




https://blog.youkuaiyun.com/weixin_45655710?type=blog
@浙大疏锦行
今日作业:
对于信贷数据,仔细观察每个模型的评估指标,并且打印他们的roc和pr曲线,从今天课上的是视角去理解他们的能力
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
# ====================== 1. 基础设置 ======================
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文显示
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示
# 数据路径(替换为你的实际路径)
data_path = r"D:\桌面\PythonStudy\python60-days-challenge-master\python60-days-challenge-master\data.csv"
# ====================== 2. 数据预处理 ======================
def preprocess_data(data_path):
"""数据预处理函数(复用课程逻辑)"""
data = pd.read_csv(data_path)
# 1. 字符串变量处理
# Home Ownership 标签编码
home_ownership_mapping = {
'Own Home': 1,
'Rent': 2,
'Have Mortgage': 3,
'Home Mortgage': 4
}
data['Home Ownership'] = data['Home Ownership'].map(home_ownership_mapping)
# Years in current job 标签编码
years_in_job_mapping = {
'< 1 year': 1, '1 year': 2, '2 years': 3, '3 years': 4, '4 years': 5,
'5 years': 6, '6 years': 7, '7 years': 8, '8 years': 9, '9 years': 10, '10+ years': 11
}
data['Years in current job'] = data['Years in current job'].map(years_in_job_mapping)
# Purpose 独热编码
data = pd.get_dummies(data, columns=['Purpose'])
# 独热编码列转为int
data2 = pd.read_csv(data_path)
new_cols = [col for col in data.columns if col not in data2.columns]
for col in new_cols:
data[col] = data[col].astype(int)
# Term 映射 + 重命名
term_mapping = {'Short Term': 0, 'Long Term': 1}
data['Term'] = data['Term'].map(term_mapping)
data.rename(columns={'Term': 'Long Term'}, inplace=True)
# 2. 缺失值填充(连续特征用众数)
continuous_features = data.select_dtypes(include=['int64', 'float64']).columns.tolist()
for feat in continuous_features:
mode_val = data[feat].mode()[0]
data[feat].fillna(mode_val, inplace=True)
# 3. 划分特征/标签
X = data.drop(['Credit Default'], axis=1)
y = data['Credit Default']
return X, y
# 执行预处理
X, y = preprocess_data(data_path)
# 划分训练集/测试集(8:2)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y # stratify保证正负样本比例一致
)
# ====================== 3. 模型训练(多模型对比) ======================
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
# 定义待评估的模型
models = {
"随机森林": RandomForestClassifier(random_state=42),
"逻辑回归": LogisticRegression(random_state=42, max_iter=1000),
"决策树": DecisionTreeClassifier(random_state=42),
"K近邻": KNeighborsClassifier(n_neighbors=5),
"支持向量机": SVC(random_state=42, probability=True) # 需要概率输出用于ROC/PR
}
# 训练模型并保存预测结果
model_preds = {} # 存储预测类别
model_probas = {} # 存储正类概率
for name, model in models.items():
print(f"\n===== 训练 {name} =====")
model.fit(X_train, y_train)
model_preds[name] = model.predict(X_test)
model_probas[name] = model.predict_proba(X_test)[:, 1] # 正类(违约)概率
# ====================== 4. 评估指标计算 ======================
from sklearn.metrics import (
accuracy_score, precision_score, recall_score, f1_score,
roc_auc_score, average_precision_score, confusion_matrix
)
# 打印详细指标
print("\n===== 各模型评估指标汇总 =====")
metrics_df = pd.DataFrame(columns=["模型", "准确率", "精确率", "召回率", "F1分数", "AUC", "AP"])
for i, name in enumerate(models.keys()):
preds = model_preds[name]
probas = model_probas[name]
# 计算指标
acc = accuracy_score(y_test, preds)
prec = precision_score(y_test, preds, zero_division=0) # 避免除以0
rec = recall_score(y_test, preds)
f1 = f1_score(y_test, preds)
auc = roc_auc_score(y_test, probas)
ap = average_precision_score(y_test, probas)
# 存入DataFrame
metrics_df.loc[i] = [name, round(acc, 4), round(prec, 4),
round(rec, 4), round(f1, 4), round(auc, 4), round(ap, 4)]
# 打印混淆矩阵
print(f"\n{name} 混淆矩阵:")
cm = confusion_matrix(y_test, preds)
print(pd.DataFrame(cm, columns=["预测0(未违约)", "预测1(违约)"],
index=["真实0(未违约)", "真实1(违约)"]))
# 打印指标表格
print("\n===== 指标汇总表 =====")
print(metrics_df)
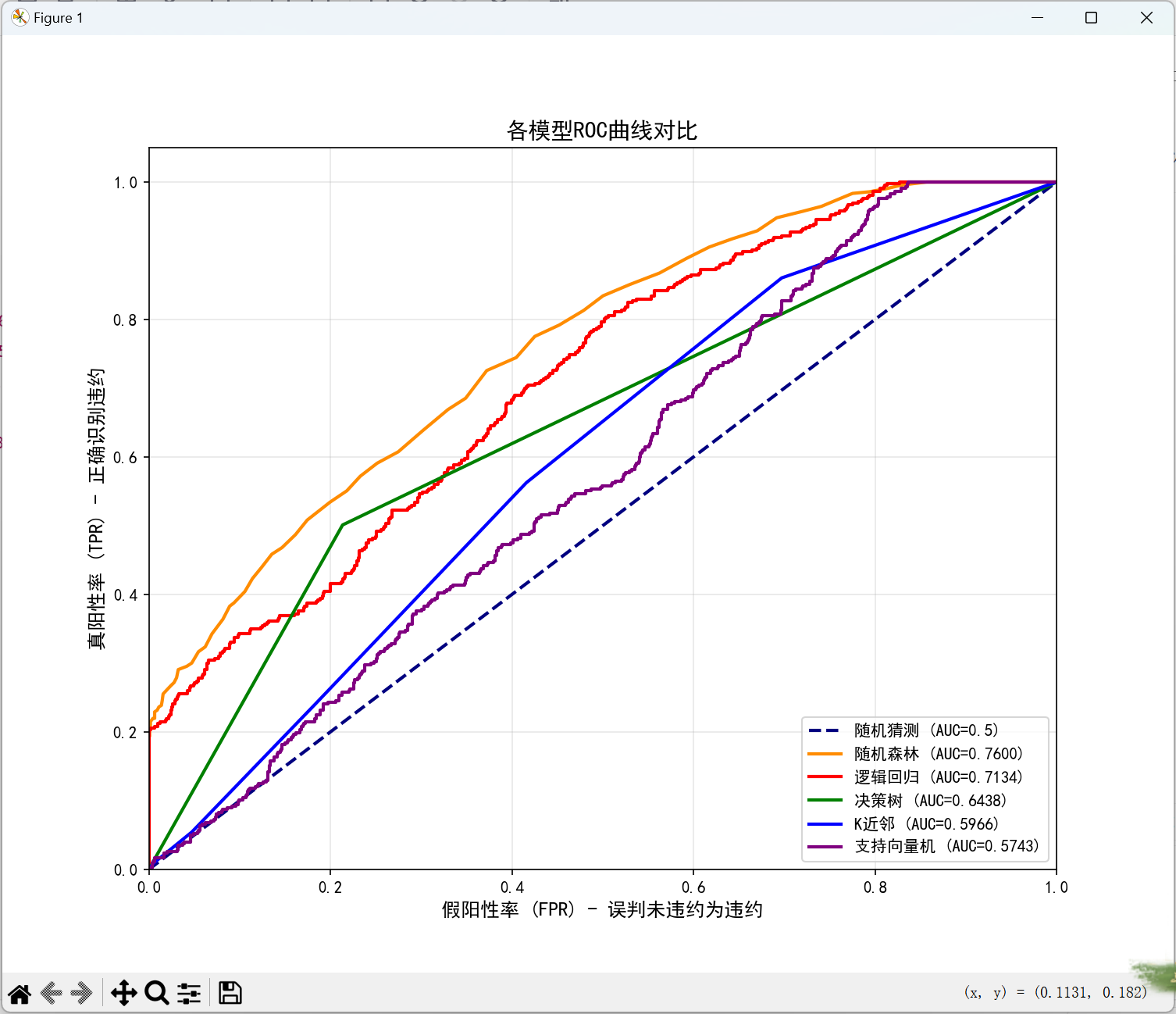
# ====================== 5. ROC曲线可视化(多模型对比) ======================
from sklearn.metrics import roc_curve, auc
plt.figure(figsize=(10, 8))
# 绘制随机猜测基线
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--', label='随机猜测 (AUC=0.5)')
# 绘制各模型ROC曲线
colors = ['darkorange', 'red', 'green', 'blue', 'purple']
for i, (name, probas) in enumerate(model_probas.items()):
fpr, tpr, _ = roc_curve(y_test, probas)
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, color=colors[i], lw=2,
label=f'{name} (AUC={roc_auc:.4f})')
# 图表样式设置
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('假阳性率 (FPR) - 误判未违约为违约', fontsize=12)
plt.ylabel('真阳性率 (TPR) - 正确识别违约', fontsize=12)
plt.title('各模型ROC曲线对比', fontsize=14)
plt.legend(loc="lower right", fontsize=10)
plt.grid(alpha=0.3)
plt.savefig("多模型ROC曲线.png", dpi=300, bbox_inches='tight')
plt.show()
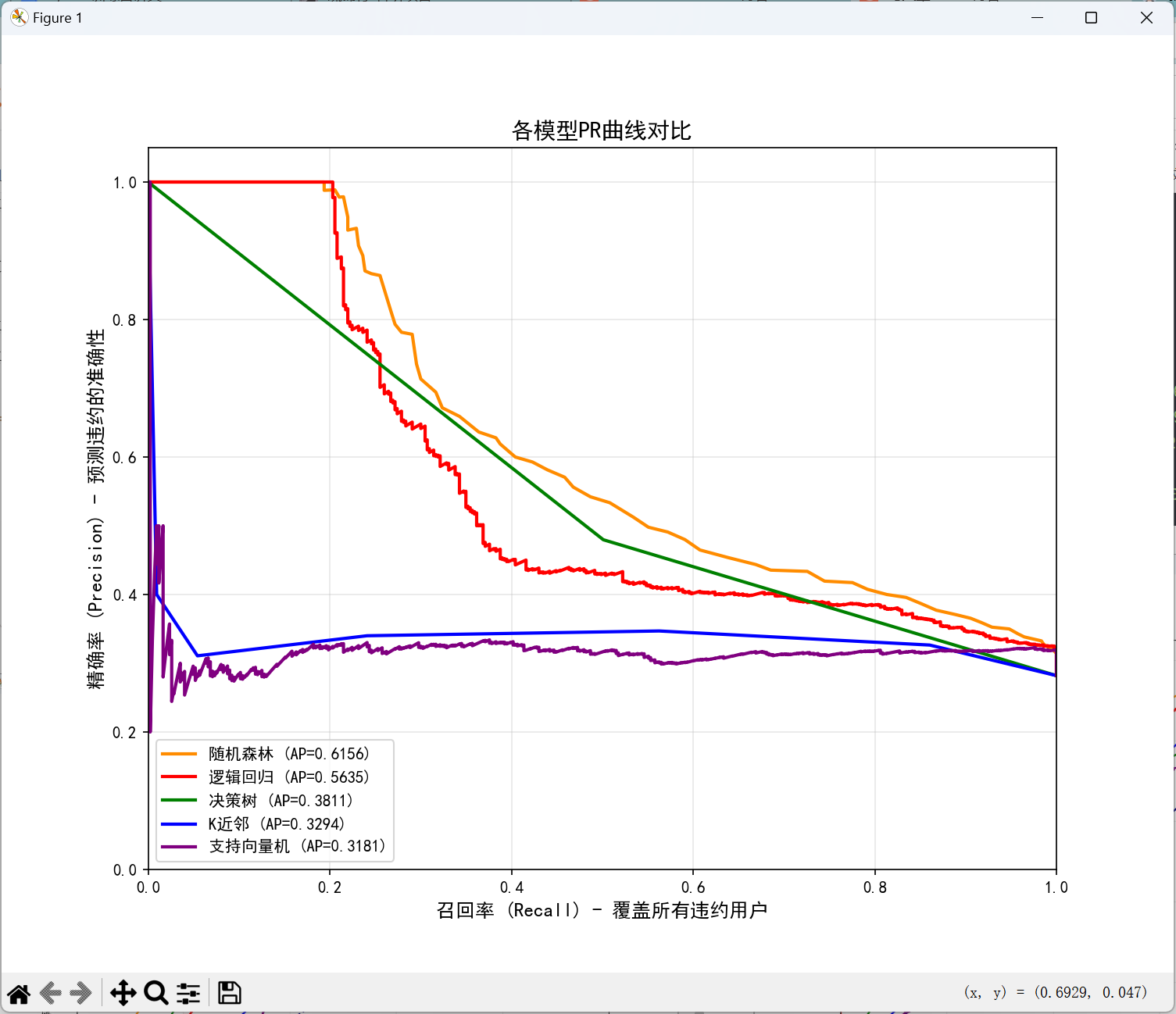
# ====================== 6. PR曲线可视化(多模型对比) ======================
from sklearn.metrics import precision_recall_curve
plt.figure(figsize=(10, 8))
# 绘制各模型PR曲线
for i, (name, probas) in enumerate(model_probas.items()):
precision, recall, _ = precision_recall_curve(y_test, probas)
ap = average_precision_score(y_test, probas)
plt.plot(recall, precision, color=colors[i], lw=2,
label=f'{name} (AP={ap:.4f})')
# 图表样式设置
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('召回率 (Recall) - 覆盖所有违约用户', fontsize=12)
plt.ylabel('精确率 (Precision) - 预测违约的准确性', fontsize=12)
plt.title('各模型PR曲线对比', fontsize=14)
plt.legend(loc="lower left", fontsize=10)
plt.grid(alpha=0.3)
plt.savefig("多模型PR曲线.png", dpi=300, bbox_inches='tight')
plt.show()
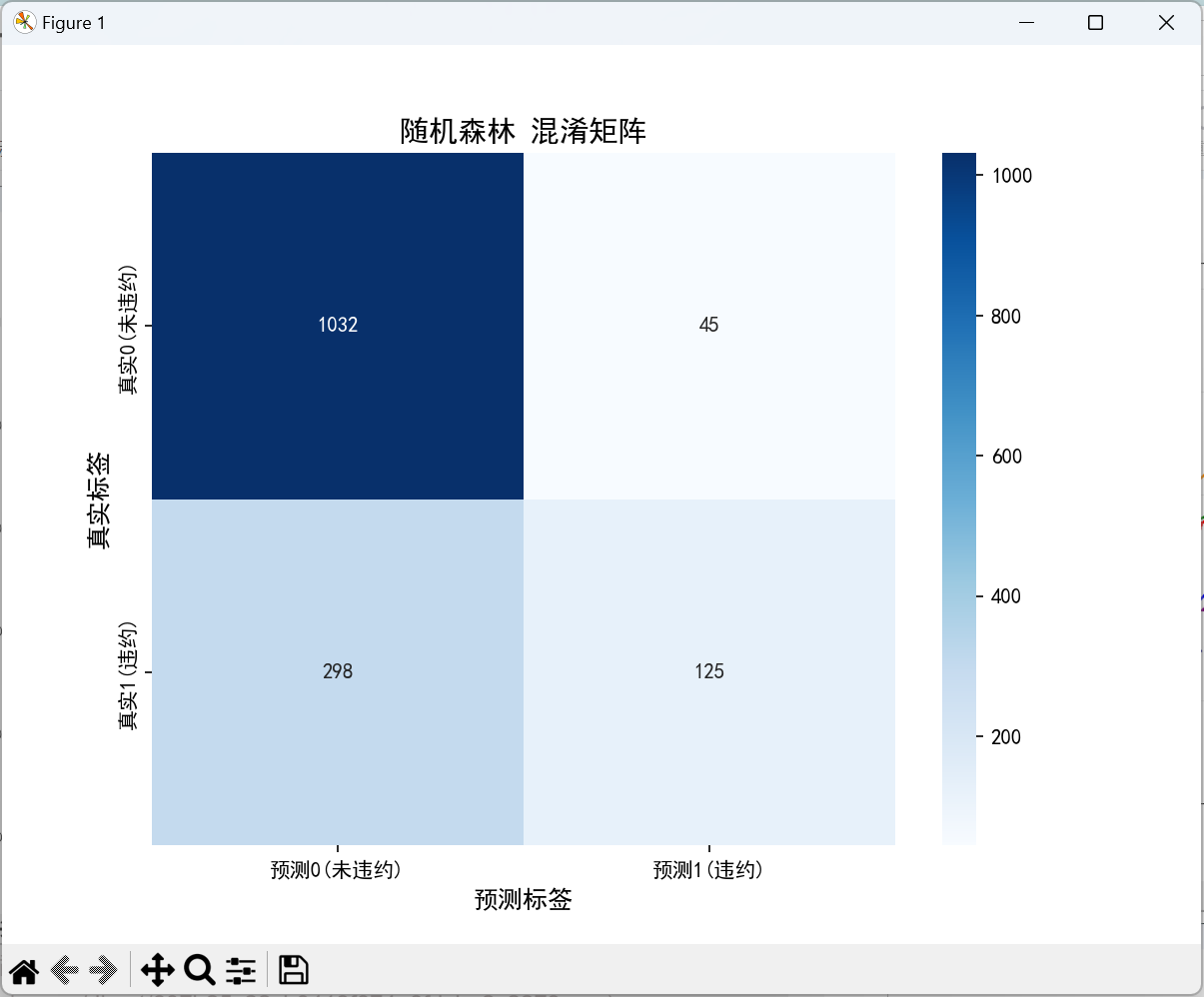
# ====================== 7. 单模型详细分析(以随机森林为例) ======================
print("\n===== 随机森林详细分析 =====")
rf_name = "随机森林"
rf_preds = model_preds[rf_name]
rf_probas = model_probas[rf_name]
# 1. 混淆矩阵可视化
cm = confusion_matrix(y_test, rf_preds)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=['预测0(未违约)', '预测1(违约)'],
yticklabels=['真实0(未违约)', '真实1(违约)'])
plt.title(f'{rf_name} 混淆矩阵', fontsize=14)
plt.ylabel('真实标签', fontsize=12)
plt.xlabel('预测标签', fontsize=12)
plt.show()
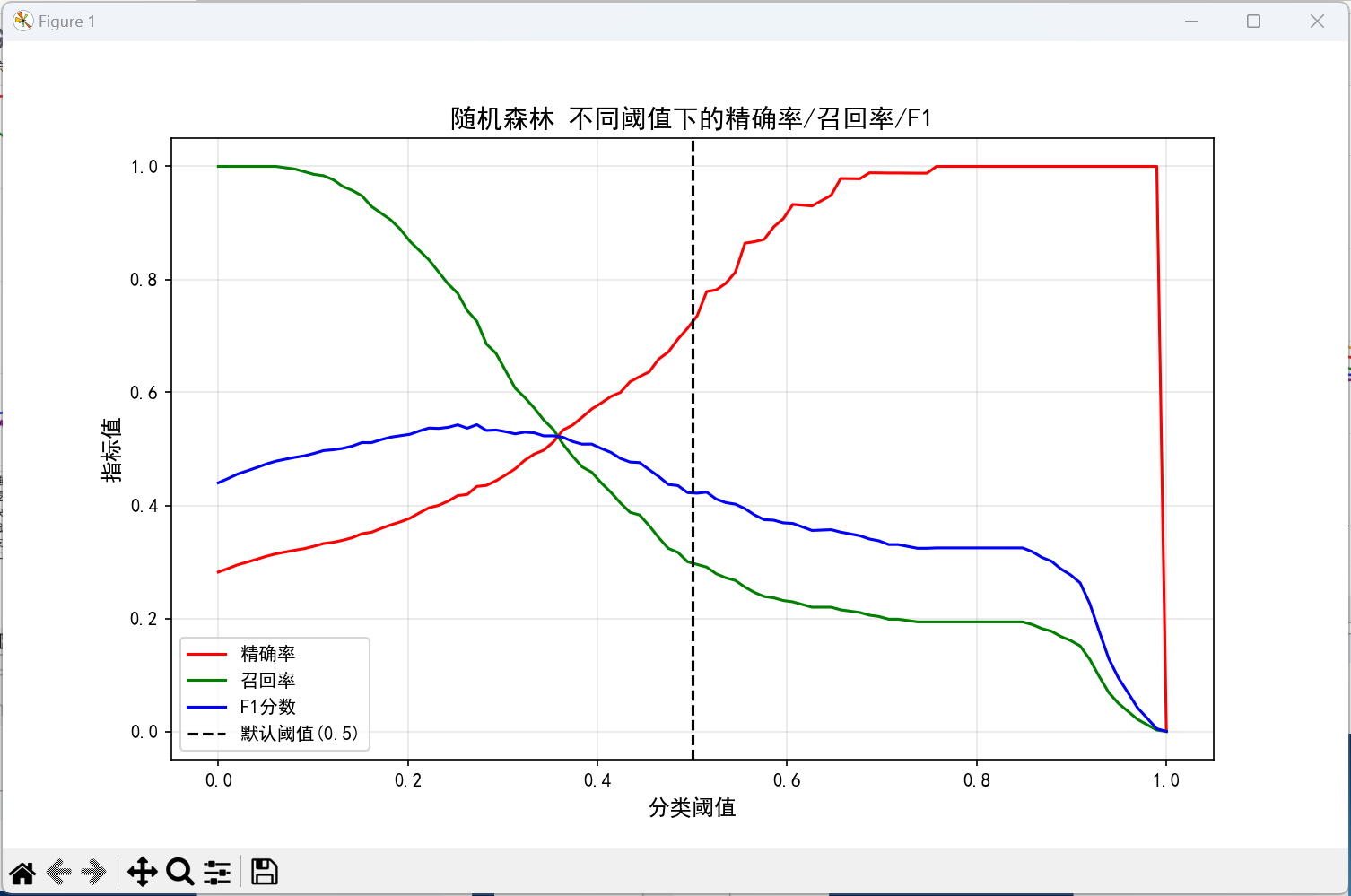
# 2. 阈值对指标的影响(随机森林)
thresholds = np.linspace(0, 1, 100)
precisions = []
recalls = []
f1_scores = []
for thres in thresholds:
preds_thres = (rf_probas >= thres).astype(int)
precisions.append(precision_score(y_test, preds_thres, zero_division=0))
recalls.append(recall_score(y_test, preds_thres))
f1_scores.append(f1_score(y_test, preds_thres))
# 绘制阈值-指标曲线
plt.figure(figsize=(10, 6))
plt.plot(thresholds, precisions, label='精确率', color='red')
plt.plot(thresholds, recalls, label='召回率', color='green')
plt.plot(thresholds, f1_scores, label='F1分数', color='blue')
plt.axvline(x=0.5, color='black', linestyle='--', label='默认阈值(0.5)')
plt.xlabel('分类阈值', fontsize=12)
plt.ylabel('指标值', fontsize=12)
plt.title(f'{rf_name} 不同阈值下的精确率/召回率/F1', fontsize=14)
plt.legend()
plt.grid(alpha=0.3)
plt.show()
(.venv) PS D:\桌面\PythonStudy\python60-days-challenge-master> & D:/桌面/PythonStudy/python60-days-challenge-master/.venv/Scripts/python.exe d:/桌面/PythonStudy/python60-days-challenge-master/python60-days-challenge-master/day16.py
===== 训练 随机森林 =====
===== 训练 逻辑回归 =====
===== 训练 决策树 =====
===== 训练 K近邻 =====
===== 训练 支持向量机 =====
===== 各模型评估指标汇总 =====
随机森林 混淆矩阵:
预测0(未违约) 预测1(违约)
真实0(未违约) 1032 45
真实1(违约) 298 125
逻辑回归 混淆矩阵:
预测0(未违约) 预测1(违约)
真实0(未违约) 1072 5
真实1(违约) 336 87
决策树 混淆矩阵:
预测0(未违约) 预测1(违约)
真实0(未违约) 847 230
真实1(违约) 211 212
K近邻 混淆矩阵:
预测0(未违约) 预测1(违约)
真实0(未违约) 879 198
真实1(违约) 321 102
支持向量机 混淆矩阵:
预测0(未违约) 预测1(违约)
真实0(未违约) 1077 0
真实1(违约) 423 0
===== 指标汇总表 =====
模型 准确率 精确率 召回率 F1分数 AUC AP
0 随机森林 0.7713 0.7353 0.2955 0.4216 0.7600 0.6156
1 逻辑回归 0.7727 0.9457 0.2057 0.3379 0.7134 0.5635
2 决策树 0.7060 0.4796 0.5012 0.4902 0.6438 0.3811
3 K近邻 0.6540 0.3400 0.2411 0.2822 0.5966 0.3294
4 支持向量机 0.7180 0.0000 0.0000 0.0000 0.5743 0.3181

















 1196
1196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









