






Task3学习笔记
这是结束,亦或是新的开始。
学习任务
数据增强,提升模型表现。
Faster, faster, faster!
基础知识
为什么需要数据增强
先看一下Datawhale教研人员给出的解释:
数据增强是一种在机器学习和深度学习领域常用的技术,尤其是在处理图像和视频数据时。数据增强的目的是通过人工方式增加训练数据的多样性,从而提高模型的泛化能力,使其能够在未见过的数据上表现得更好。数据增强涉及对原始数据进行一系列的变换操作,生成新的训练样本。这些变换模拟了真实世界中的变化,对于图像而言,数据增强包括例如视角、光照、遮挡等情况,使得模型能够学习到更加鲁棒的特征表示。
如何解读呢?
-
数据自然是越多越好,但现实中,这可能会起反作用。
首先,随着人们进入信息时代,需要处理的数据呈爆炸式增长,现有的设备很难一次性存储或者使分批处理的速度和数据增长的速度同步。
再者,计算机不是0就是1,认死理,那些数据只要哪怕结构上有一点变化,那就会变成新数据,不像人类可以通过反向操作进行真正意义上的归一化。比如一张照片的不同分辨率结果在计算机看来就是不同的样本。
其次,如果神经网络没有跟随数据完善结构,极有可能在现有的规模上造成“过拟合”现象,那神经网络将不再具有思考能力,而是变成形如复读机的存在。
假设我要训练一个模型,让它可以检测出一只鸽子大不大。很明显,这个”大不大“不是计算机的物理电路规定的,是人规定的。因此得使用监督学习思路。
那我将使用下列思路:
-
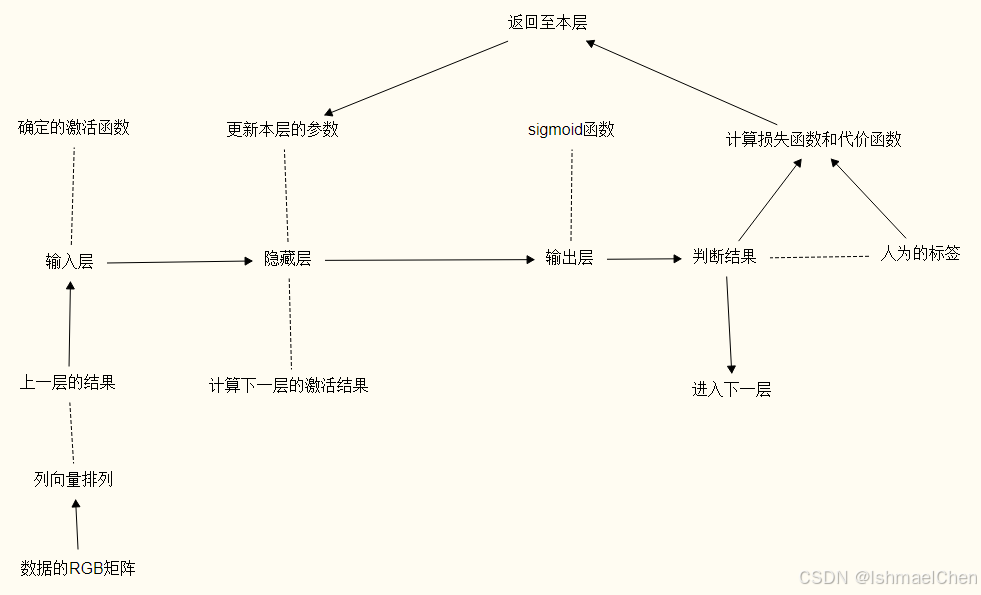
图像根据RGB分割成三个矩阵,按行拼接形成新的列向量。
-
使用监督学习思路,给每一张照片进行标签分类,并投入神经网络进行计算。
那大概就是这样的
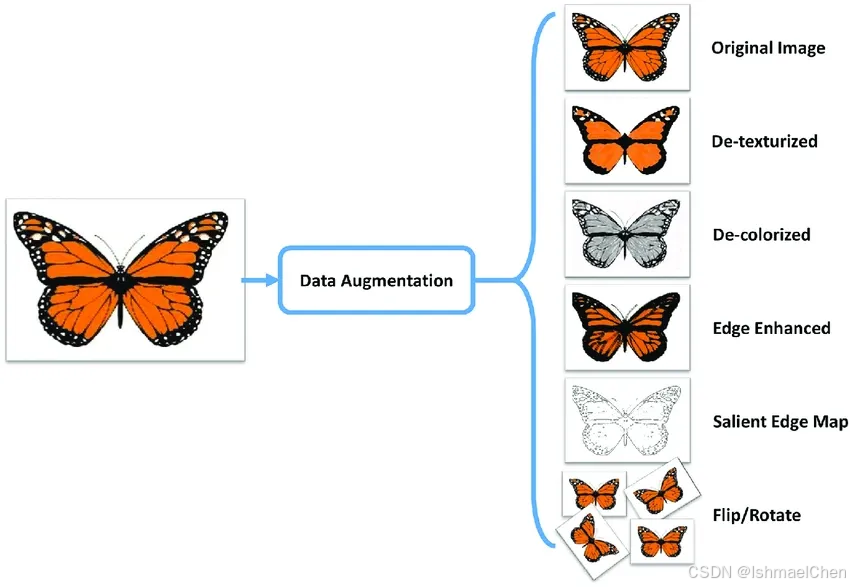
如果这些数据都是像下方Datawhale提供的样张那样规范,那就好说了。
可这种图片并不代表日常的生活情景啊!这不,挑战者就来了。

这只鸽子大不大?很明显,不大,这是因为透视原理所以显得它大。可惜计算机不知道什么是透视原理,它只知道0和1。
可是,我们的数据中只有图片的RGB特征这种十分泛的特征,之前并没有将照片的透视原理量化并投入训练。所以,此时的神经网络就不会去想为什么透视原理会影响对物体大小的判定,那它就只能为了逻辑回归的成功生凑参数了,此时模型将进入过拟合状态,一般在准确率测试下,精度可以达到100%。
可这样的参数并不符合人类的逻辑,对于解决人类日常生活中的问题是没有意义的。
想尝试对计算机进行新的监督学习以修正结果?那它估计也只会用那不太够用的神经网络问道:
道理我都懂,可是为什么鸽子这么大?然后你又说它是小的?
计算机此时说的道理是一坨人类觉得不可理喻的东西。
这个模型的判断就离谱,你老刷那B三色干什么玩意啊?
可我们人类命令它在训练时,也没教它什么是透视原理啊?
看吧,深度学习的神经网络终究还是得让人手把手一步步扣好它数据生涯的第一粒扣子。可我要是能完全解释这一切我要这神经网络有何用?
数据增强,本身也是得告诉神经网络得做点人该干的事。
2.数据获取可能会受阻
深度学习在影像分类方面是一个热闹研究方向,所以,有兴趣在医学影像方向进行研究吗?医生可以以他们的职业生涯作为担保,所有的数据都是真实的。
我的大创有幸接触到了相关领域,需要使用相关的技术对病人的心脏进行3D建模,然后利用训练得出的模型将疑似病灶处的模型分离出来。
有前景吗?有,将病人从物理检测的痛苦中解放出来——传统的方法中,病人需要被人工植入一根压力导丝,随着心脏的跳动,将物理量转化为电信号,最终转化成我们需要的数据流。想象一下鼻腔镜检查时,医生为了消毒将两根棉签直接插入鼻孔深处的经历——正常人受这刺激会当场喷出大量的鼻涕,这不好受,那心脏被这样对待了能好受吗?
能迅速投入使用吗?不可能,所有的模型都不可能有100%准确率,万一结果导致医生误判了怎么办?谁负责?所以,这样的模型训练过程中要经过严格的医学实验阶段,也就是说,要用病人的隐私数据作为训练集投入训练的同时,还得给他/她埋压力导丝,最后结果要作比对,这简直是双重折磨。
这样的数据一是大医院才有设备能采集,二是病人的隐私数据能随意的被挪用,被收集吗?肯定要经过病人同意啊。那对于医生,不尊重病人的隐私是违反希波克拉底誓言的典型行为,对于研究人员,将活人作为实验,不尊重人的尊严,更是对人类伦理的挑战。
所以,总会有一些研究领域因为这样那样的原因,光是数据获取的过程就已经十分艰难了。那能怎么办呢?总得有人做点什么来证明那些幻想,那些深邃的黑暗幻想。
所以,帮帮我,数据增强!
数据增强要怎么做
如果数据增强的变换操作与目标任务的实际场景不符,比如在不需要旋转的图像任务中过度使用旋转,那么这些变换可能会引入无关的噪音。此外过度的数据增强,比如极端的亮度调整、对比度变化或大量的噪声添加,可能会导致图像失真,使得模型难以学习到有效的特征。
总之,我们希望深度学习能像人一样思考,就别把自己整得像个似人。
实际优化实践
Talk is useless, show me the code.
在之前的代码中我们使用PyTorch框架来加载和增强图像数据:
-
图像大小调整:使用
transforms.Resize((256, 256))将所有图像调整到256x256像素的尺寸,这有助于确保输入数据的一致性。 -
随机水平翻转:
transforms.RandomHorizontalFlip()随机地水平翻转图像,这种变换可以模拟物体在不同方向上的观察,从而增强模型的泛化能力。 -
随机垂直翻转:
transforms.RandomVerticalFlip()随机地垂直翻转图像,这同样是为了增加数据多样性,让模型能够学习到不同视角下的特征。 -
转换为张量:
transforms.ToTensor()将图像数据转换为PyTorch的Tensor格式,这是在深度学习中处理图像数据的常用格式。 -
归一化:
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])对图像进行归一化处理,这里的均值和标准差是根据ImageNet数据集计算得出的,用于将图像像素值标准化,这有助于模型的训练稳定性和收敛速度。
train_loader = torch.utils.data.DataLoader(
FFDIDataset(train_label['path'].head(1000), train_label['target'].head(1000),
transforms.Compose([
transforms.Resize((256, 256)),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
), batch_size=40, shuffle=True, num_workers=4, pin_memory=True
)
val_loader = torch.utils.data.DataLoader(
FFDIDataset(val_label['path'].head(1000), val_label['target'].head(1000),
transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
), batch_size=40, shuffle=False, num_workers=4, pin_memory=True
)在深度学习中,对输入数据进行归一化是一个标准步骤。归一化有助于加快模型的收敛速度,并提高数值稳定性。对于验证集,应该避免使用如随机翻转等可能引入不必要噪音的增强方法。通常,验证集只需要进行必要的预处理,如调整大小和归一化。
不过,归一化也得注意计算机底层的逻辑,它首先整一块内存,然后接引资源运算,一开始的大内存是固定的,要想后面调,调多少得自己算出来。所以,对于图片进行旋转操作时,可能图片会被裁剪。
使用工具
torchvision是一个流行的开源Python包,它提供了许多用于深度学习计算机视觉任务的工具和预训练模型。在torchvision中,数据增强方法主要位于torchvision.transforms和torchvision.transforms.v2模块中。这些增强方法可以用于图像分类、目标检测、图像分割和视频分类等各种任务。
实践分析
先从最原始的案例开始,这次我们使用猫的图片样例进行分析。

然后对图像进行了以下一些应该是人能干出来的变换:
-
几何变换
-
调整大小:
Resize可以将图像调整到指定的大小。 -
随机裁剪:
RandomCrop和RandomResizedCrop可以随机裁剪图像。 -
中心裁剪:
CenterCrop从图像的中心裁剪出指定大小。 -
五裁剪和十裁剪:
FiveCrop和TenCrop分别裁剪出图像的四个角和中心区域。 -
翻转:
RandomHorizontalFlip和RandomVerticalFlip可以水平或垂直翻转图像。 -
旋转:
RandomRotation可以随机旋转图像。 -
仿射变换:
RandomAffine可以进行随机的仿射变换。 -
透视变换:
RandomPerspective可以进行随机的透视变换。

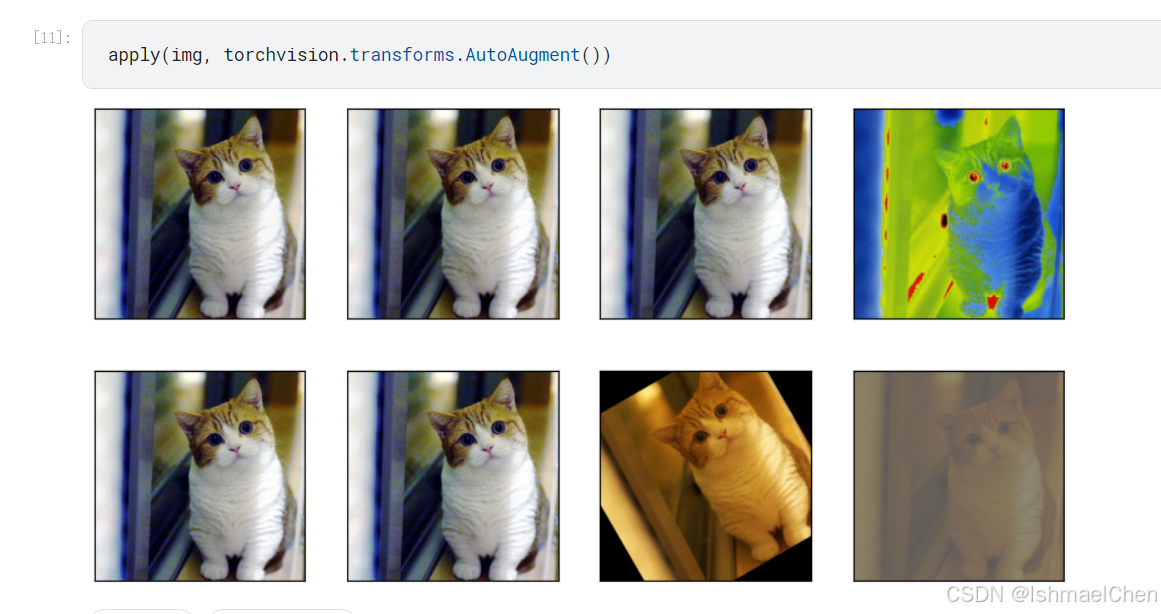
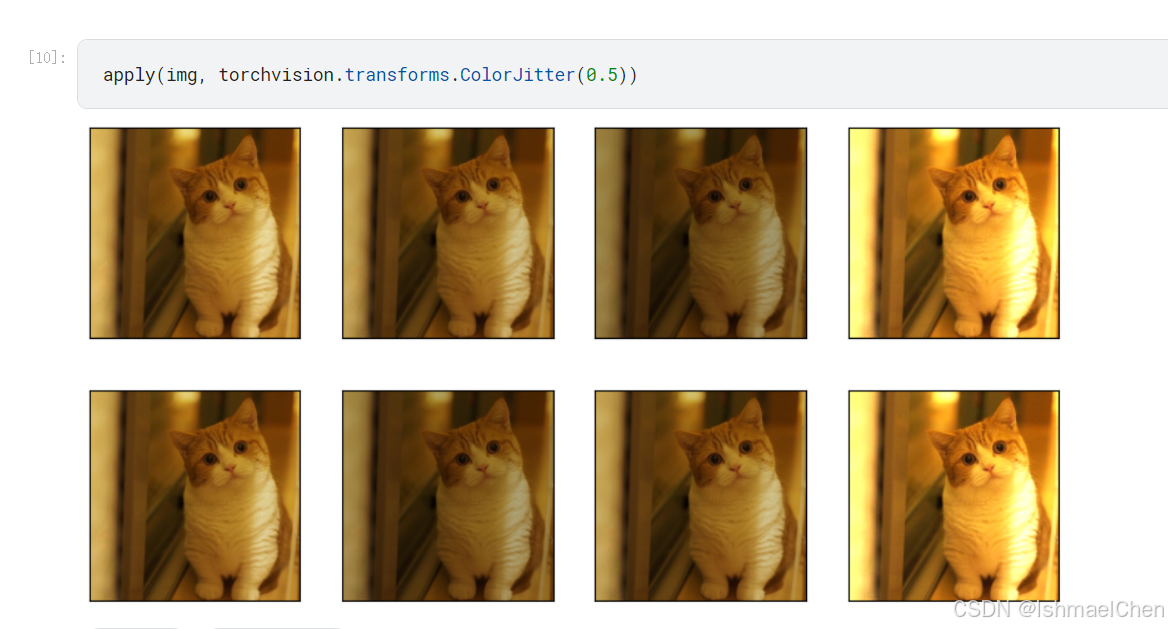
2.颜色变换
-
颜色抖动:
ColorJitter可以随机改变图像的亮度、对比度、饱和度和色调。 -
灰度化:
Grayscale和RandomGrayscale可以将图像转换为灰度图。 -
高斯模糊:
GaussianBlur可以对图像进行高斯模糊。 -
颜色反转:
RandomInvert可以随机反转图像的颜色。 -
颜色 posterize:
RandomPosterize可以减少图像中每个颜色通道的位数。 -
颜色 solarize:
RandomSolarize可以反转图像中所有高于阈值的像素值。
这方面还是机器玩得花,然后全部投入训练。
3.CutMIX
首先,导入虚假数据

然后让真实数据和虚假数据混合,得到新的数据集
也许,我们可以使用新的方法,比如混合新的噪点
亦或是将已经处理好的图片进行拼接
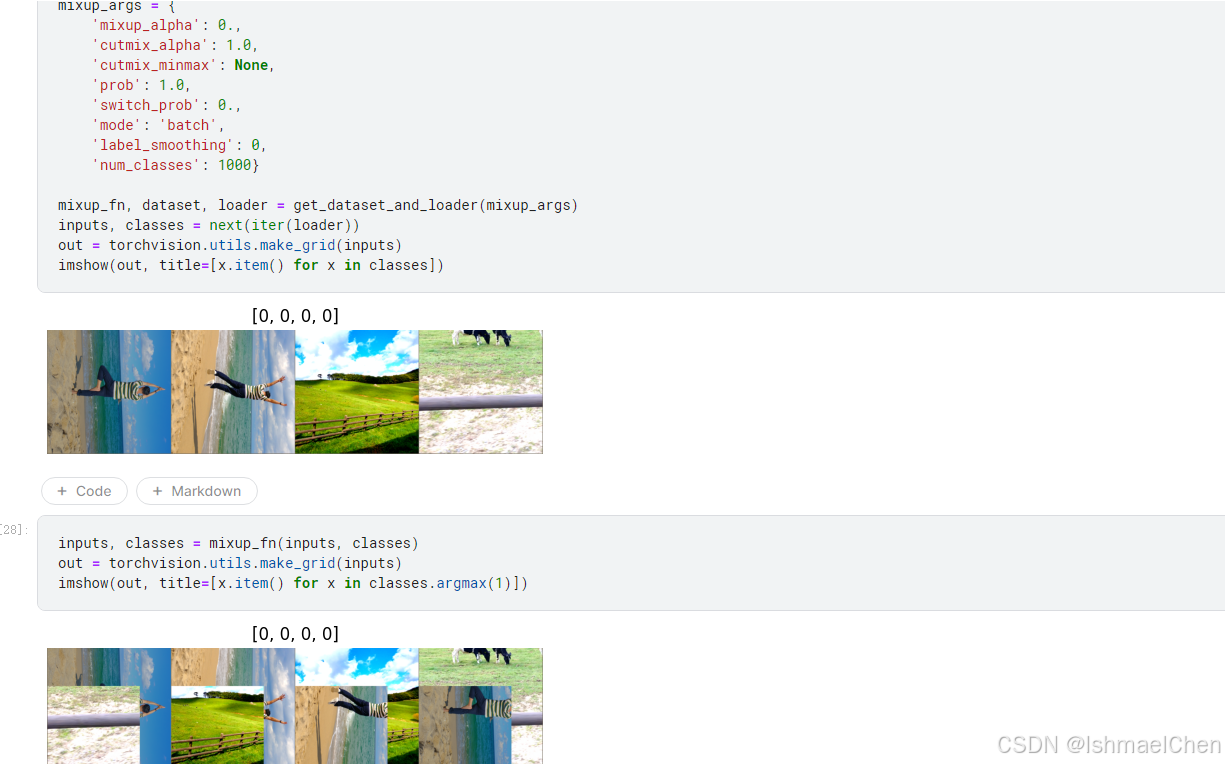
还可以进行类似于PS的蒙板设计
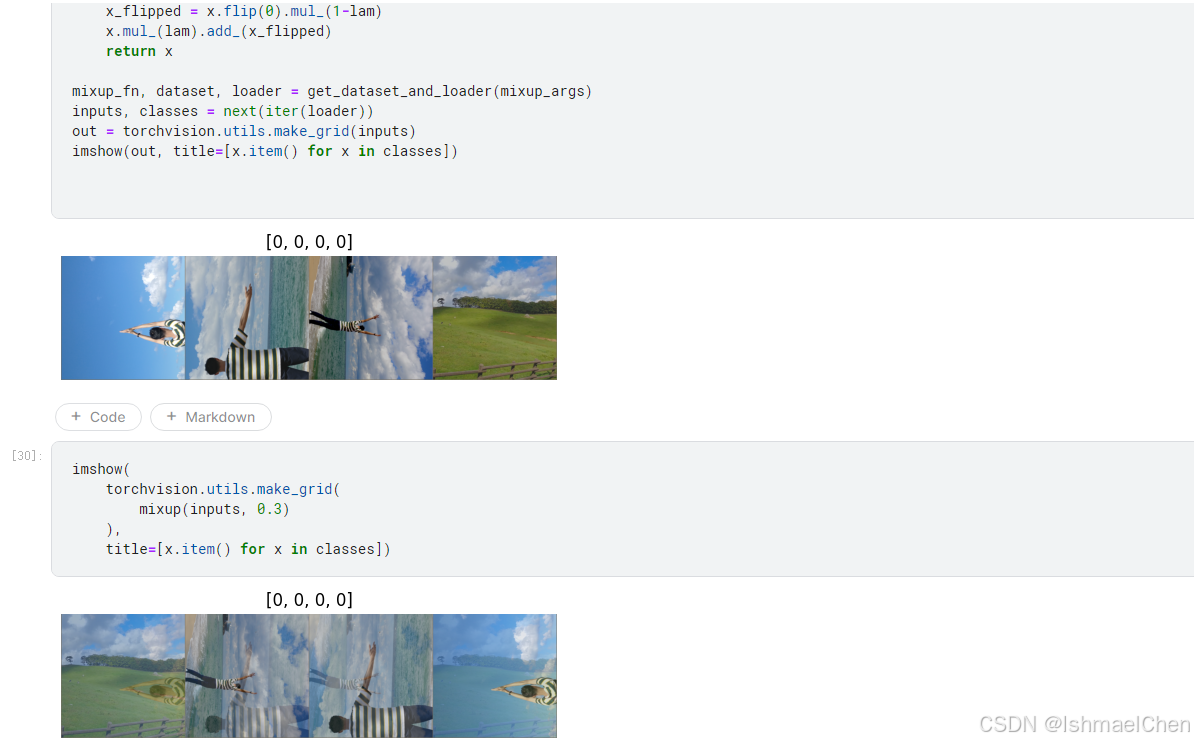
当然,作为成年人,我全都要!
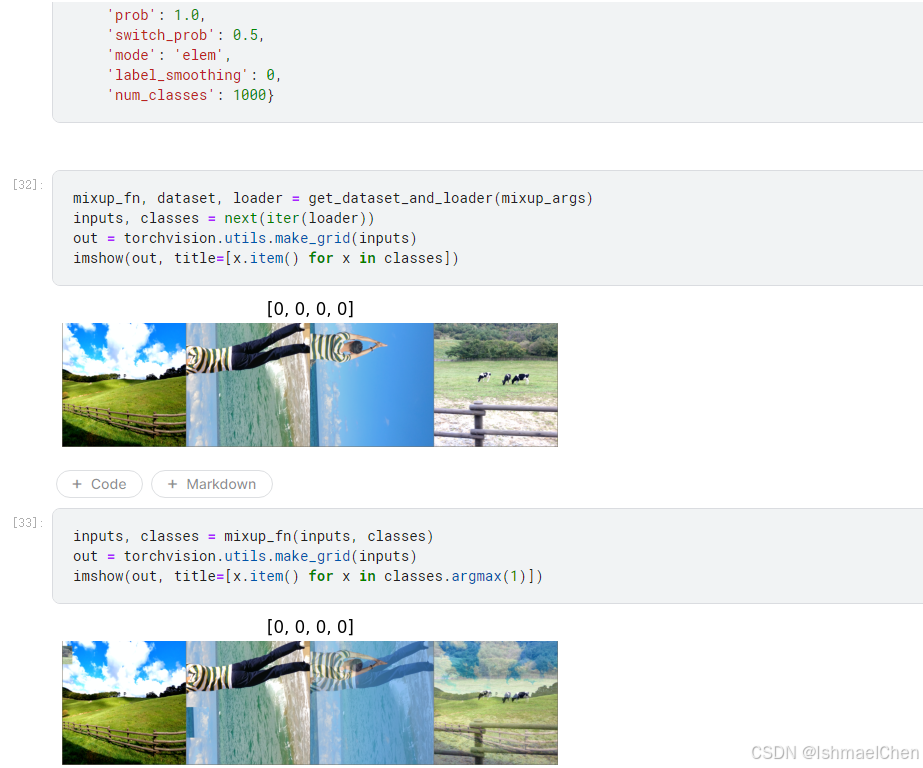
5.音频数据增强
音频数据增强的原理与图像数据增强类似,都是通过对原始数据进行一系列的变换操作,生成新的训练样本。这些变换模拟了真实世界中的变化,例如时间尺度、音调、噪声、房间环境等,使得模型能够学习到更加鲁棒的特征表示。
-
时间拉伸和压缩:改变音频的时间尺度,模拟不同的说话速度或音乐播放速度。
-
音调变换:改变音频的音调,模拟不同的说话人或乐器。
-
添加噪声:向音频中添加不同类型的噪声,如白噪声、粉红噪声等,以提高模型对噪声的抗干扰能力。
-
频率掩码和时间掩码:在频谱图上随机掩盖一些频率或时间区域,迫使模型学习到更加鲁棒的特征表示。
-
混响:模拟不同的房间环境,增加音频的丰富性。
-
声道分离:将多声道音频中的某些声道分离出来,训练模型对不同声道特征的学习。
-
音量调整:调整音频的音量,模拟不同的音量大小。
这个应该不用多说了,我去应用市场下载一个变声器,它便会对输入的声音信号进行变换,然后产出新的声音,丰富模型的训练量。
不过就像丁真所言,也许在山里能听到各种动物朋友的叫声,我们也可以混入其他的声音而不仅仅是原有声音的变换。
比如说,我们宿舍曾互相约定都去学习伪声互相爽爽,虽然大家最后都没学成就对了,其实这很费声带的。
比如说,在给其他人打电话的时候,本来正常的声音突然变成/被插入了一段萝莉音,那电话那头的人估计会纳闷这人在整什么花活?然后他就会开始学习,通过搜集更多的信息来确认这种来历不明的声音到底是谁的,最后,他确认了——有个人在用伪声搞怪。
但是吧,上面的例子都是我自己杜撰出来的,那就对了,也许我们平日里内心已经或多或少地进行过对自己的数据增强了,以至于对这种深邃的黑暗幻想竟会觉得如此正常。你以为你在第二层,事实上我在第五层。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









