 Python单元测试与数据驱动测试实战
Python单元测试与数据驱动测试实战





 本文介绍了如何使用Python的unittest模块进行单元测试,包括测试用例的编写、测试套件的创建和运行。同时,展示了ddt库在数据驱动测试中的应用,通过读取Excel数据进行多条测试用例的生成。此外,还涉及到了日志记录和配置文件的操作,以及JSON数据的读写。
本文介绍了如何使用Python的unittest模块进行单元测试,包括测试用例的编写、测试套件的创建和运行。同时,展示了ddt库在数据驱动测试中的应用,通过读取Excel数据进行多条测试用例的生成。此外,还涉及到了日志记录和配置文件的操作,以及JSON数据的读写。

import unittest
def login(user,password):
if user == 'mumu' and password == 123456:
return '成功'
else:
return '失败'
"""
unitest测试用例编写规范
1、定义一个测试用例类,必须继承unitest模块中的TestCase
2、测试用例类中,一个test开头的方法就是一条测试用例
3、将测试用例执行的逻辑写到对应的测试方法中
#1:准备用例数据
#2:调用被测的功能函数(发送接口调用数据)获取实际结果
# 3 断言
fixture:测试夹具 用例级别和类级别
"""
class TestLogin(unittest.TestCase):
# 用例前置脚本
def setUp(self):
print(11)
# 用例后置脚本
def tearDown(self):
print('teardown')
def test_login_pass(self):
params = {
'user': 'mumu',
'password': 123456
}
res = login(**params)
assert '成功' == res
def test_login_error(self):
params = {
'user': 'mumu1',
'password': 123456
}
res = login(**params)
assert '失败' == res
创建run.py文件运行用例
"""
1 创建测试套件,加载测试用例到套件
2 创建一个测试用例运行程序
3 运行测试用例
"""
import unittest
# 创建套件
# suite = unittest.TestSuite()
# # 创建一个用例加载器
# load =unittest.TestLoader()
# # 加载测试用例到套件
# suite.addTest(load.discover(r'E:\testzidonghua\student\data'))
# 上面三行简写一行
su = unittest.defaultTestLoader.discover(r'E:\testzidonghua\student\data')
# 第二步:创建一个测试用例运行程序
runner = unittest.TextTestRunner()
# 第三不:运行测试用例
runner.run(su)
ddt
"""
unitest执行顺序:同一个类根据ascll码排序,同一个文件有多个类的ascll码排序
ddt使用步骤:
1 测试类前面使用@ddt
2 在测试方法前使用@list_ddt
"""
import unittest
from unittestreport import ddt,list_data
import openpyxl
from funkexun import login
workbook = openpyxl.load_workbook('yi.xlsx')
sh = workbook['Sheet1']
res = list(sh.rows)
title = [i.value for i in res[0]]
# 获取第二行以后的字典形式的数据
cases = []
for item in res[1:]:
r2 = [i.value for i in item]
r3 = dict(zip(title,r2))
cases.append(r3)
print(cases)
@ddt
class TestLogin(unittest.TestCase):
@list_data(cases)
def test01(self, item):
print(item)
expeted = '成功'
params = item
res = login(**params)
print(res)
self.assertEqual(expeted,res)
excel
"""
excel
"""
import openpyxl
# 加载excel文件为工作簿对象
workbook = openpyxl.load_workbook('yongli1.xlsx')
# 获取所有的表单名字
print(workbook.sheetnames)
# 选中表单
sh =workbook['Sheet1']
# 读取数据
c = sh.cell(row=2 ,column=2)
print(c.value)
# --------------------获取所有的数据----------
# rows:按行所有的数据
res = list(sh.rows)
# 获取第一行的数据
title = [i.value for i in res[0]]
print(title)
# 获取第二行以后的字典形式的数据
cases = []
for item in res[1:]:
r2 = [i.value for i in item]
r3 = dict(zip(title,r2))
cases.append(r3)
print(cases)
logiing日志
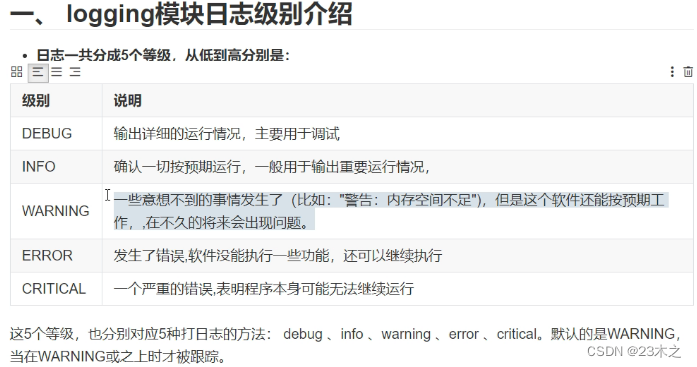
控制台输出日志
"""
logging.getLogger('senlin')创建日志收集器
创建日志收集器不传name参数,返回的是默认的收集器(root)
传name会创建一个新的日志收集器
"""
import logging
log = logging.getLogger('senlin')
# 设置日志收集器收集日志的等级
log.setLevel('DEBUG')
# 设置输出日志的等级
# 1 设置日志输出的渠道(控制台)
sh = logging.StreamHandler()
sh.setLevel('DEBUG')
# 2 将输出渠道绑定到日志收集器上
log.addHandler(sh)
log.debug('__debug__')
log.info('__info__')
log.warning('__warning__')
log.error('__error__')
log.critical('__critical__')


操作配置文件
from configparser import ConfigParser
# 第一步:创建配置文件解析器对象
cp = ConfigParser()
# 第二步:读取配置文件中的内容到配置文件解析器中
cp.read('musen.ini')
# 第三步:读取配置内容
# 方法一:get:使用get方法读取的配置内容都会当成字符串
res = cp.get('logging', 'file')
print(res)
# 方法一:getint:使用get方法读取的配置内容都会当成字符串
res2 = cp.getint('mysql','port')
print(res2)
json
"""
json数据和python数据的差异点:
python中的数据为空:None json:null
"""
import json
with open('data.json', 'r', encoding='utf-8') as f:
res = json.load(f)
print(res, type(res))
dic = {'a': None,'b': 'python','c':False}
# 将python数据转为json
resd = json.dumps(dic)
print(resd)
# 将json转为python
respyth = json.loads(resd)
print(respyth)


















 942
942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









