简但暂为 demo 级别,适合测试场景。
- PGto server:商用级服务化方案,功能等价于“wal2json”中间件,可通过接口获取逻辑槽内的 SQL 变更,已在多家企业实现生产级落地。
2. 数据恢复
- wal2sql:提供 WAL 日志的 SQL 解码命令,为数据恢复提供基础解析能力。
- search 工具:解决“海量 WAL 日志中定位误操作位点”的行业痛点,可快速锁定数据误操作的时间或逻辑位置。
- blockrecover 命令:针对数据库快照、穿刺等紧急场景的高效数据找回方案,依赖基础备份+后续 WAL 日志,恢复速度比数据库原生方式快数十倍。
WALMINER 数据恢复实战
场景:
APP 出现 bug,生成错误的 UPDATE SQL,在操作数据库时导致表 A 更新大量无关数据行。
恢复步骤:
- 生成数据字典
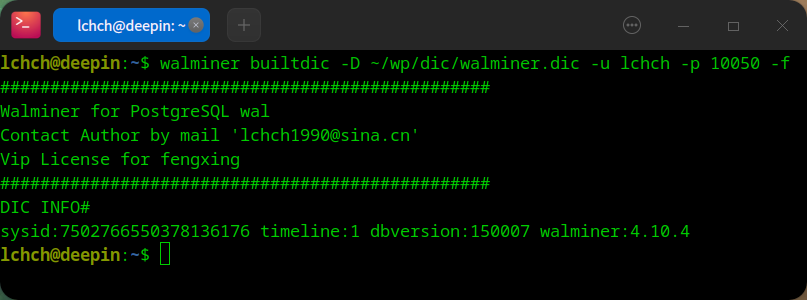
执行一个命令行工具,指定数据字典的位置,指定用户名。
- 检索误操作位点
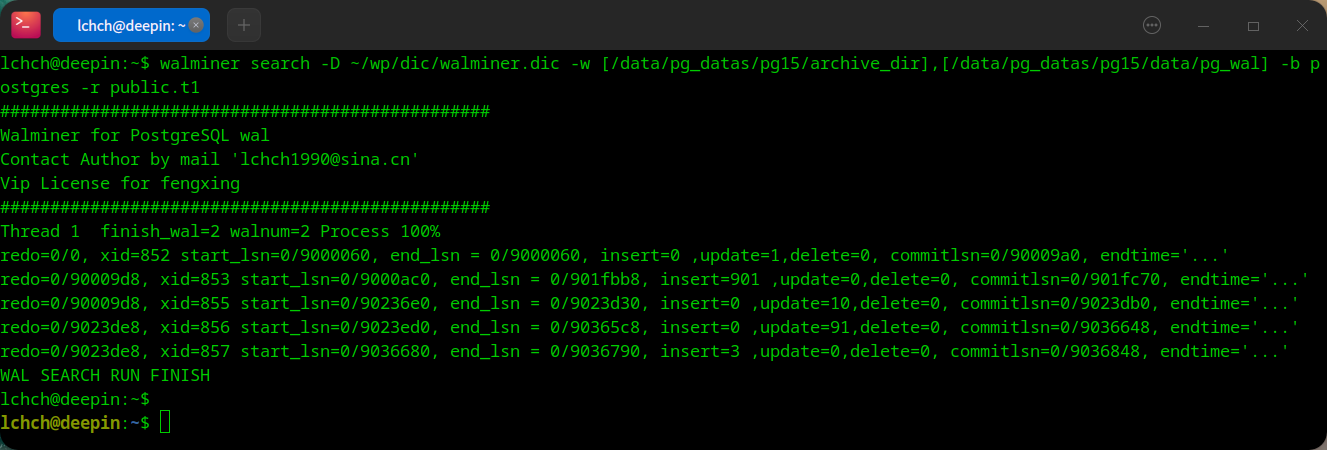
要利用 WALMINER 的search命令定位误操作,可按以下流程操作:
(1) 命令参数配置:执行walminer search时,需指定 -D(第一步生成的数据字典文件)、-w(WAL 日志的生产目录和归档目录列表)、-b(误操作涉及的数据库)、-r(误操作涉及的“模式.表”,如public.t1)。
(2) 自动化分析输出:工具会遍历指定 WAL 日志,输出每个事务的详细统计,包括事务 ID(xid)、LSN 范围(start_lsn/end_lsn)、insert/update/delete 操作次数、提交 LSN 等(如示例中“xid=853 insert=901”“xid=856 update=10”等条目)。
(3) 人工判别误操作:这是流程中唯一需要 DBA 人工介入的环节——需结合操作时间、类型(insert/update/delete)和数据量,从输出的事务列表中识别出误操作对应的事务。
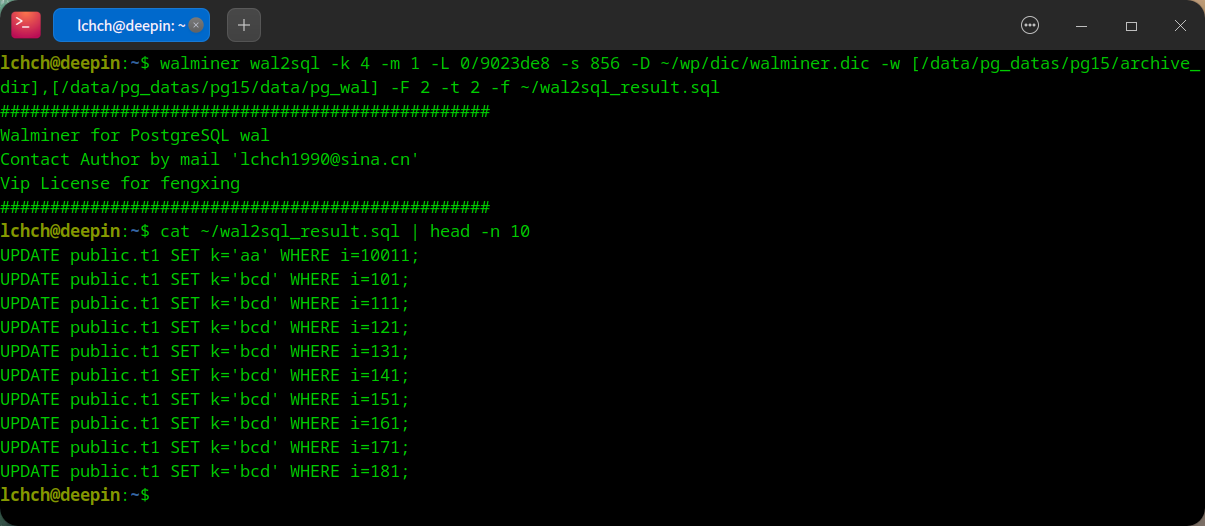
- 精准生成 UNDO SQL
通过 wal2sql 命令,精准的找回 undo 语句,然后人为确定这些语句没有问题,防止出现 bug。
- 恢复数据
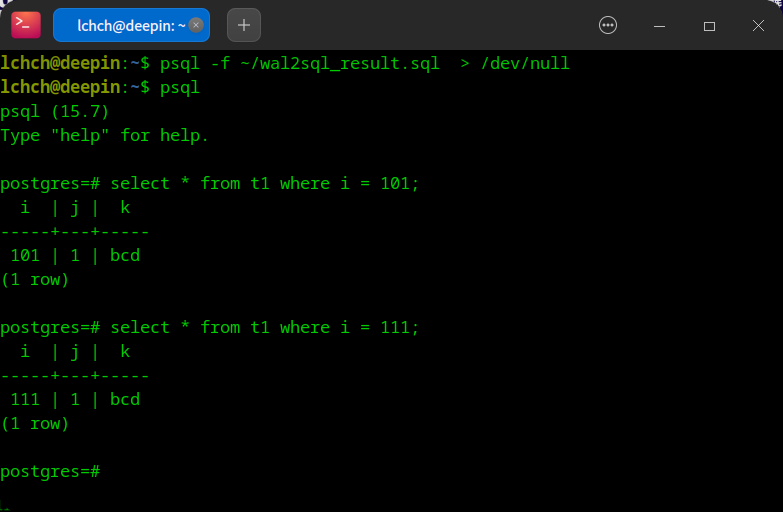
只需通过psql -f命令执行生成的 SQL 恢复脚本(如wal2sql_result.sql),再通过常规 SQL 查询验证数据,整个数据恢复流程操作简洁,即使是数据库新手也能轻松完成。
误操作观察
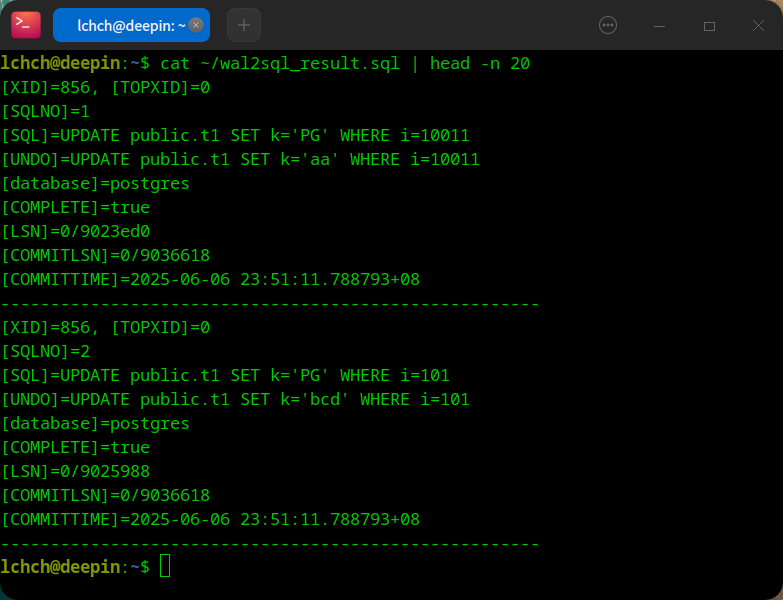
wal2sql 命令 1:
walminer wal2sql -k 4 -m 1 -L 0/9023de8 -s 856 -D ~/wp/dic/walminer.dic -w [/data/pg_datas/pg15/archive_dir],[/data/pg_datas/pg15/data/pg_wal] -F 2 -t 2 -f ~/wal2sql_result.sql
wal2sql 命令 2:
walminer wal2sql -k 4 -m 1 -L 0/9023de8 -s 856 -D ~/wp/dic/walminer.dic -w [/data/pg_datas/pg15/archive_dir],[/data/pg_datas/pg15/data/pg_wal] -t 2 -f ~/wal2sql_result.sql
误操作深度挖掘
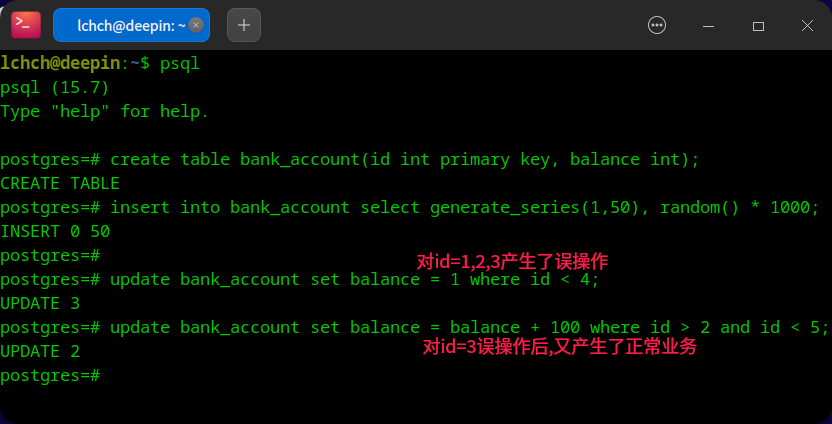
如果误操作了一个表之后又执行了正常的业务,应该如何去恢复数据?
WALMINER
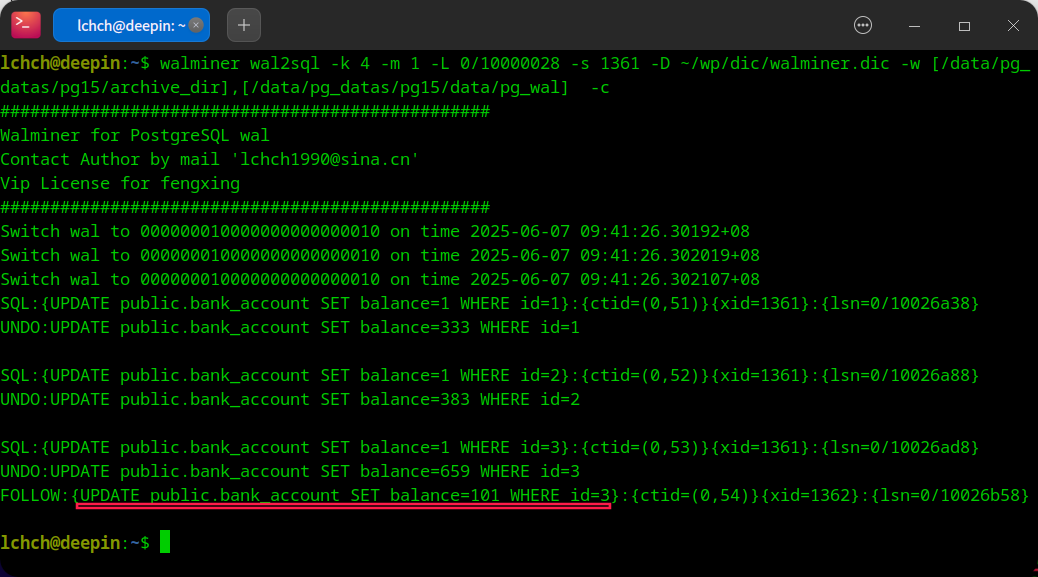
WALMINER 的解决方案可按以下逻辑落地:
- 生成数据字典:先通过工具生成目标数据库的数据字典,为后续解析提供元数据支撑。
- 执行日志检索:定位涉及
bank_account表的 WAL 日志范围。 - 带
-c参数执行wal2sql命令:该参数会触发 WALMINER 的分层事务分析能力,自动列出:- 原始误操作事务(如将
id=1,2,3设为balance=1的更新); - 误操作后对污染数据的后续更新(即“follow 操作”,如
id=3的balance+100操作)。
- 原始误操作事务(如将
用户可基于这些事务明细,人工判定最终应恢复的正确数据状态(例如区分“误操作前的原始值”“误操作后的值”“后续业务更新后的值”)。后续将集成“自动推荐最优 UNDO SQL”功能,无需人工介入即可输出最可能的回滚语句,进一步简化数据恢复的决策流程。
walminer pgto server 实战
pgto 使命
PGTO 致力于极简的 CDC 部署,目前已实现一键式 CDC 部署,可以完成集簇级的数据同步,同时支持新建 DB 实例同步,新建表同步,支持双向同步。
pgto 操作步骤
- 初始化 pgto
- 启动 pgto CDC
pgto server 操作步骤
- 初始化 pgto server
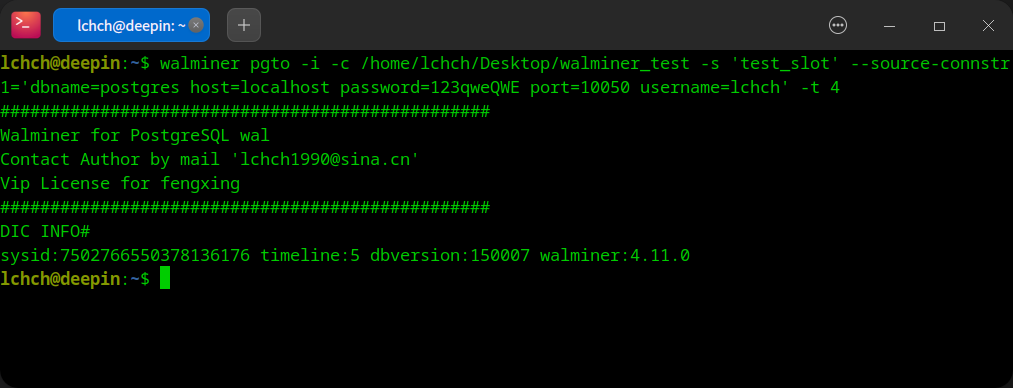
- 创建订阅
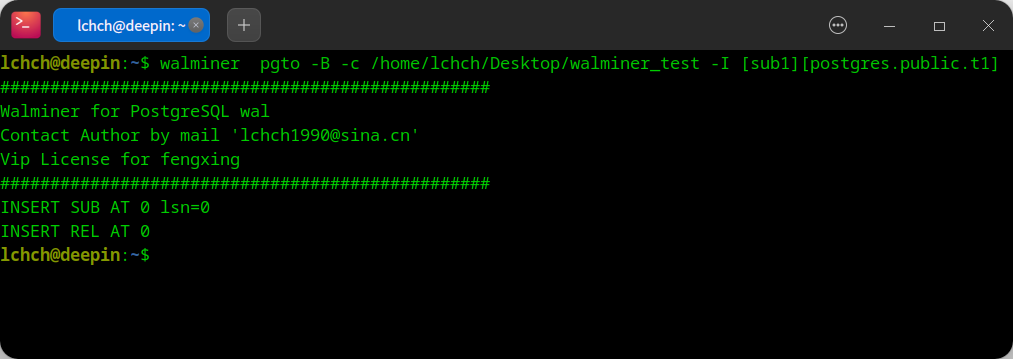
- 启动 pgto server
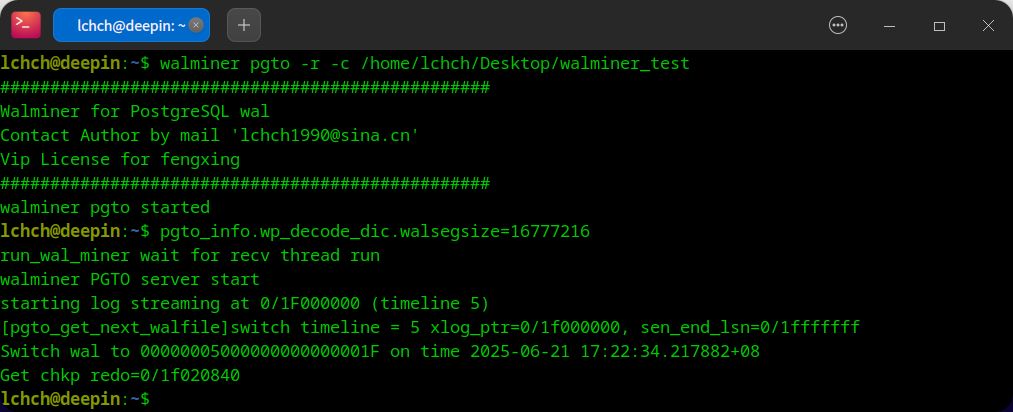
server 运行后的订阅方案:
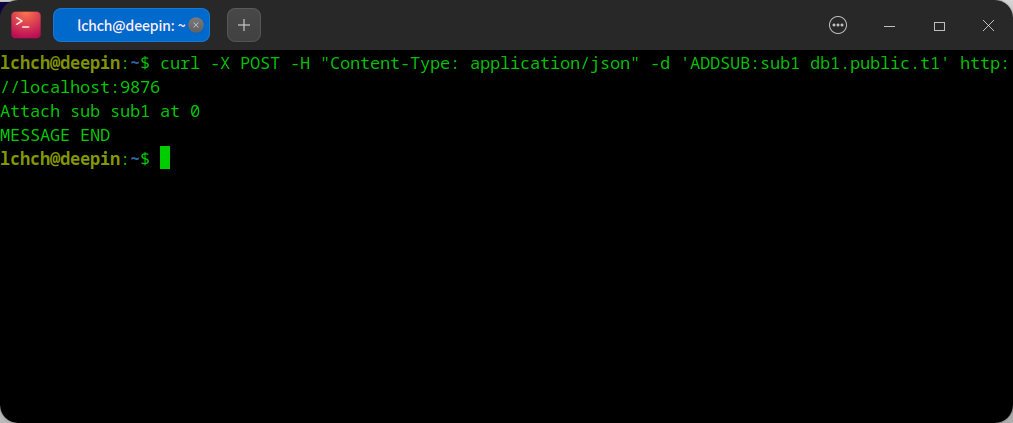
- PGTO 插入测试数据
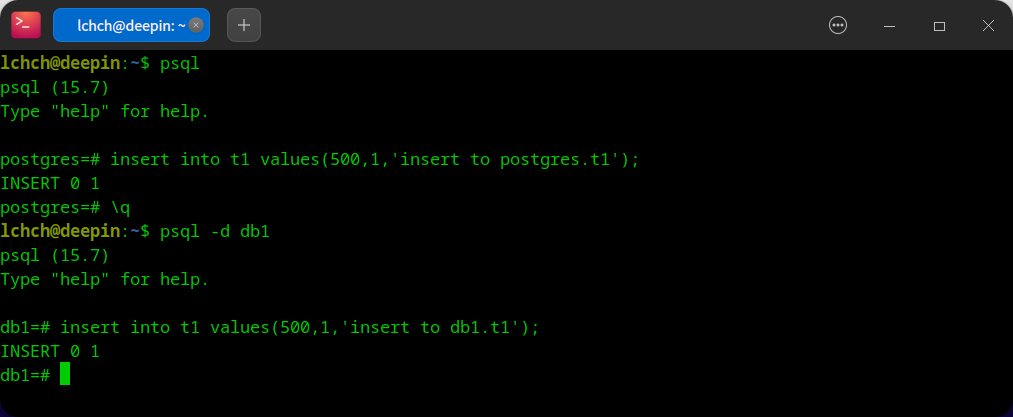
- PGTO server 消费
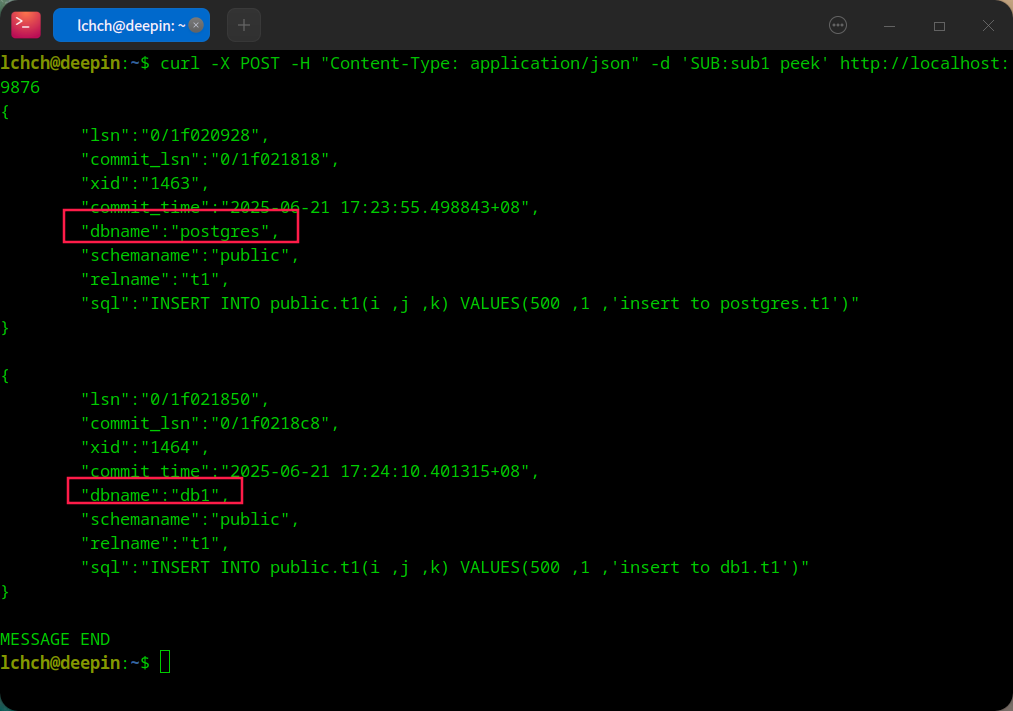
pgto server 优势
- 低 wal 级别
- 生产库 wal 堆积风险低
- 集簇级解析,不占用数据库资源
- DDL 识别

















 2449
2449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









