




基于SegNet的无人驾驶场景理解研究与实现
一、研究背景
SegNet是一种基于卷积神经网络的图像分割技术,广泛用于场景理解领域。在无人驾驶技术中,需要对道路场景进行实时分割以提取车辆、路面、道路标识等关键信息,进而支持车辆决策和控制。
SegNet通过对图像进行特征提取、编码、解码等操作,来识别图像中不同的场景元素。在实现过程中,需要选择合适的数据集、设计合理的网络结构,并通过不断的训练和评估来提高模型的分割准确度。
具体来说,就是对一张道路图片,逐像素分析为每一个像素点分配语义标签,并用不同颜色标出;最终对图片中的各个类别物体涂上不同的颜色。
二、实现步骤
基于SegNet的无人驾驶场景理解研究与实现包括以下几个步骤:
- 数据集选择:选择包含道路场景的图像数据集,用于训练和评估模型。
- 网络结构设计:设计符合场景分割任务要求的SegNet网络结构,比如使用不同的卷积层等。
- 损失函数:设计合适的损失函数来更新网络中的参数。
- 训练和评估:使用训练数据集训练SegNet模型,不断迭代以提高模型的分割准确度,并使用测试数据集评估模型的分割结果。
数据集的选择
使用了cityscapes-dataset中公开的数据集,数据集包括:3475张用于训练和验证的图片及对应分割好的结果图片、1525张用于测试的图片及对应分割好的结果图片;
数据集的下载:


网络结构设计
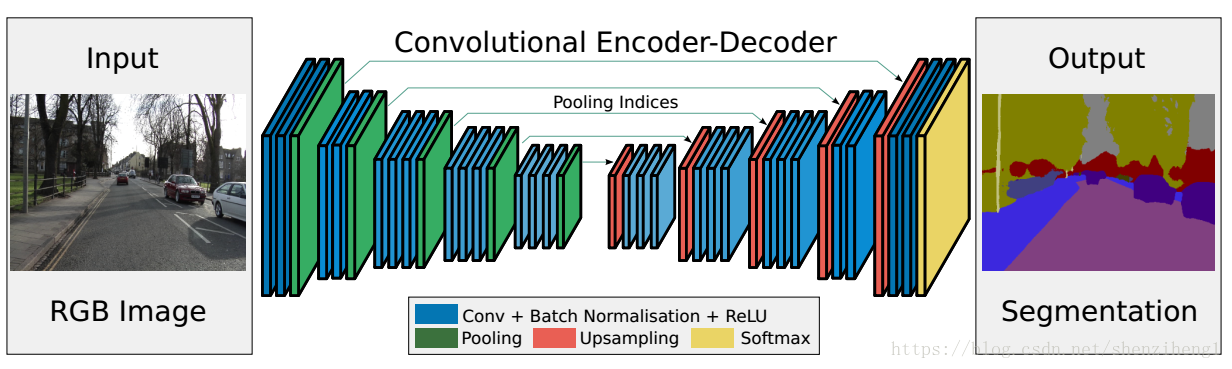
经典的SegNet网络结构:
输入——2层卷积——1层池化 2层卷积——1层池化
3层卷积——1层池化 3层卷积——1层池化
3层卷积——1层池化 1层上采样——3层卷积
1层上采样——3层卷积 1层上采样——3层卷积
1层上采样——2层卷积 1层上采样——2层卷积——输出
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
SegNet —— --
├─single_conv: 1-1 [1, 64, 96, 96] --
│ └─Conv2d: 2-1 [1, 64, 96, 96] 1,792
│ └─BatchNorm2d: 2-2 [1, 64, 96, 96] 128
│ └─ReLU: 2-3 [1, 64, 96, 96] --
├─single_conv: 1-2 [1, 64, 96, 96] --
│ └─Conv2d: 2-4 [1, 64, 96, 96] 36,928
│ └─BatchNorm2d: 2-5 [1, 64, 96, 96] 128
│ └─ReLU: 2-6 [1, 64, 96, 96] --
├─down_layer: 1-3 [1, 64, 48, 48] --
│ └─MaxPool2d: 2-7 [1, 64, 48, 48] --
├─single_conv: 1-4 [1, 128, 48, 48] --
│ └─Conv2d: 2-8 [1, 128, 48, 48] 73,856
│ └─BatchNorm2d: 2-9 [1, 128, 48, 48] 256
│ └─ReLU: 2-10 [1, 128, 48, 48] --
├─single_conv: 1-5 [1, 128, 48, 48] --
│ └─Conv2d: 2-11 [1, 128, 48, 48] 147,584
│ └─BatchNorm2d: 2-12 [1, 128, 48, 48] 256
│ └─ReLU: 2-13 [1, 128, 48, 48] --
├─down_layer: 1-6 [1, 128, 24, 24] --
│ └─MaxPool2d: 2-14 [1, 128, 24, 24] --
├─single_conv: 1-7 [1, 256, 24, 24] --
│ └─Conv2d: 2-15 [1, 256, 24, 24] 295,168
│ └─BatchNorm2d: 2-16 [1, 256, 24, 24] 512
│ └─ReLU: 2-17 [1, 256, 24, 24] --
├─single_conv: 1-8 [1, 256, 24, 24] --
│ └─Conv2d: 2-18 [1, 256, 24, 24] 590,080
│ └─BatchNorm2d: 2-19 [1, 256, 24, 24] 512
│ └─ReLU: 2-20 [1, 256, 24, 24] --
├─single_conv: 1-9 [1, 256, 24, 24] --
│ └─Conv2d: 2-21 [1, 256, 24, 24] 590,080
│ └─BatchNorm2d: 2-22 [1, 256, 24, 24] 512
│ └─ReLU: 2-23 [1, 256, 24, 24] --
├─down_layer: 1-10 [1, 256, 12, 12] --
│ └─MaxPool2d: 2-24 [1, 256, 12, 12] --
├─single_conv: 1-11 [1, 512, 12, 12] --
│ └─Conv2d: 2-25 [1, 512, 12, 12] 1,180,160
│ └─BatchNorm2d: 2-26 [1, 512, 12, 12] 1,024
│ └─ReLU: 2-27 [1, 512, 12, 12] --
├─single_conv: 1-12 [1, 512, 12, 12] --
│ └─Conv2d: 2-28 [1, 512, 12, 12] 2,359,808
│ └─BatchNorm2d: 2-29 [1, 512, 12, 12] 1,024
│ └─ReLU: 2-30 [1, 512, 12, 12] --
├─single_conv: 1-13 [1, 512, 12, 12] --
│ └─Conv2d: 2-31 [1, 512, 12, 12] 2,359,808
│ └─BatchNorm2d: 2-32 [1, 512, 12, 12] 1,024
│ └─ReLU: 2-33 [1, 512, 12, 12] --
├─down_layer: 1-14 [1, 512, 6, 6] --
│ └─MaxPool2d: 2-34 [1, 512, 6, 6] --
├─single_conv: 1-15 [1, 512, 6, 6] --
│ └─Conv2d: 2-35 [1, 512, 6, 6] 2,359,808
│ └─BatchNorm2d: 2-36 [1, 512, 6, 6] 1,024
│ └─ReLU: 2-37 [1, 512, 6, 6] --
├─single_conv: 1-16 [1, 512, 6, 6] --
│ └─Conv2d: 2-38 [1, 512, 6, 6] 2,359,808
│ └─BatchNorm2d: 2-39 [1, 512, 6, 6] 1,024
│ └─ReLU: 2-40 [1, 512, 6, 6] --
├─single_conv: 1-17 [1, 512, 6, 6] --
│ └─Conv2d: 2-41 [1, 512, 6, 6] 2,359,808
│ └─BatchNorm2d: 2-42 [1, 512, 6, 6] 1,024
│ └─ReLU: 2-43 [1, 512, 6, 6] --
├─down_layer: 1-18 [1, 512, 3, 3] --
│ └─MaxPool2d: 2-44 [1, 512, 3, 3] --
├─un_pool: 1-19 [1, 512, 6, 6] --
│ └─MaxUnpool2d: 2-45 [1, 512, 6, 6] --
├─single_conv: 1-20 [1, 512, 6, 6] --
│ └─Conv2d: 2-46 [1, 512, 6, 6] 2,359,808
│ └─BatchNorm2d: 2-47 [1, 512, 6, 6] 1,024
│ └─ReLU: 2-48 [1, 512, 6, 6] --
├─single_conv: 1-21 [1, 512, 6, 6] --
│ └─Conv2d: 2-49 [1, 512, 6, 6] 2,359,808
│ └─BatchNorm2d: 2-50 [1, 512, 6, 6] 1,024
│ └─ReLU: 2-51 [1, 512, 6, 6] --
├─single_conv: 1-22 [1, 512, 6, 6] --
│ └─Conv2d: 2-52 [1, 512, 6, 6] 2,359,808
│ └─BatchNorm2d: 2-53 [1, 512, 6, 6] 1,024
│ └─ReLU: 2-54 [1, 512, 6, 6] --
├─un_pool: 1-23 [1, 512, 12, 12] --
│ └─MaxUnpool2d: 2-55 [1, 512, 12, 12] --
├─single_conv: 1-24 [1, 512, 12, 12] --
│ └─Conv2d: 2-56 [1, 512, 12, 12] 2,359,808
│ └─BatchNorm2d: 2-57 [1, 512, 12, 12] 1,024
│ └─ReLU: 2-58 [1, 512, 12, 12] --
├─single_conv: 1-25 [1, 512, 12, 12] --
│ └─Conv2d: 2-59 [1, 512, 12, 12] 2,359,808
│ └─BatchNorm2d: 2-60 [1, 512, 12, 12] 1,024
│ └─ReLU: 2-61 [1, 512, 12, 12] --
├─single_conv: 1-26 [1, 256, 12, 12] --
│ └─Conv2d: 2-62 [1, 256, 12, 12] 1,179,904
│ └─BatchNorm2d: 2-63 [1, 256, 12, 12] 512
│ └─ReLU: 2-64 [1, 256, 12, 12] --
├─un_pool: 1-27 [1, 256, 24, 24] --
│ └─MaxUnpool2d: 2-65 [1, 256, 24, 24] --
├─single_conv: 1-28 [1, 256, 24, 24] --
│ └─Conv2d: 2-66 [1, 256, 24, 24] 590,080
│ └─BatchNorm2d: 2-67 [1, 256, 24, 24] 512
│ └─ReLU: 2-68 [1, 256, 24, 24] --
├─single_conv: 1-29 [1, 256, 24, 24] --
│ └─Conv2d: 2-69 [1, 256, 24, 24] 590,080
│ └─BatchNorm2d: 2-70 [1, 256, 24, 24] 512
│ └─ReLU: 2-71 [1, 256, 24, 24] --
├─single_conv: 1-30 [1, 128, 24, 24] --
│ └─Conv2d: 2-72 [1, 128, 24, 24] 295,040
│ └─BatchNorm2d: 2-73 [1, 128, 24, 24] 256
│ └─ReLU: 2-74 [1, 128, 24, 24] --
├─un_pool: 1-31 [1, 128, 48, 48] --
│ └─MaxUnpool2d: 2-75 [1, 128, 48, 48] --
├─single_conv: 1-32 [1, 128, 48, 48] --
│ └─Conv2d: 2-76 [1, 128, 48, 48] 147,584
│ └─BatchNorm2d: 2-77 [1, 128, 48, 48] 256
│ └─ReLU: 2-78 [1, 128, 48, 48] --
├─single_conv: 1-33 [1, 64, 48, 48] --
│ └─Conv2d: 2-79 [1, 64, 48, 48] 73,792
│ └─BatchNorm2d: 2-80 [1, 64, 48, 48] 128
│ └─ReLU: 2-81 [1, 64, 48, 48] --
├─un_pool: 1-34 [1, 64, 96, 96] --
│ └─MaxUnpool2d: 2-82 [1, 64, 96, 96] --
├─single_conv: 1-35 [1, 64, 96, 96] --
│ └─Conv2d: 2-83 [1, 64, 96, 96] 36,928
│ └─BatchNorm2d: 2-84 [1, 64, 96, 96] 128
│ └─ReLU: 2-85 [1, 64, 96, 96] --
├─outconv: 1-36 [1, 20, 96, 96] --
│ └─Conv2d: 2-86 [1, 20, 96, 96] 11,540
==========================================================================================
Total params: 29,454,548
Trainable params: 29,454,548
Non-trainable params: 0
Total mult-adds (G): 5.73
==========================================================================================
Input size (MB): 0.11
Forward/backward pass size (MB): 67.53
Params size (MB): 117.82
Estimated Total Size (MB): 185.46
==========================================================================================
损失函数
在不同的应用场景中,不同的物体具有不同的重要性和安全相关性,传统的损失函数,如交叉熵,并没有考虑到不同交通元素的不同重要性,例如:汽车和行人在自动驾驶中最为重要,所以在场景分割时,场景分割的结果应该更倾向于重要的类。参考资料,我们找到了一个重要性感知的损失函数,可以根据现实世界的应用分配语义的重要性。
论文中例子:
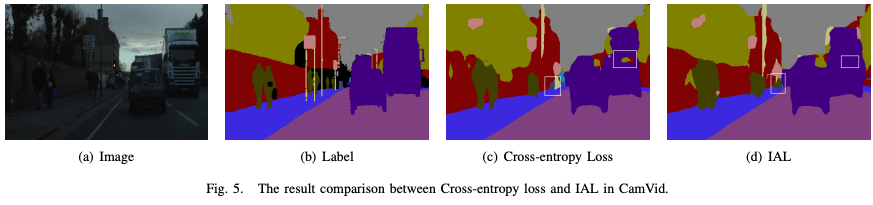
可以看出方框中采用常规的交叉熵函数会被预测为树木的部分,在采用IAL后被倾向于预测为公交车,这与实际情况是符合的。
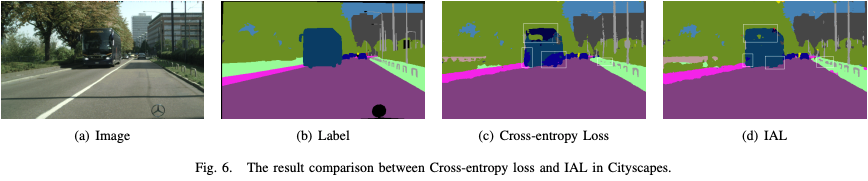
IAL在避免把重要的类预测成不重要的类的错误的情况,即使可能有部分不重要的类被预测为重要的类。用该重要性感知的损失函数更新参数,在实际自动驾驶中可以避免严重的事故的发生。
训练和评估
训练100轮,取验证集上损失函数的值最小的模型保存下来,并根据该模型在测试集上进行评估和可视化结果。
三、代码实现及详解
实现环境:Google colab Pro
准备工作(库和模块的导入)
可视化进度条
# 安装可以可视化进度条的库pytorch-ignite
!pip install pytorch-ignite
使用这个库训练模型时,不需要写一大堆前向传播,后向传播等代码,直接调用库,就可以可视化loss、准确率、训练轮数的进度条;
导入使用的模块
import os
import cv2
import glob
import torch
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from tqdm import tqdm
from ignite.metrics.confusion_matrix import ConfusionMatrix
from ignite.metrics import mIoU, IoU
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import random
from random import randint
from torch import optim
np.set_printoptions(precision=3, suppress=True)
# 控制输出结果的精度为3(即小数点后为3位),且小数以科学记数法表示;
数据集导入及数据的处理
数据集导入
如果在本地运行,直接将数据集和代码放在同级目录下;如果在google的colab上运行,需要先将数据集上传到google云盘,之后访问google云盘,将路径切换到云盘下;
# 安装google驱动器以访问数据集(在本机上运行时将以下代码注释)
from google.colab import drive
import os
# 挂载网盘
drive.mount('/content/drive/')
# 切换路径
os.chdir('/content/drive/MyDrive/ColabNotebooks/SegNetonCityscapes-main')
Google的colab中,可以直接在代码行中输入!ls查看当前所在的文件目录,执行完上述代码之后当前文件路径应该变为:Mounted at /content/drive。
!ls
demo.pth net.pt SegNetandIAL.ipynb url.txt
gtFine_trainvaltest README.md SegNet_on_cityscapes.ipynb visdomlog.txt
leftImg8bit_trainvaltest runs SegNet场景分割.ipynb
# 定义训练和验证数据集的文件路径
train_label_data_path = './gtFine_trainvaltest/gtFine/train'
valid_label_data_path = './gtFine_trainvaltest/gtFine/val'
train_img_path = './leftImg8bit_trainvaltest/leftImg8bit/train'
valid_img_path = './leftImg8bit_trainvaltest/leftImg8bit/val'
# 匹配各类图像文件的文件路径,保存在各个列表中,并对各列表进行排序
train_labels = sorted(glob.glob(train_label_data_path+"/*/*_labelIds.png"))
valid_labels = sorted(glob.glob(valid_label_data_path+"/*/*_labelIds.png"))
train_inp = sorted(glob.glob(train_img_path+"/*/*.png"))
valid_inp = sorted(glob.glob(valid_img_path+"/*/*.png"))
此时train_labels列表内的部分如下:
['./gtFine_trainvaltest/gtFine/train/aachen/aachen_000000_000019_gtFine_labelIds.png',
'./gtFine_trainvaltest/gtFine/train/aachen/aachen_000001_000019_gtFine_labelIds.png',
'./gtFine_trainvaltest/gtFine/train/aachen/aachen_000002_000019_gtFine_labelIds.png',
'./gtFine_trainvaltest/gtFine/train/aachen/aachen_000003_000019_gtFine_labelIds.png',
'./gtFine_trainvaltest/gtFine/train/aachen/aachen_000004_000019_gtFine_labelIds.png',
'./gtFine_trainvaltest/gtFine/train/aachen/aachen_000005_000019_gtFine_labelIds.png',
'./gtFine_trainvaltest/gtFine/train/aachen/aachen_000006_000019_gtFine_labelIds.png',
'./gtFine_trainvaltest/gtFine/train/aachen/aachen_000007_000019_gtFine_labelIds.png',
'./gtFine_trainvaltest/gtFine/train/aachen/aachen_000008_000019_gtFine_labelIds.png',
...]
此时满足训练集(train_labels)中第一张图片对应的分割,恰好是训练集分割(train_inp)中的第一张图片,以此类推,训练集和训练集的分割、验证集和验证集的分割,都是一一有序对应的。
Label和Label有关的元数据信息
from collections import namedtuple
Label = namedtuple( 'Label' , [
'name' , # label的名字,例如:car、person...,注意名字不会重复
'id' , # 一个label唯一对应一个不重复的Id
'trainId' , # 对用于训练的label设置的Id,由用户自己制定,可以重复
'ignoreInEval', # 在评估过程中,是否忽略该label
'color' , # label对应的颜色
] )
namedtuple介绍
Python 中的 namedtuple 是一种不可变的、命名的元组。与普通元组不同,namedtuple 元素可以通过名称访问,而不仅仅是通过索引。
collections.namedtuple(typename, field_names, *, verbose=False, rename=False, module=None)
命名元组的语法更加清晰,代码更加简洁,而且易于阅读和维护,因此在一些特定场景下它是非常有用的,例如数据处理和结构化数据存储。
具体的各label的信息
#--------------------------------------------------------------------------------
# 所有标签的信息;
#--------------------------------------------------------------------------------
labels = [
Label( 'unlabeled' , 0 , 255 , True , ( 0, 0, 0) ),
Label( 'ego vehicle' , 1 , 255 , True , ( 0, 0, 0) ),
Label( 'rectification border' , 2 , 255 , True , ( 0, 0, 0) ),
Label( 'out of roi' , 3 , 255 , True , ( 0, 0, 0) ),
Label( 'static' , 4 , 255 , True , ( 0, 0, 0) ),
Label( 'dynamic' , 5 , 255 , True , (111, 74, 0) ),
Label( 'ground' , 6 , 255 , True , ( 81, 0, 81) ),
Label( 'road' , 7 , 0 , False , (128, 64,128) ),
Label( 'sidewalk' , 8 , 1 , False , (244, 35,232) ),
Label( 'parking' , 9 , 255 , True , (250,170,160) ),
Label( 'rail track' , 10 , 255 , True , (230,150,140) ),
Label( 'building' , 11 , 2 , False , ( 70, 70, 70) ),
Label( 'wall' , 12 , 3 , False , (102,102,156) ),
Label( 'fence' , 13 , 4 , False , (190,153,153) ),
Label( 'guard rail' , 14 , 255 , True , (180,165,180) ),
Label( 'bridge' , 15 , 255 , True , (150,100,100) ),
Label( 'tunnel' , 16 , 255 , True , (150,120, 90) ),
Label( 'pole' , 17 , 5 , False , (153,153,153) ),
Label( 'polegroup' , 18 , 255 , True , (153,153,153) ),
Label( 'traffic light' , 19 , 6 , False , (250,170, 30) ),
Label( 'traffic sign' , 20 , 7 , False , (220,220, 0) ),
Label( 'vegetation' , 21 , 8 , False , (107,142, 35) ),
Label( 'terrain' , 22 , 9 , False , (152,251,152) ),
Label( 'sky' , 23 , 10 , False , ( 70,130,180) ),
Label( 'person' , 24 , 11 , False , (220, 20, 60) ),
Label( 'rider' , 25 , 12 , False , (255, 0, 0) ),
Label( 'car' , 26 , 13 , False , ( 0, 0,142) ),
Label( 'truck' , 27 , 14 , False , ( 0, 0, 70) ),
Label( 'bus' , 28 , 15 , False , ( 0, 60,100) ),
Label( 'caravan' , 29 , 255 , True , ( 0, 0, 90) ),
Label( 'trailer' , 30 , 255 , True , ( 0, 0,110) ),
Label( 'train' , 31 , 16 , False , ( 0, 80,100) ),
Label( 'motorcycle' , 32 , 17 , False , ( 0, 0,230) ),
Label( 'bicycle' , 33 , 18 , False , (119, 11, 32) ),
Label( 'license plate' , -1 , -1 , True , ( 0, 0,142) ),
]
数据处理
提取用于训练的label
'''
ignoreinEval==False代表使用该label
逐一扫描labels命名元组中的每一个label的信息:
将使用到的label的全部信息都添加到labels_used[]列表中
将使用到的label的id都添加到ids[]列表中
'''
labels_used = []
ids = []
for i in range(len(labels)):
if(labels[i].ignoreInEval == False):
labels_used.append(labels[i])
ids.append(labels[i].id)
print("number of labels used = " + format(len(labels_used )))
输出:
number of labels used = 19
# 此输出代表使用了19个类
可视化第一张图片的分割
读取
# 读取第一张图片的分割,并且只提取红色通道
label_in = cv2.imread(train_labels[0])[:,:,0]
提取红色通道的原因:标签图片为灰度图,标签信息只在红色通道中保存。
标签图片的例子:

肉眼看上去全黑;
提取红色通道之后:

颜色重覆盖
原来的标签图像为灰度图图像,需要转换为彩色分割图。
同时原来的分割是根据label的id属性来上色的,在训练过程中,我们是根据label的train_id属性进行训练的,故需要将相同train_id但不同id的不同颜色的色块变成相同颜色的色块;实质就是在分割的图像上体现出来由用户自己筛选label用于训练的效果。
例如:原始标签图片中bridge和ground是两类,有两个id,对应两个颜色,但是此时我们将它们的train_Id设置成一样的,训练时就会当成一类,最终bridge和ground就会上色成一个颜色;
创建映射关系
'''
创建一个以label的id为键、以train_id为值的字典
id是唯一的,train_id可以重复(重复就是在训练时把它们当成一类,尽管它们本身是不同的物体)
一个id唯一对应一个train_id
'''
label_dic = {
}
for i in range(len(labels)-1):
label_dic[labels[i].id] = labels[i].trainId
此时label_dic中内容:
{0: 255, 1: 255, 2: 255, 3: 255,
4: 255, 5: 255, 6: 255, 7: 0,
8: 1, 9: 255, 10: 255, 11: 2,
12: 3, 13: 4, 14: 255, 15: 255,
16: 255, 17: 5, 18: 255, 19: 6,
20: 7, 21: 8, 22: 9, 23: 10,
24: 11, 25: 12, 26: 13, 27: 14,
28: 15, 29: 255, 30: 255, 31: 16,
32: 17, 33: 18}
train_id为255代表未被筛选出来的类
替换id信息为train_id信息
原始的分割图片中,每一个像素对应一个id,逐像素扫描分割图片,根据label_dic将分割图片中每一个像素的id的信息替换为train_id的信息。
'''
createtrainID函数:
将标签图片中用到的label的id信息逐像素换成对应的train_id信息
输入:
label_in为原始的分割图像
label_dic为一个以id为键、以train_id为值的字典
输出:
mask矩阵,矩阵大小为图像像素大小,即存有标签图片每个像素点对应的train_id
'''
def createtrainID(label_in,label_dic):
mask = np.zeros((label_in.shape[0],label_in.shape[1]))
l_un = np.unique(label_in) # unique()用于去重并排序
for i in range(len(l_un)):
mask[label_in==l_un[i]] = label_dic[l_un[i]]
return mask
重新根据train_id上色
'''
visual_label()函数:
根据train_id来重新上色生成训练用的分割图片
输入:
mask矩阵:一个图像长*宽大小的矩阵,矩阵中的每一个元素代表图像在该像素点的train_Id;
labels_used:对图像场景分割时,训练用到的所有label的label信息;
plot:plot为True时,显示图像;
输出:
返回重新上色之后的图片;
'''
def visual_label(mask,labels_used,plot = False):
label_img = np.zeros((mask.shape[0],mask.shape[1],3))
# RGB三通道
r = np.zeros((mask.shape[0],mask.shape[1]))
g = np.zeros((mask.shape[0],mask.shape[1]))
b = np.zeros((mask.shape[0],mask.shape[1]))
l_un = np.unique(mask)
for i in  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 983
983

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











