




本篇文章先介绍一部分设计模式,后续还会逐渐增加!
一、介绍
要了解设计模式,首先必须知道的是设计模式的准则,如果囊括上合成复用原则,那主要包括以下准则:
- 开闭原则:一个软件实体,如类、模块和函数,应该对修改关闭,对扩展开放。
- 单一职责原则:一个类只做一件事,一个类应该只有一个引起它修改的原因。
- 里氏替换原则:子类应该可以完全替换父类。即子类可以出现在父类能够出现的任何地方。也就是说在使用继承时,只扩展新功能,不破坏父类原有的功能。
- 依赖倒置原则:细节应该依赖于抽象,而抽象不应该依赖于细节。把抽象层放在程序设计的高层,并保持稳定,程序的细节变化由低层的实现层完成。
- 迪米特法则(“最少知道法则”):一个类不应知道自己操作的类的细节。
- 接口隔离原则:客户端不应该依赖它不需要的接口。如果一个接口在实现时,部分方法由于冗余被客户端空实现,则应该讲接口拆分,让实现类只需依赖自己需要的接口方法。
- 合成复用原则:尽量使用合成,而不是通过继承达到复用的目的。
根据设计模式公认参考书中所提到的内容,一共包括23种设计模式。并且可以将所有设计模式分成三个大类;创建型模式、结构型模式、行为型模式。当然,随着近些年的不断发展,又出现了一个J2EE模式的大类,本片文章就不做阐述了。
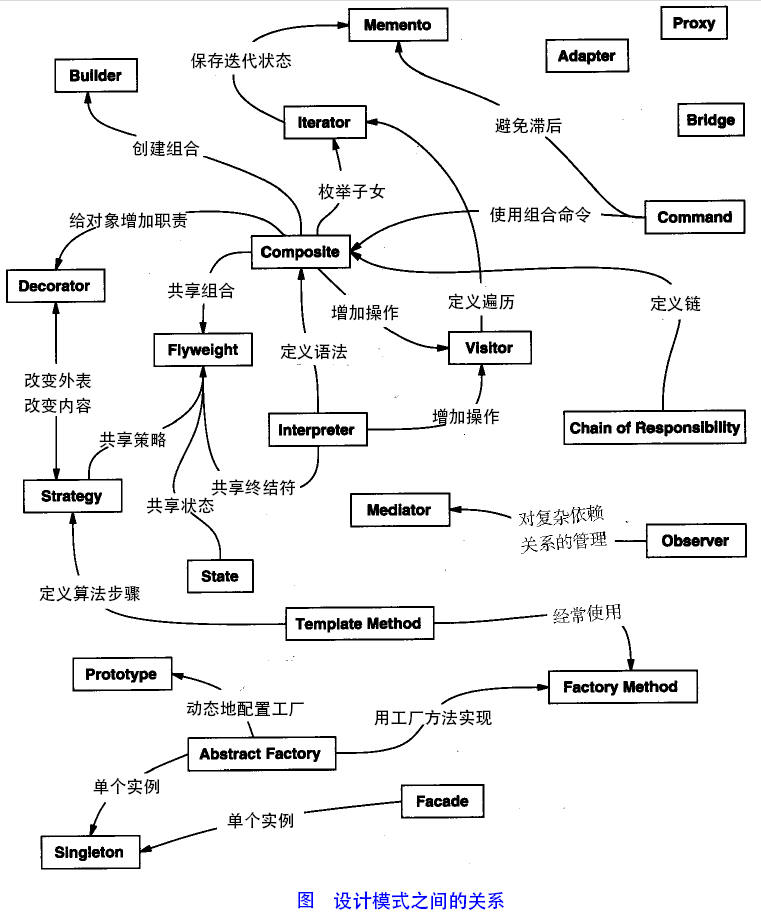
注:参考书中的一张设计模式关系图很有意思,值得思考:
二、创建型模式
2.1 单例模式
2.1.1 介绍
首先来说一下最基础的单例模式。单例模式是用的最多的,其提供了一种创建对象的最佳方式。单例模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建。其特点包括:
- 单例类只能有一个实例;
- 单例类必须自己创建自己的唯一实例;
- 单例类必须给所有其他对象提供这一实例。
使用场景:
- 要求生产唯一序列号;
- web计数器,不用每次刷新都更新数据库;
- 创建一个对象需要消耗的资源过多,比如I/O与数据库的连接等。
2.1.2 实现方式
单例模式的实现方式主要包括懒汉式、饿汉式、双重校验锁以及静态内部类方式。
(一)饿汉式
首先来说一下饿汉式。饿汉式通过变量在声明时进行初始化。此时,将构造方法定义为private,就保证了其他类无法实例化此类,必须通过固定方法来获取到该实例。饿汉式的代码实现如下:
public class Singleton {
private static Singleton instance = new Singleton();
private Singleton() {}
public static Singleton getInstance() {
return instance;
}
}
饿汉式的问题也很明显,就是不管需不需要该类的实例,类加载时就进行初始化,很浪费内存,并且比较容易产生垃圾对象。
(二)懒汉式
为了解决饿汉式的弊端,将实例进行按需加载,进而避免内存浪费和减少初始化时间,可以使用懒汉式来实现单例模式。该方式先声明一个空变量,在对外暴露的方法中,需要用到该类的实例才进行初始化。其代码如下所示:
public class Singleton {
private static Singleton instance = null;
private Singleton() {}
public static Singleton getInstance(){
if (instance == null) {
instance = new Singleton(); }
return instance;
}
}
懒汉式实现单例模式是最基本的实现方式。该方式因为没有加synchronized,所以其最大的问题也暴露出来——不支持多线程,有线程安全问题。所以该方式不能严格保证示例的唯一性,所以严格意义上不能算是单例模式。
(三)双重校验锁
为了解决懒汉式的线程安全问题,保证多个线程调用getInstance()时,以此最多只有一个线程能实例化,可以使用synchronized同步化方法。但是这种方式每次都要加锁,严重影响程序的执行效率。更优的做法是在同步化之前,在加一步判空校验。代码如下:
public class Singleton {
private static volatile Singleton instance = null;
private Singleton() {}
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
以上代码中在线程安全方面,除了使用synchronized,还用了volatile,其作用就是禁止指令重排序。使用volatile的具体场景为:①为Singleton分配内存空间;②初始化;③将Singleton指向分配的内存地址。而使用volatile就是为了防止该过程执行顺序变为①->③->②,此时进行校验锁检查时,还未进行初始化,变量不为null且没完成初始化,从而发生空指针异常。
(四)静态内部类
除了双重校验锁之外,还有一种常见的保证懒汉式单例线程安全的静态内部类方式。代码如下:
public class Singleton {
private static class SingletonHolder {
public static Singleton instance = new Singleton();
}
private Singleton() {}
public static Singleton getInstance() {
return SingletonHolder.instance;
}
}
静态内部类方式有两个关键问题需要进行解读:一个是该方式如何保证线程安全的;另一个就是如何实现懒加载的。
首先的问题就是线程安全。虚拟机在加载类的clinit方法时,会保证clinit在多线程中被正确加锁、同步,也就是说只能有一个线程可以执行clinit方法,从而保证了线程安全。
再有就是懒加载问题。clinit方法是Java的初始化阶段(加载->验证->准备->解析->初始化),由编译器自动收集类中的所有类变量(静态成员变量)的赋值动作和静态程序块中的语句合并产生的。而静态内部类不会立即执行,只有在使用时才会被加载,这就避免了像饿汉式一样浪费内存,实现懒加载机制。
2.2 简单工厂模式
2.2.1 介绍
首先来对工厂模式进行一个整体的介绍。工厂模式提供了一种创建对象的最佳方式。在工厂模式中,我们在创建对象时不会对客户端暴露创建逻辑,并且是通过使用一个共同的接口来指向新创建的对象。在平时的编程中,构建对象最常用的方式是new一个对象。这种最简单的方式属于一种硬编码。每new一个对象,都相当于调用者知道了一个类,增加了类与类之间的联系,会增加程序的耦合度。而工厂模式就是将构建过程封装起来,用于封装对象的设计模式。
2.2.2 代码实例
首先来设定一个实际场景——电脑硬件工厂。当我们需要生产一个CPU时,就要知道CPU的构造方法。当我们需要一个显卡时,就要知道显卡的构造方法。那么更好的实现就是实现一个电脑硬件工厂,调用者来告知工厂需要什么类型的硬件,然后工厂来将对应的硬件制造出来就可以了。这样,调用者就只需要和工厂打交道,而不需要知道各种硬件的实际生产细节。
各种硬件和显卡工厂:
// 硬件接口
public interface Hardware {
public void createStatement();
}
// 中央处理器
public class Cpu implements Hardware {
@Override
public void createStatement(){
System.out.println("中央处理器已生产!");
}
}
// 显卡
public class GraphicsCard implements Hardware {
@Override
public void createStatement(){
System.out.println("显卡已生产!");
}
}
// 硬件工厂
public class HardwareFactory {
public Hardware create(String type){
switch (type){
case "显卡": return new GraphicsCard();
case "中央处理器": return new Cpu();
default: throw new IllegalArgumentException("工厂不能生产此种硬件");
}
}
}
调用者:
public class User {
private static void order(){
HardwareFactory hardwareFactory = new HardwareFactory();
Hardware cpu = hardwareFactory.create("中央处理器");
Hardware graphicsCard = hardwareFactory.create("显卡");
cpu.createStatement();
graphicsCard.createStatement();
}
public static void main(String[] args) {
order();
}
}
因为每种产品的生产方式都是与众不同的,但是也有相同的部分。例如生产显卡和CPU都需要电容、电阻等,这部分过程可以进行代码提取、复用,而每种硬件的核心都不同,可以在工厂中进行修改。对调用者来说,代码不需要任何变化,并且其不需要关心每种硬件的细节,以及为硬件进行芯片生产、储备的过程。生产过程再复杂,那也是工厂的事。
2.2.3 总结
简单工厂模式就是让工厂类承担构建所有对象的职责。调用者需要生产什么产品,只需要告知工厂,所有细节都由工厂承担。这种方式有明显的弊端:
- ①如果需要生产的产品过多,会导致工厂类越来越庞大,承担过多的职责,编程超级类;
- ②要生产新产品时,都要在工厂类中添加新的分支,这就违反了设计模式的开闭原则。我们更希望的是在添加新功能时,只需要增加新的类,而不是修改现有的类。
2.3 工厂方法模式
2.3.1 介绍
工厂方法模式是承接简单工厂模式,为了解决简单工厂模式的两个弊端而产生的。它让每个产品都有一个专属工厂。例如,显卡有专门生产显卡的工厂,CPU有生产CPU的工厂。
2.3.2 代码示例
// 硬件接口
public interface Hardware {
public void createStatement();
}
// CPU
public class Cpu implements Hardware {
@Override
public void createStatement(){
System.out.println("中央处理器已生产!");
}
}
// 显卡
public class GraphicsCard implements Hardware {
@Override
public void createStatement(){
System.out.println("显卡已生产!");
}
}
// CPU工厂
public class CpuFactory{
public Hardware create(){
return new Cpu();
}
}
// 显卡工厂
public class GraphicsCardFactory {
public Hardware create(){
return new GraphicsCard();
}
}
// 调用者
public class User {
private static void order(){
CpuFactory cpuFactory = new CpuFactory();
Hardware cpu = cpuFactory.create();
GraphicsCardFactory graphicsCardFactory = new GraphicsCardFactory();
Hardware graphicsCard = graphicsCardFactory.create();
cpu.createStatement();
graphicsCard.createStatement();
}
public static void main(String[] args) {
order();
}
}
很多人在这里会有疑问,这种创建专用工厂的方式和直接new出实际产品实例有什么区别?
确实,使用工厂方法模式,调用者不需要和实际的Cpu类以及GraphicsCard类打交道,但是需要和CpuFactory、GraphicsCardFactory打交道,增加了代码量。但是这种方式也不是没有用处,增加的中间层——专用工厂可以封装一系列的构建过程。这个构建过程可能非常复杂,调用者还无需知道实际的产品生产细节。每次修改生产过程直接修改专用工厂类即可,不需要修改调用端。并且,工厂方法模式有效地解决了简单工厂模式的两个弊端:
- 工厂类不会变成超级类,只需要管某种产品的生产细节即可,符合单一职责原则;
- 当需要生产新的产品,只需要添加新的工厂,不需要修改原有内容,符合开闭原则。
2.4 抽象工厂模式
2.4.1 介绍
上一节说到了工厂方法模式。该模式确实提升了代码量。那如何对代码进行进一步的提炼也是关键。就可以使用抽象工厂模式。
2.4.2 代码实例
对工厂方法模式可以提取出公共的工厂接口,然后让其他工厂都实现该接口,从而提取出公共的工厂方法:
// 公共工厂接口
public interface IFactory {
Hardware create();
}
// Cpu工厂(显卡工厂同理)
public class CpuFactory implements IFactory{
@Override
public Hardware create(){
return new Cpu();
}
}
对调用者来说,也就顺势将所有具体工厂直接换为提取的公共工厂,从而减少每次代码的修改量。当调用者创建工厂实例时,不需要关心哪个工厂类,只需要将工厂当做抽象的IFactory接口即可。之后,客户端只需要和IFactory打交道,调用的就是接口中的方法,根本不需要知道是在哪个工厂进行的实现,替换工厂更加方便。
public class User {
private static void order(){
IFactory cpuFactory = new CpuFactory();
Hardware cpu = cpuFactory.create();
IFactory graphicsCardFactory = new GraphicsCardFactory();
Hardware graphicsCard = graphicsCardFactory.create();
cpu.createStatement();
graphicsCard.createStatement();
}
public static void main(String[] args) {
order();
}
}
2.4.3 总结
抽象工厂模式很好地发挥了开闭原则和依赖倒置原则。抽象工厂模式的优点很明显,就是如果调用者要修改工厂,那只需要修改调用端的极少量代码即可。但是,有一个很大的缺点,就是如果IFactory需要新增功能,那就需要修改全部的具体工厂类。
所以,抽象工厂模式适用于增加同类工厂这种有横向扩展需求的场景,不适合新增功能这种纵向扩展需求。
2.5 建造者模式
2.5.1 介绍
在《设计模式》中,对建造者模式的定义是:将一个复杂的构建与其表示相分离,使得同样的构建过程可以创建不同的表示。构建者模式主要用于创建过程稳定,但是配置多变的对象。例如,要点一杯奶茶,其每次的制作过程都是相同的,不同的地方就在于是否加糖、是否加冰等。
2.5.2 代码实例
首先是建造类:
public class TeaBuilder {
private boolean ice;
private boolean suger;
private TeaBuilder(Builder builder) {
this.ice = builder.ice;
this.suger = builder.suger;
}
public boolean isIce() {
return ice;
}
public boolean isSuger() {
return suger;
}
public static class Builder{
private boolean ice = false;
private boolean suger = false;
public Builder incIce(boolean cold){
this.ice = cold;
return this;
}
public Builder incSuger(boolean suger){
this.suger = suger;
return this;
}
public TeaBuilder build(){
return new TeaBuilder(this);
}
}
}
建造类的代码有几个细节要注意:
- ①整个建造类TeaBuilder的构造方法是私有的,为了防止外部通过new构建出实例,让所有的实例创建都通过内部类Builder来构建。
- ②内部类的属性要定义默认值,正如去奶茶店点奶茶如果没有任何要求就是需要有一个默认配置,而建造者模式在Builder的默认值定义就是为了进行默认配置,这些属性作为可选属性可以通过Builder的链式调用方法传入。
调用类代码:
public class User {
private static void show(TeaBuilder tea){
System.out.println("加冰:"+ tea.isIce() + "... 加糖:" + tea.isSuger());
}
public static void main(String[] args) {
TeaBuilder teaBuilder = new TeaBuilder.Builder().incIce(true).incSuger(false).build();
show(teaBuilder);
}
}
2.6 原型模式
2.6.1 介绍
原型系统的定义是:用原型系统指定创建对象的种类,并且通过拷贝这些原型创建新的对象。也就是用于创建重复的对象,同时又能保证性能。实际上在Java中,Object的clone()方法就是属于原型模式。
原型系统的作用就是为了创建一个原型,让之后的新对象可以以这个原型为基础,不需要再对该类的各种属性进行重新配置,直接调用clone进行克隆即可。
2.6.2 代码实例
所谓实例复制,不是直接浅拷贝,那不会创建出来新的原型。可以通过重写clone方法,来实现原型模式。但这只是基础使用。Java有个语法糖,可以让原型模型可以通过将一个原型对象传给那个要发动创建的对象,这个要发动创建的对象通过请求对象拷贝它们自己,即通过clone()方法,来创建新对象。
public class Student implements Cloneable {
public String name;
public int age;
@Override
protected Object clone() throws CloneNotSupportedException {
return (Student)super.clone();
}
}
这种方式有一定问题,就是Java自带的clone方法是浅拷贝的。调用它只会拷贝基本类型的参数,而非基本类型的对象不会被拷贝一份,而是继续使用传递引用的方式。当然,如果要一劳永逸,还是需要增加代码量,实现深拷贝。下面附上深拷贝的几种实现方式:
1、手动重写clone方法
手动在clone方法中进行各种类型的属性赋值。
2、序列化方法
可以使用序列化和反序列化重新建立一个对象。
/**
* JDK序列化方式深拷贝
*/
public static <T> T deepClone(T origin) throws IOException, ClassNotFoundException {
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
try (ObjectOutputStream objectOutputStream = new ObjectOutputStream(outputStream
objectOutputStream.writeObject(origin);
objectOutputStream.flush();
}
byte[] bytes = outputStream.toByteArray();
try (ByteArrayInputStream inputStream = new ByteArrayInputStream(bytes);) {
return JdkSerialUtil.readObject(inputStream);
}
}
可以使用序列化工具类 commons-lang3 进行深拷贝。
// 使用方法
Order cloneOrder = SerializationUtils.clone(order);
也可以使用JSON序列化,该方式性能比Java序列化更高
public static <T> T deepCloneByGson(T origin, Class<T> clazz) {
Gson gson = new Gson();
return gson.fromJson(gson.toJson(origin), clazz);
}
2.7 创建型设计模式总结
- 单例模式:全局使用同一个对象,分为饿汉式和懒汉式。懒汉式还有双重校验锁和静态内部类两种实现方式。
- 工厂方法模式:为每一类对象建立工厂,将对象交由工厂创建,客户端只和工厂打交道。
- 抽象工厂模式:为每一类工厂提取出抽象接口,使得新增工厂、替换工厂变得非常容易。
- 建造者模式:用于创建构造过程稳定的对象,不同的 Builder 可以定义不同的配置。
- 原型模式:为一个类定义 clone 方法,使得创建相同的对象更方便。
三、结构型模式
3.1 适配器模式
3.1.1 介绍
适配器模式:将一个类的接口转换成客户希望的另一个接口,使得原本由于接口不兼容而不能一起工作的类可以一起工作。
说到适配器模式的应用,日常最熟悉的就是各种电子设备的充电器。每种充电器都可以将家用220V电压转化为各种电子设备适配的电压。适配器的作用就是适应和匹配。简单来说,适配器模式适用于有相关性但是不兼容的结构。源接口通过适配器的转换后才能适用于目标接口。
3.1.2 代码实例
就以上面充电器的例子来进行实现。首先是家用电源220V:
public class HomeBattery {
public int supply(){
return 220;
}
}
然后是我们的电子设备充电器:
public class USBLine {
public void charge(int volt){
if (volt != 5) throw new IllegalArgumentException("电压不是5V!");
System.out.println("充电开始");
}
}
如果直接将家用电源带入电子设备充电器中,会报错!需要再增加电源适配器:
public class Adapter {
public int convert(int homeVolt){
return homeVolt-215;
}
}
电源适配器将电压降低为5V之后再传给电子设备,最后的调用类为:
public class User {
public static void main(String[] args) {
HomeBattery homeBattery = new HomeBattery();
Adapter adapter = new Adapter();
USBLine usbLine = new USBLine();
usbLine.charge(adapter.convert(homeBattery.supply()));
}
}
四、行为型模式
4.1 责任链模式
4.1.1 介绍
责任链模式是为请求创建了一条链,然后将到来的请求,对请求的发送者和接受者进行解耦,每个接受者都包含对另一个接受者的引用。如果一个对象不能处理该请求,那就将请求传给下一个接受者。
责任链模式最大的误区就是必须是处在同一岗位上的职责,因为每个人的处理能力的不同而组成链,而不是每个人的责任不同的情况。举一个工厂流水线的例子来说,有的工人焊接,有的工人组装,有的工人测试。虽然每个板子都需要全部的工人参与,分步制作。但是组合起来并不是责任链模式的适用情况。应该是单独一步,拿焊接来说,有的新工人焊接技术弱,有的老工人焊接技术强。那来板子之后,先给新工人焊接,当工艺太复杂,新工人无法完成时,再给老工人完成。这就形成了责任链。
4.1.2 代码实例
就拿上节中的工厂流水线例子进行实现。首先列举三个工人,根据编号,业务能力逐渐增强:
// 第一个工人,业务能力最弱
public class OneWorker extends Programmer{
@Override
public void handle(Work work) {
if (work.value > 0 && work.value <= 10){
solve(work);
} else if (next != null){
next.handle(work);
}
}
private void solve(Work work){
System.out.println("第一个工人解决了编号" + work.value + "的问题");
}
}
// 第二个工人
public class TwoWorker extends Programmer{
@Override
public void handle(Work work) {
if (work.value >= 0 && work.value <= 20){
solve(work);
} else if (next != null){
next.handle(work);
}
}
private void solve(Work work){
System.out.println("第二个工人解决了编号" + work.value + "的问题");
}
}
// 第三个工人,业务能力最强
public class ThreeWorker extends Programmer{
@Override
public void handle(Work work) {
if (work.value >= 0 && work.value <= 30){
solve(work);
} else if (next != null){
next.handle(work);
}
}
private void solve(Work work){
System.out.println("第三个工人解决了编号" + work.value + "的问题");
}
}
public abstract class Programmer {
protected Programmer next;
public void setNext(Programmer next){
this.next = next;
}
public abstract void handle(Work work);
}
public class Work {
int value;
public Work(int value){
this.value = value;
}
}
上面代码中的next就是用于配置责任链的下个节点的属性。在调用类中,通过提供的方法形成责任链,然后放入难度不同的工作,让责任链上各个工人开始根据自己的能力开始工作。调用类如下:
public class User {
public static void main(String[] args) {
OneWorker oneWorker = new OneWorker();
TwoWorker twoWorker = new TwoWorker();
ThreeWorker threeWorker = new ThreeWorker();
Work work1 = new Work(5);
Work work2 = new Work(15);
Work work3 = new Work(25);
oneWorker.next = twoWorker;
twoWorker.next = threeWorker;
oneWorker.handle(work1);
oneWorker.handle(work2);
oneWorker.handle(work3);
}
}

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









