







 本文介绍了Flink的发展历程,从解决低延迟与准确性问题的Lambda架构升级,到提供精确一次执行保障的流处理器。Flink凭借高吞吐量、低延迟、精确一次状态一致性以及与YARN和Kubernetes的集成,超越了传统的批处理框架如Spark。
本文介绍了Flink的发展历程,从解决低延迟与准确性问题的Lambda架构升级,到提供精确一次执行保障的流处理器。Flink凭借高吞吐量、低延迟、精确一次状态一致性以及与YARN和Kubernetes的集成,超越了传统的批处理框架如Spark。
一、Flink发展
第一代:Storm
低延迟,无法保证准确性以及很难实现高吞吐量。
第二代:Lambda架构
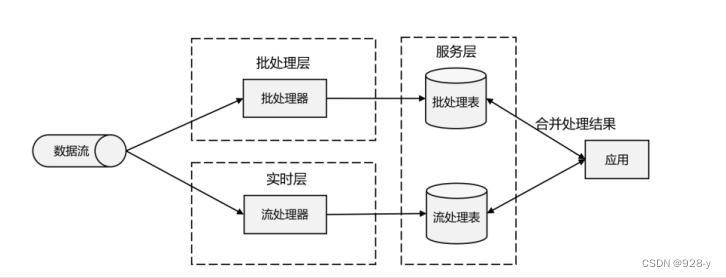
流处理器和批处理器的简单合并,
数据到达
之后,两层处理双管齐下,一方面由流处理器进行实时处理,另一方面写入批处理存储空间,
等待批处理器批量计算。流处理器快速计算出一个近似结果,并将它们写入“流处理表”中。
而批处理器会定期处理存储中的数据,将准确的结果写入批处理表,并从快速表中删除不准确
的结果。最终,应用程序会合并快速表和批处理表中的结果,并展示出来。
优点:兼具了批处理和第一代流处理器的特点,同时保证了低延迟和结果的准确性。
缺点:Lambda架构本身很难建立和维护;而且它需要我们对一个应用程序,做出两套语义上等效的逻辑实现,因为批处理和流处理是两套完全独立的系统,他们的API也完全相同。
为了实现一个应用,付出了双倍的工作量,这对程序员显然不够友好。
第三代:Flink
解决了乱序数据对结果正确性的影响。这一代系统还做到了精确一次(exactly-once)的执行保障,是第一个具有一致性和准确结果的开源节流处理器。
另外,先前的流处理器仅能在高吞吐和低延迟中二选一,而新一代系统能够同时提供
这两个特性。所以可以说,这一代流处理器仅凭一套系统就完成了
Lambda
架构两套系统的工
作,它的出现使得
Lambda
架构黯然失色。
除了低延迟、容错和结果准确性之外,新一代流处理器还在不断添加新的功能,例如高可
用的设置,以及与资源管理器(如
YARN
或
Kubernetes
)的紧密集成等等
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1340
1340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









