DPN(ResNet与DenseNet结合)
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os, PIL, pathlib, warnings
warnings.filterwarnings("ignore")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
import os,PIL,random,pathlib
data_dir_str = r'C:\Users\11054\Desktop\kLearning\J1_learning\bird_photos'
data_dir = pathlib.Path(data_dir_str)
print("data_dir:", data_dir, "\n")
data_paths = list(data_dir.glob('*'))
classNames = [str(path).split('/')[-1] for path in data_paths]
print('classNames:', classNames , '\n')
train_transforms = transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
total_data = datasets.ImageFolder(data_dir_str, transform=train_transforms)
print(total_data)
print(total_data.class_to_idx)
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
print(train_dataset, test_dataset)
batch_size = 4
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1,
pin_memory=False)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1,
pin_memory=False)
for X, y in test_dl:
print("Shape of X [N, C, H, W]:", X.shape)
print("Shape of y:", y.shape, y.dtype)
break
import torch
import torch.nn as nn
class Block(nn.Module):
"""
param : in_channel--输入通道数
mid_channel -- 中间经历的通道数
out_channel -- ResNet部分使用的通道数(sum操作,这部分输出仍然是out_channel个通道)
dense_channel -- DenseNet部分使用的通道数(concat操作,这部分输出是2*dense_channel个通道)
groups -- conv2中的分组卷积参数
is_shortcut -- ResNet前是否进行shortcut操作
"""
def __init__(self, in_channel, mid_channel, out_channel, dense_channel, stride, groups, is_shortcut=False):
super(Block, self).__init__()
self.is_shortcut = is_shortcut
self.out_channel = out_channel
self.conv1 = nn.Sequential(
nn.Conv2d(in_channel, mid_channel, kernel_size=1, bias=False),
nn.BatchNorm2d(mid_channel),
nn.ReLU()
)
self.conv2 = nn.Sequential(
nn.Conv2d(mid_channel, mid_channel, kernel_size=3, stride=stride, padding=1, groups=groups, bias=False),
nn.BatchNorm2d(mid_channel),
nn.ReLU()
)
self.conv3 = nn.Sequential(
nn.Conv2d(mid_channel, out_channel+dense_channel, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channel+dense_channel)
)
if self.is_shortcut:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channel, out_channel+dense_channel, kernel_size=3, padding=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channel+dense_channel)
)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
a = x
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
if self.is_shortcut:
a = self.shortcut(a)
x = torch.cat([a[:, :self.out_channel, :, :]+x[:, :self.out_channel, :, :], a[:, self.out_channel:, :, :], x[:, self.out_channel:, :, :]], dim=1)
x = self.relu(x)
return x
class DPN(nn.Module):
def __init__(self, cfg):
super(DPN, self).__init__()
self.group = cfg['group']
self.in_channel = cfg['in_channel']
mid_channels = cfg['mid_channels']
out_channels = cfg['out_channels']
dense_channels = cfg['dense_channels']
num = cfg['num']
self.conv1 = nn.Sequential(
nn.Conv2d(3, self.in_channel, 7, stride=2, padding=3, bias=False, padding_mode='zeros'),
nn.BatchNorm2d(self.in_channel),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=0)
)
self.conv2 = self._make_layers(mid_channels[0], out_channels[0], dense_channels[0], num[0], stride=1)
self.conv3 = self._make_layers(mid_channels[1], out_channels[1], dense_channels[1], num[1], stride=2)
self.conv4 = self._make_layers(mid_channels[2], out_channels[2], dense_channels[2], num[2], stride=2)
self.conv5 = self._make_layers(mid_channels[3], out_channels[3], dense_channels[3], num[3], stride=2)
self.pool = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(cfg['out_channels'][3] + (num[3] + 1) * cfg['dense_channels'][3], cfg['classes'])
def _make_layers(self, mid_channel, out_channel, dense_channel, num, stride):
layers = []
layers.append(Block(self.in_channel, mid_channel, out_channel, dense_channel, stride=stride, groups=self.group, is_shortcut=True))
self.in_channel = out_channel + dense_channel*2
for i in range(1, num):
layers.append(Block(self.in_channel, mid_channel, out_channel, dense_channel, stride=1, groups=self.group))
self.in_channel += dense_channel
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.pool(x)
x = torch.flatten(x, start_dim=1)
x = self.fc(x)
return x
def DPN92(n_class=4):
cfg = {
"group" : 32,
"in_channel" : 64,
"mid_channels" : (96, 192, 384, 768),
"out_channels" : (256, 512, 1024, 2048),
"dense_channels" : (16, 32, 24, 128),
"num" : (3, 4, 20, 3),
"classes" : (n_class)
}
return DPN(cfg)
def DPN98(n_class=4):
cfg = {
"group" : 40,
"in_channel" : 96,
"mid_channels" : (160, 320, 640, 1280),
"out_channels" : (256, 512, 1024, 2048),
"dense_channels" : (16, 32, 32, 128),
"num" : (3, 6, 20, 3),
"classes" : (n_class)
}
return DPN(cfg)
model = DPN92().to(device)
import torchsummary as summary
summary.summary(model, (3, 224, 224))
cuda
data_dir: C:\Users\11054\Desktop\kLearning\J1_learning\bird_photos
classNames: ['C:\\Users\\11054\\Desktop\\kLearning\\J1_learning\\bird_photos\\Bananaquit', 'C:\\Users\\11054\\Desktop\\kLearning\\J1_learning\\bird_photos\\Black Skimmer', 'C:\\Users\\11054\\Desktop\\kLearning\\J1_learning\\bird_photos\\Black Throated Bushtiti', 'C:\\Users\\11054\\Desktop\\kLearning\\J1_learning\\bird_photos\\Cockatoo']
Dataset ImageFolder
Number of datapoints: 565
Root location: C:\Users\11054\Desktop\kLearning\J1_learning\bird_photos
StandardTransform
Transform: Compose(
Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=True)
ToTensor()
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
)
{'Bananaquit': 0, 'Black Skimmer': 1, 'Black Throated Bushtiti': 2, 'Cockatoo': 3}
<torch.utils.data.dataset.Subset object at 0x0000023C6A0BD880> <torch.utils.data.dataset.Subset object at 0x0000023C6D151280>
Shape of X [N, C, H, W]: torch.Size([4, 3, 224, 224])
Shape of y: torch.Size([4]) torch.int64
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 55, 55] 0
Conv2d-5 [-1, 96, 55, 55] 6,144
BatchNorm2d-6 [-1, 96, 55, 55] 192
ReLU-7 [-1, 96, 55, 55] 0
Conv2d-8 [-1, 96, 55, 55] 2,592
BatchNorm2d-9 [-1, 96, 55, 55] 192
ReLU-10 [-1, 96, 55, 55] 0
Conv2d-11 [-1, 272, 55, 55] 26,112
BatchNorm2d-12 [-1, 272, 55, 55] 544
Conv2d-13 [-1, 272, 55, 55] 156,672
BatchNorm2d-14 [-1, 272, 55, 55] 544
ReLU-15 [-1, 288, 55, 55] 0
Block-16 [-1, 288, 55, 55] 0
Conv2d-17 [-1, 96, 55, 55] 27,648
BatchNorm2d-18 [-1, 96, 55, 55] 192
ReLU-19 [-1, 96, 55, 55] 0
Conv2d-20 [-1, 96, 55, 55] 2,592
BatchNorm2d-21 [-1, 96, 55, 55] 192
ReLU-22 [-1, 96, 55, 55] 0
Conv2d-23 [-1, 272, 55, 55] 26,112
BatchNorm2d-24 [-1, 272, 55, 55] 544
ReLU-25 [-1, 304, 55, 55] 0
Block-26 [-1, 304, 55, 55] 0
Conv2d-27 [-1, 96, 55, 55] 29,184
BatchNorm2d-28 [-1, 96, 55, 55] 192
ReLU-29 [-1, 96, 55, 55] 0
Conv2d-30 [-1, 96, 55, 55] 2,592
BatchNorm2d-31 [-1, 96, 55, 55] 192
ReLU-32 [-1, 96, 55, 55] 0
Conv2d-33 [-1, 272, 55, 55] 26,112
BatchNorm2d-34 [-1, 272, 55, 55] 544
ReLU-35 [-1, 320, 55, 55] 0
Block-36 [-1, 320, 55, 55] 0
Conv2d-37 [-1, 192, 55, 55] 61,440
BatchNorm2d-38 [-1, 192, 55, 55] 384
ReLU-39 [-1, 192, 55, 55] 0
Conv2d-40 [-1, 192, 28, 28] 10,368
BatchNorm2d-41 [-1, 192, 28, 28] 384
ReLU-42 [-1, 192, 28, 28] 0
Conv2d-43 [-1, 544, 28, 28] 104,448
BatchNorm2d-44 [-1, 544, 28, 28] 1,088
Conv2d-45 [-1, 544, 28, 28] 1,566,720
BatchNorm2d-46 [-1, 544, 28, 28] 1,088
ReLU-47 [-1, 576, 28, 28] 0
Block-48 [-1, 576, 28, 28] 0
Conv2d-49 [-1, 192, 28, 28] 110,592
BatchNorm2d-50 [-1, 192, 28, 28] 384
ReLU-51 [-1, 192, 28, 28] 0
Conv2d-52 [-1, 192, 28, 28] 10,368
BatchNorm2d-53 [-1, 192, 28, 28] 384
ReLU-54 [-1, 192, 28, 28] 0
Conv2d-55 [-1, 544, 28, 28] 104,448
BatchNorm2d-56 [-1, 544, 28, 28] 1,088
ReLU-57 [-1, 608, 28, 28] 0
Block-58 [-1, 608, 28, 28] 0
Conv2d-59 [-1, 192, 28, 28] 116,736
BatchNorm2d-60 [-1, 192, 28, 28] 384
ReLU-61 [-1, 192, 28, 28] 0
Conv2d-62 [-1, 192, 28, 28] 10,368
BatchNorm2d-63 [-1, 192, 28, 28] 384
ReLU-64 [-1, 192, 28, 28] 0
Conv2d-65 [-1, 544, 28, 28] 104,448
BatchNorm2d-66 [-1, 544, 28, 28] 1,088
ReLU-67 [-1, 640, 28, 28] 0
Block-68 [-1, 640, 28, 28] 0
Conv2d-69 [-1, 192, 28, 28] 122,880
BatchNorm2d-70 [-1, 192, 28, 28] 384
ReLU-71 [-1, 192, 28, 28] 0
Conv2d-72 [-1, 192, 28, 28] 10,368
BatchNorm2d-73 [-1, 192, 28, 28] 384
ReLU-74 [-1, 192, 28, 28] 0
Conv2d-75 [-1, 544, 28, 28] 104,448
BatchNorm2d-76 [-1, 544, 28, 28] 1,088
ReLU-77 [-1, 672, 28, 28] 0
Block-78 [-1, 672, 28, 28] 0
Conv2d-79 [-1, 384, 28, 28] 258,048
BatchNorm2d-80 [-1, 384, 28, 28] 768
ReLU-81 [-1, 384, 28, 28] 0
Conv2d-82 [-1, 384, 14, 14] 41,472
BatchNorm2d-83 [-1, 384, 14, 14] 768
ReLU-84 [-1, 384, 14, 14] 0
Conv2d-85 [-1, 1048, 14, 14] 402,432
BatchNorm2d-86 [-1, 1048, 14, 14] 2,096
Conv2d-87 [-1, 1048, 14, 14] 6,338,304
BatchNorm2d-88 [-1, 1048, 14, 14] 2,096
ReLU-89 [-1, 1072, 14, 14] 0
Block-90 [-1, 1072, 14, 14] 0
Conv2d-91 [-1, 384, 14, 14] 411,648
BatchNorm2d-92 [-1, 384, 14, 14] 768
ReLU-93 [-1, 384, 14, 14] 0
Conv2d-94 [-1, 384, 14, 14] 41,472
BatchNorm2d-95 [-1, 384, 14, 14] 768
ReLU-96 [-1, 384, 14, 14] 0
Conv2d-97 [-1, 1048, 14, 14] 402,432
BatchNorm2d-98 [-1, 1048, 14, 14] 2,096
ReLU-99 [-1, 1096, 14, 14] 0
Block-100 [-1, 1096, 14, 14] 0
Conv2d-101 [-1, 384, 14, 14] 420,864
BatchNorm2d-102 [-1, 384, 14, 14] 768
ReLU-103 [-1, 384, 14, 14] 0
Conv2d-104 [-1, 384, 14, 14] 41,472
BatchNorm2d-105 [-1, 384, 14, 14] 768
ReLU-106 [-1, 384, 14, 14] 0
Conv2d-107 [-1, 1048, 14, 14] 402,432
BatchNorm2d-108 [-1, 1048, 14, 14] 2,096
ReLU-109 [-1, 1120, 14, 14] 0
Block-110 [-1, 1120, 14, 14] 0
Conv2d-111 [-1, 384, 14, 14] 430,080
BatchNorm2d-112 [-1, 384, 14, 14] 768
ReLU-113 [-1, 384, 14, 14] 0
Conv2d-114 [-1, 384, 14, 14] 41,472
BatchNorm2d-115 [-1, 384, 14, 14] 768
ReLU-116 [-1, 384, 14, 14] 0
Conv2d-117 [-1, 1048, 14, 14] 402,432
BatchNorm2d-118 [-1, 1048, 14, 14] 2,096
ReLU-119 [-1, 1144, 14, 14] 0
Block-120 [-1, 1144, 14, 14] 0
Conv2d-121 [-1, 384, 14, 14] 439,296
BatchNorm2d-122 [-1, 384, 14, 14] 768
ReLU-123 [-1, 384, 14, 14] 0
Conv2d-124 [-1, 384, 14, 14] 41,472
BatchNorm2d-125 [-1, 384, 14, 14] 768
ReLU-126 [-1, 384, 14, 14] 0
Conv2d-127 [-1, 1048, 14, 14] 402,432
BatchNorm2d-128 [-1, 1048, 14, 14] 2,096
ReLU-129 [-1, 1168, 14, 14] 0
Block-130 [-1, 1168, 14, 14] 0
Conv2d-131 [-1, 384, 14, 14] 448,512
BatchNorm2d-132 [-1, 384, 14, 14] 768
ReLU-133 [-1, 384, 14, 14] 0
Conv2d-134 [-1, 384, 14, 14] 41,472
BatchNorm2d-135 [-1, 384, 14, 14] 768
ReLU-136 [-1, 384, 14, 14] 0
Conv2d-137 [-1, 1048, 14, 14] 402,432
BatchNorm2d-138 [-1, 1048, 14, 14] 2,096
ReLU-139 [-1, 1192, 14, 14] 0
Block-140 [-1, 1192, 14, 14] 0
Conv2d-141 [-1, 384, 14, 14] 457,728
BatchNorm2d-142 [-1, 384, 14, 14] 768
ReLU-143 [-1, 384, 14, 14] 0
Conv2d-144 [-1, 384, 14, 14] 41,472
BatchNorm2d-145 [-1, 384, 14, 14] 768
ReLU-146 [-1, 384, 14, 14] 0
Conv2d-147 [-1, 1048, 14, 14] 402,432
BatchNorm2d-148 [-1, 1048, 14, 14] 2,096
ReLU-149 [-1, 1216, 14, 14] 0
Block-150 [-1, 1216, 14, 14] 0
Conv2d-151 [-1, 384, 14, 14] 466,944
BatchNorm2d-152 [-1, 384, 14, 14] 768
ReLU-153 [-1, 384, 14, 14] 0
Conv2d-154 [-1, 384, 14, 14] 41,472
BatchNorm2d-155 [-1, 384, 14, 14] 768
ReLU-156 [-1, 384, 14, 14] 0
Conv2d-157 [-1, 1048, 14, 14] 402,432
BatchNorm2d-158 [-1, 1048, 14, 14] 2,096
ReLU-159 [-1, 1240, 14, 14] 0
Block-160 [-1, 1240, 14, 14] 0
Conv2d-161 [-1, 384, 14, 14] 476,160
BatchNorm2d-162 [-1, 384, 14, 14] 768
ReLU-163 [-1, 384, 14, 14] 0
Conv2d-164 [-1, 384, 14, 14] 41,472
BatchNorm2d-165 [-1, 384, 14, 14] 768
ReLU-166 [-1, 384, 14, 14] 0
Conv2d-167 [-1, 1048, 14, 14] 402,432
BatchNorm2d-168 [-1, 1048, 14, 14] 2,096
ReLU-169 [-1, 1264, 14, 14] 0
Block-170 [-1, 1264, 14, 14] 0
Conv2d-171 [-1, 384, 14, 14] 485,376
BatchNorm2d-172 [-1, 384, 14, 14] 768
ReLU-173 [-1, 384, 14, 14] 0
Conv2d-174 [-1, 384, 14, 14] 41,472
BatchNorm2d-175 [-1, 384, 14, 14] 768
ReLU-176 [-1, 384, 14, 14] 0
Conv2d-177 [-1, 1048, 14, 14] 402,432
BatchNorm2d-178 [-1, 1048, 14, 14] 2,096
ReLU-179 [-1, 1288, 14, 14] 0
Block-180 [-1, 1288, 14, 14] 0
Conv2d-181 [-1, 384, 14, 14] 494,592
BatchNorm2d-182 [-1, 384, 14, 14] 768
ReLU-183 [-1, 384, 14, 14] 0
Conv2d-184 [-1, 384, 14, 14] 41,472
BatchNorm2d-185 [-1, 384, 14, 14] 768
ReLU-186 [-1, 384, 14, 14] 0
Conv2d-187 [-1, 1048, 14, 14] 402,432
BatchNorm2d-188 [-1, 1048, 14, 14] 2,096
ReLU-189 [-1, 1312, 14, 14] 0
Block-190 [-1, 1312, 14, 14] 0
Conv2d-191 [-1, 384, 14, 14] 503,808
BatchNorm2d-192 [-1, 384, 14, 14] 768
ReLU-193 [-1, 384, 14, 14] 0
Conv2d-194 [-1, 384, 14, 14] 41,472
BatchNorm2d-195 [-1, 384, 14, 14] 768
ReLU-196 [-1, 384, 14, 14] 0
Conv2d-197 [-1, 1048, 14, 14] 402,432
BatchNorm2d-198 [-1, 1048, 14, 14] 2,096
ReLU-199 [-1, 1336, 14, 14] 0
Block-200 [-1, 1336, 14, 14] 0
Conv2d-201 [-1, 384, 14, 14] 513,024
BatchNorm2d-202 [-1, 384, 14, 14] 768
ReLU-203 [-1, 384, 14, 14] 0
Conv2d-204 [-1, 384, 14, 14] 41,472
BatchNorm2d-205 [-1, 384, 14, 14] 768
ReLU-206 [-1, 384, 14, 14] 0
Conv2d-207 [-1, 1048, 14, 14] 402,432
BatchNorm2d-208 [-1, 1048, 14, 14] 2,096
ReLU-209 [-1, 1360, 14, 14] 0
Block-210 [-1, 1360, 14, 14] 0
Conv2d-211 [-1, 384, 14, 14] 522,240
BatchNorm2d-212 [-1, 384, 14, 14] 768
ReLU-213 [-1, 384, 14, 14] 0
Conv2d-214 [-1, 384, 14, 14] 41,472
BatchNorm2d-215 [-1, 384, 14, 14] 768
ReLU-216 [-1, 384, 14, 14] 0
Conv2d-217 [-1, 1048, 14, 14] 402,432
BatchNorm2d-218 [-1, 1048, 14, 14] 2,096
ReLU-219 [-1, 1384, 14, 14] 0
Block-220 [-1, 1384, 14, 14] 0
Conv2d-221 [-1, 384, 14, 14] 531,456
BatchNorm2d-222 [-1, 384, 14, 14] 768
ReLU-223 [-1, 384, 14, 14] 0
Conv2d-224 [-1, 384, 14, 14] 41,472
BatchNorm2d-225 [-1, 384, 14, 14] 768
ReLU-226 [-1, 384, 14, 14] 0
Conv2d-227 [-1, 1048, 14, 14] 402,432
BatchNorm2d-228 [-1, 1048, 14, 14] 2,096
ReLU-229 [-1, 1408, 14, 14] 0
Block-230 [-1, 1408, 14, 14] 0
Conv2d-231 [-1, 384, 14, 14] 540,672
BatchNorm2d-232 [-1, 384, 14, 14] 768
ReLU-233 [-1, 384, 14, 14] 0
Conv2d-234 [-1, 384, 14, 14] 41,472
BatchNorm2d-235 [-1, 384, 14, 14] 768
ReLU-236 [-1, 384, 14, 14] 0
Conv2d-237 [-1, 1048, 14, 14] 402,432
BatchNorm2d-238 [-1, 1048, 14, 14] 2,096
ReLU-239 [-1, 1432, 14, 14] 0
Block-240 [-1, 1432, 14, 14] 0
Conv2d-241 [-1, 384, 14, 14] 549,888
BatchNorm2d-242 [-1, 384, 14, 14] 768
ReLU-243 [-1, 384, 14, 14] 0
Conv2d-244 [-1, 384, 14, 14] 41,472
BatchNorm2d-245 [-1, 384, 14, 14] 768
ReLU-246 [-1, 384, 14, 14] 0
Conv2d-247 [-1, 1048, 14, 14] 402,432
BatchNorm2d-248 [-1, 1048, 14, 14] 2,096
ReLU-249 [-1, 1456, 14, 14] 0
Block-250 [-1, 1456, 14, 14] 0
Conv2d-251 [-1, 384, 14, 14] 559,104
BatchNorm2d-252 [-1, 384, 14, 14] 768
ReLU-253 [-1, 384, 14, 14] 0
Conv2d-254 [-1, 384, 14, 14] 41,472
BatchNorm2d-255 [-1, 384, 14, 14] 768
ReLU-256 [-1, 384, 14, 14] 0
Conv2d-257 [-1, 1048, 14, 14] 402,432
BatchNorm2d-258 [-1, 1048, 14, 14] 2,096
ReLU-259 [-1, 1480, 14, 14] 0
Block-260 [-1, 1480, 14, 14] 0
Conv2d-261 [-1, 384, 14, 14] 568,320
BatchNorm2d-262 [-1, 384, 14, 14] 768
ReLU-263 [-1, 384, 14, 14] 0
Conv2d-264 [-1, 384, 14, 14] 41,472
BatchNorm2d-265 [-1, 384, 14, 14] 768
ReLU-266 [-1, 384, 14, 14] 0
Conv2d-267 [-1, 1048, 14, 14] 402,432
BatchNorm2d-268 [-1, 1048, 14, 14] 2,096
ReLU-269 [-1, 1504, 14, 14] 0
Block-270 [-1, 1504, 14, 14] 0
Conv2d-271 [-1, 384, 14, 14] 577,536
BatchNorm2d-272 [-1, 384, 14, 14] 768
ReLU-273 [-1, 384, 14, 14] 0
Conv2d-274 [-1, 384, 14, 14] 41,472
BatchNorm2d-275 [-1, 384, 14, 14] 768
ReLU-276 [-1, 384, 14, 14] 0
Conv2d-277 [-1, 1048, 14, 14] 402,432
BatchNorm2d-278 [-1, 1048, 14, 14] 2,096
ReLU-279 [-1, 1528, 14, 14] 0
Block-280 [-1, 1528, 14, 14] 0
Conv2d-281 [-1, 768, 14, 14] 1,173,504
BatchNorm2d-282 [-1, 768, 14, 14] 1,536
ReLU-283 [-1, 768, 14, 14] 0
Conv2d-284 [-1, 768, 7, 7] 165,888
BatchNorm2d-285 [-1, 768, 7, 7] 1,536
ReLU-286 [-1, 768, 7, 7] 0
Conv2d-287 [-1, 2176, 7, 7] 1,671,168
BatchNorm2d-288 [-1, 2176, 7, 7] 4,352
Conv2d-289 [-1, 2176, 7, 7] 29,924,352
BatchNorm2d-290 [-1, 2176, 7, 7] 4,352
ReLU-291 [-1, 2304, 7, 7] 0
Block-292 [-1, 2304, 7, 7] 0
Conv2d-293 [-1, 768, 7, 7] 1,769,472
BatchNorm2d-294 [-1, 768, 7, 7] 1,536
ReLU-295 [-1, 768, 7, 7] 0
Conv2d-296 [-1, 768, 7, 7] 165,888
BatchNorm2d-297 [-1, 768, 7, 7] 1,536
ReLU-298 [-1, 768, 7, 7] 0
Conv2d-299 [-1, 2176, 7, 7] 1,671,168
BatchNorm2d-300 [-1, 2176, 7, 7] 4,352
ReLU-301 [-1, 2432, 7, 7] 0
Block-302 [-1, 2432, 7, 7] 0
Conv2d-303 [-1, 768, 7, 7] 1,867,776
BatchNorm2d-304 [-1, 768, 7, 7] 1,536
ReLU-305 [-1, 768, 7, 7] 0
Conv2d-306 [-1, 768, 7, 7] 165,888
BatchNorm2d-307 [-1, 768, 7, 7] 1,536
ReLU-308 [-1, 768, 7, 7] 0
Conv2d-309 [-1, 2176, 7, 7] 1,671,168
BatchNorm2d-310 [-1, 2176, 7, 7] 4,352
ReLU-311 [-1, 2560, 7, 7] 0
Block-312 [-1, 2560, 7, 7] 0
AdaptiveAvgPool2d-313 [-1, 2560, 1, 1] 0
Linear-314 [-1, 4] 10,244
================================================================
Total params: 67,994,324
Trainable params: 67,994,324
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 489.24
Params size (MB): 259.38
Estimated Total Size (MB): 749.20
----------------------------------------------------------------
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
num_batches = len(dataloader)
train_loss, train_acc = 0, 0
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, test_acc = 0, 0
for imgs, target in dataloader:
with torch.no_grad():
imgs, target = imgs.to(device), target.to(device)
tartget_pred = model(imgs)
loss = loss_fn(tartget_pred, target)
test_loss += loss.item()
test_acc += (tartget_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
import copy
optimizer = torch.optim.Adam(model.parameters(), lr = 1e-4)
loss_fn = nn.CrossEntropyLoss()
epochs = 40
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_acc = 0
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
if epoch_test_acc > best_acc:
best_acc = epoch_test_acc
best_model = copy.deepcopy(model)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
lr = optimizer.state_dict()['param_groups'][0]['lr']
template = ('Epoch: {:2d}. Train_acc: {:.1f}%, Train_loss: {:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr: {:.2E}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss, lr))
PATH = r'C:\Users\11054\Desktop\kLearning\J4_learning\J3_best_model.pth'
torch.save(model.state_dict(), PATH)
print('Done')
Epoch: 1. Train_acc: 42.3%, Train_loss: 1.389, Test_acc:48.7%, Test_loss:2.097, Lr: 1.00E-04
Epoch: 2. Train_acc: 63.5%, Train_loss: 0.933, Test_acc:53.1%, Test_loss:2.493, Lr: 1.00E-04
Epoch: 3. Train_acc: 69.2%, Train_loss: 0.795, Test_acc:69.9%, Test_loss:0.845, Lr: 1.00E-04
Epoch: 4. Train_acc: 72.3%, Train_loss: 0.702, Test_acc:69.0%, Test_loss:1.069, Lr: 1.00E-04
Epoch: 5. Train_acc: 78.3%, Train_loss: 0.585, Test_acc:82.3%, Test_loss:0.656, Lr: 1.00E-04
Epoch: 6. Train_acc: 82.5%, Train_loss: 0.474, Test_acc:79.6%, Test_loss:0.602, Lr: 1.00E-04
Epoch: 7. Train_acc: 83.6%, Train_loss: 0.458, Test_acc:83.2%, Test_loss:0.699, Lr: 1.00E-04
Epoch: 8. Train_acc: 86.9%, Train_loss: 0.368, Test_acc:85.8%, Test_loss:0.577, Lr: 1.00E-04
Epoch: 9. Train_acc: 88.5%, Train_loss: 0.371, Test_acc:78.8%, Test_loss:0.574, Lr: 1.00E-04
Epoch: 10. Train_acc: 87.6%, Train_loss: 0.345, Test_acc:87.6%, Test_loss:0.392, Lr: 1.00E-04
Epoch: 11. Train_acc: 91.6%, Train_loss: 0.247, Test_acc:80.5%, Test_loss:0.443, Lr: 1.00E-04
Epoch: 12. Train_acc: 91.2%, Train_loss: 0.310, Test_acc:86.7%, Test_loss:0.361, Lr: 1.00E-04
Epoch: 13. Train_acc: 93.6%, Train_loss: 0.201, Test_acc:87.6%, Test_loss:0.336, Lr: 1.00E-04
Epoch: 14. Train_acc: 89.2%, Train_loss: 0.322, Test_acc:84.1%, Test_loss:0.438, Lr: 1.00E-04
Epoch: 15. Train_acc: 91.8%, Train_loss: 0.226, Test_acc:88.5%, Test_loss:0.343, Lr: 1.00E-04
Epoch: 16. Train_acc: 94.5%, Train_loss: 0.146, Test_acc:87.6%, Test_loss:0.321, Lr: 1.00E-04
Epoch: 17. Train_acc: 96.7%, Train_loss: 0.127, Test_acc:88.5%, Test_loss:0.436, Lr: 1.00E-04
Epoch: 18. Train_acc: 96.5%, Train_loss: 0.096, Test_acc:92.0%, Test_loss:0.241, Lr: 1.00E-04
Epoch: 19. Train_acc: 97.1%, Train_loss: 0.094, Test_acc:86.7%, Test_loss:0.430, Lr: 1.00E-04
Epoch: 20. Train_acc: 95.8%, Train_loss: 0.134, Test_acc:59.3%, Test_loss:2.130, Lr: 1.00E-04
Epoch: 21. Train_acc: 95.1%, Train_loss: 0.125, Test_acc:92.9%, Test_loss:0.230, Lr: 1.00E-04
Epoch: 22. Train_acc: 95.4%, Train_loss: 0.144, Test_acc:87.6%, Test_loss:0.402, Lr: 1.00E-04
Epoch: 23. Train_acc: 97.1%, Train_loss: 0.081, Test_acc:91.2%, Test_loss:0.282, Lr: 1.00E-04
Epoch: 24. Train_acc: 98.5%, Train_loss: 0.049, Test_acc:92.9%, Test_loss:0.280, Lr: 1.00E-04
Epoch: 25. Train_acc: 98.5%, Train_loss: 0.054, Test_acc:88.5%, Test_loss:0.413, Lr: 1.00E-04
Epoch: 26. Train_acc: 97.8%, Train_loss: 0.072, Test_acc:87.6%, Test_loss:0.330, Lr: 1.00E-04
Epoch: 27. Train_acc: 98.9%, Train_loss: 0.045, Test_acc:91.2%, Test_loss:0.244, Lr: 1.00E-04
Epoch: 28. Train_acc: 94.9%, Train_loss: 0.156, Test_acc:77.0%, Test_loss:0.813, Lr: 1.00E-04
Epoch: 29. Train_acc: 95.8%, Train_loss: 0.149, Test_acc:91.2%, Test_loss:0.372, Lr: 1.00E-04
Epoch: 30. Train_acc: 97.8%, Train_loss: 0.068, Test_acc:89.4%, Test_loss:0.281, Lr: 1.00E-04
Epoch: 31. Train_acc: 98.5%, Train_loss: 0.030, Test_acc:83.2%, Test_loss:0.529, Lr: 1.00E-04
Epoch: 32. Train_acc: 98.5%, Train_loss: 0.054, Test_acc:91.2%, Test_loss:0.304, Lr: 1.00E-04
Epoch: 33. Train_acc: 98.7%, Train_loss: 0.048, Test_acc:91.2%, Test_loss:0.311, Lr: 1.00E-04
Epoch: 34. Train_acc: 94.2%, Train_loss: 0.179, Test_acc:93.8%, Test_loss:0.244, Lr: 1.00E-04
Epoch: 35. Train_acc: 95.8%, Train_loss: 0.119, Test_acc:87.6%, Test_loss:0.426, Lr: 1.00E-04
Epoch: 36. Train_acc: 98.2%, Train_loss: 0.064, Test_acc:88.5%, Test_loss:0.341, Lr: 1.00E-04
Epoch: 37. Train_acc: 98.9%, Train_loss: 0.047, Test_acc:92.9%, Test_loss:0.223, Lr: 1.00E-04
Epoch: 38. Train_acc: 98.9%, Train_loss: 0.038, Test_acc:87.6%, Test_loss:0.307, Lr: 1.00E-04
Epoch: 39. Train_acc: 98.9%, Train_loss: 0.035, Test_acc:92.9%, Test_loss:0.188, Lr: 1.00E-04
Epoch: 40. Train_acc: 99.3%, Train_loss: 0.025, Test_acc:93.8%, Test_loss:0.159, Lr: 1.00E-04
Done
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 100
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()

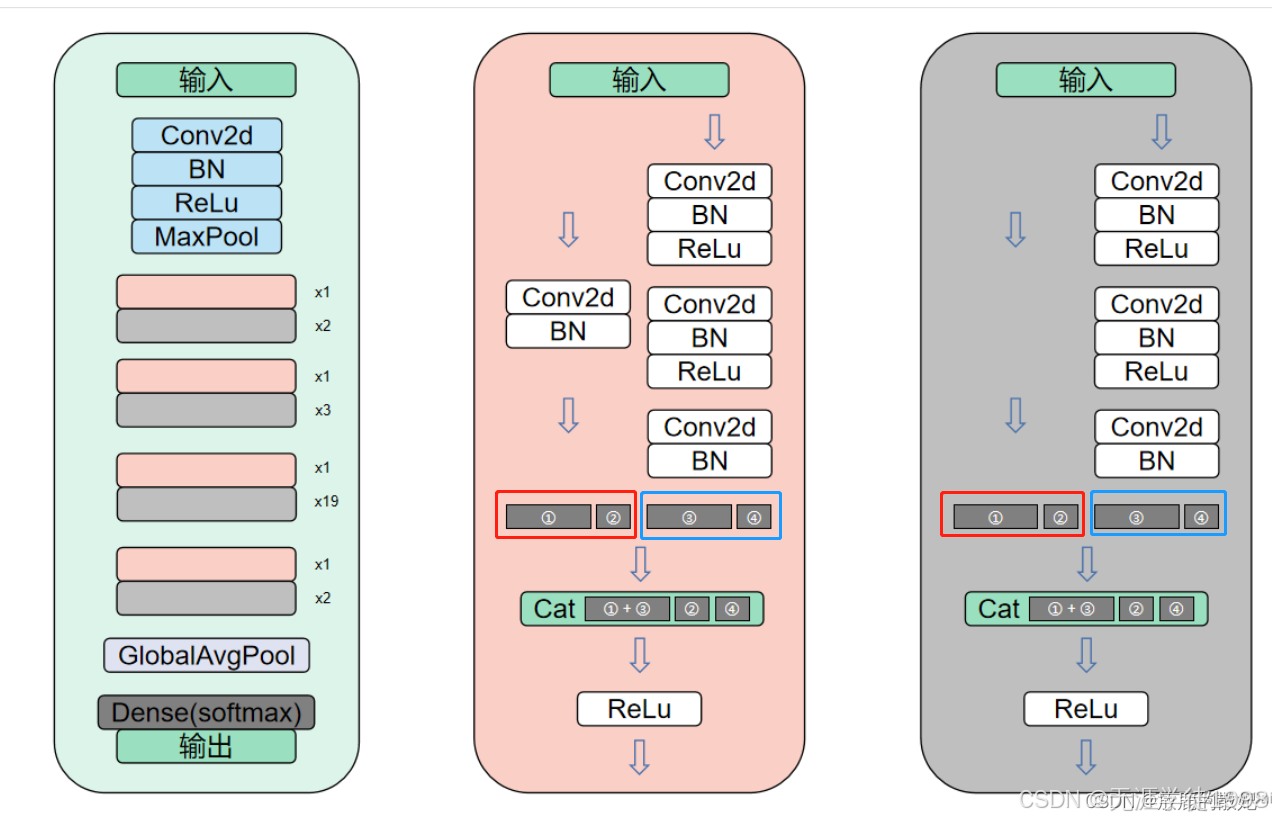
个人总结
- 学习了ResNet与DenseNet结合网络->DPN网络
- DPN网络的核心是双路径块(Dual Path Block),其结构如下:
- 输入:输入特征图被分为两部分。
- 分组卷积:一部分特征图通过分组卷积进行处理,类似于ResNeXt中的操作。
- 密集连接:另一部分特征图通过密集连接进行处理,类似于DenseNet中的操作。
- 特征融合:两部分特征图通过特定的融合方式(如相加或拼接)进行融合,形成最终的输出特征图。





















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









