




❝本文整理自 IvorySQL 2025 生态大会暨 PostgreSQL 高峰论坛的演讲分享,演讲嘉宾:权宗亮。
本文主要包括以下三部分:
-
SeqScan 现状
-
heapam 改进
-
全表计数
SeqScan 现状
我们使用了一个稍宽的 SeqScan 表,包含约 10-20 个字段,记录数达 1,000 万。填充因子约为 50%,生成的数据总计 2.63 GB,占用约 34.5 万块磁盘空间,大致如此。
以下是其尺寸详情:

其执行计划较为简单,包括两个主要操作:一是全表扫描,二是对全表进行 count(*)。
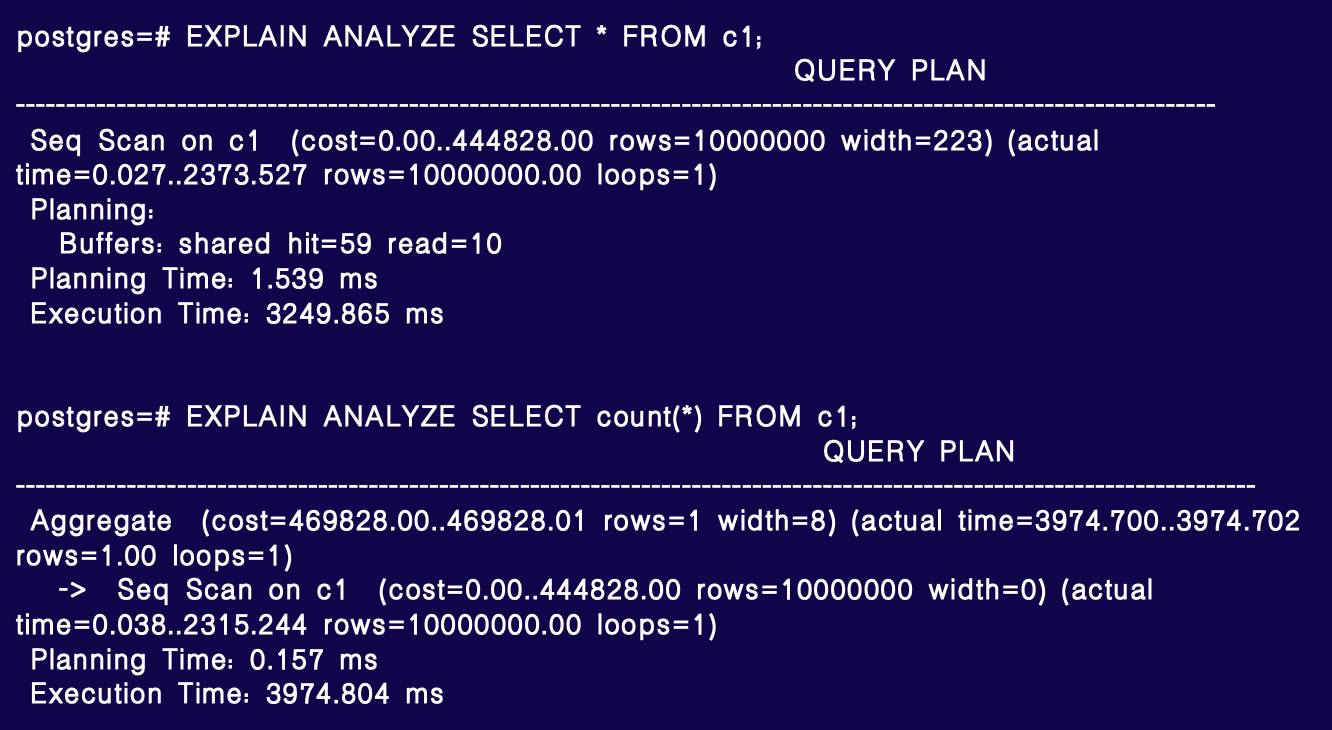
全表扫描的顺序扫描耗时约 2.4 秒,是主要的开销,其余时间可忽略,可能是数据传输开销。
对于 count(*),总耗时约 4 秒,其中顺序扫描(SeqScan) 2.3 秒,占用了大部分时间。
目前来看,这种方式看似不常规,正常情况下较少使用。但在实际场景中,一旦文档中提及相关内容,用户就可能尝试使用。
我们有一位客户,其表包含数千万条记录,业务设计要求每隔一段时间进行全表计数,以统计新增记录数。客户未透露具体业务逻辑,且不愿调整设计。在某些商业数据库(如国产数据库迁移场景)中,客户常提出类似需求,强调现有方案高效(如“某某产品很快”),并要求我们的数据库支持。若试图协商
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









