




 本文详细介绍了MySQL的查询处理步骤,包括查询缓存的废弃、解析器的词法和语法分析、优化器的选择执行路径以及执行器的权限判断和存储引擎交互。分析了查询缓存效率不高的原因,并强调了在优化器阶段对SQL性能的影响。
本文详细介绍了MySQL的查询处理步骤,包括查询缓存的废弃、解析器的词法和语法分析、优化器的选择执行路径以及执行器的权限判断和存储引擎交互。分析了查询缓存效率不高的原因,并强调了在优化器阶段对SQL性能的影响。
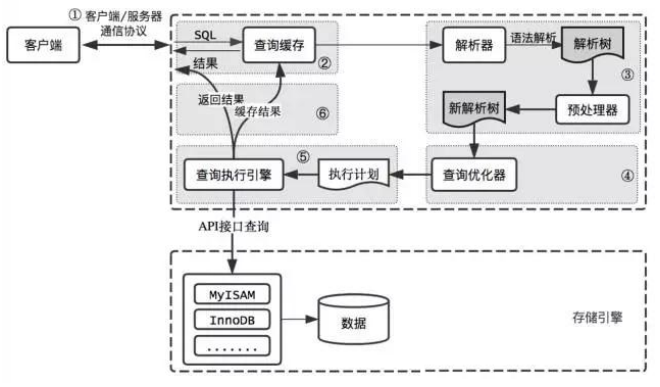
第一步:查询缓存
一、介绍
注意:MySQL8.0之后就抛弃了缓存功能。(因为查询缓存平均效率不高)MySQL8.0之前可通过query_cache_type参数开关查询缓存
当SQL开始执行时,Server会现在查询缓存中查找该SQL语句。之前性质过的语句及其结果会以key-value的形式缓存在内存中。遍历所有key,查找是否有和执行的SQL吻合的,如果查找到,则直接将结果返回给客户端;如果没有,就会进入到解析器阶段,且最终的执行结果会被存入缓存之中。
二、查询缓存效率不高的原因?
1、两个查询请求在任何字符上的不同(例如:空格、注释、 大小写),都会导致缓存不会命中。
2、缓存失效:当缓存系统涉及到的表的结构或数据被修改,那该表的所有高速缓存查询都将变为无效并从高速缓存中删除。此时,对于更新频繁地数据库,缓存不仅仅会频繁失效而命中率不高,还要不断维护缓存列表。
第二步:解析器
作用: 在解析器中对 SQL 语句进行语法分析、语义分析。
一、词法分析:
分析器先做词法分析,MySQL以此识别出SQL语句中的字符串含义。
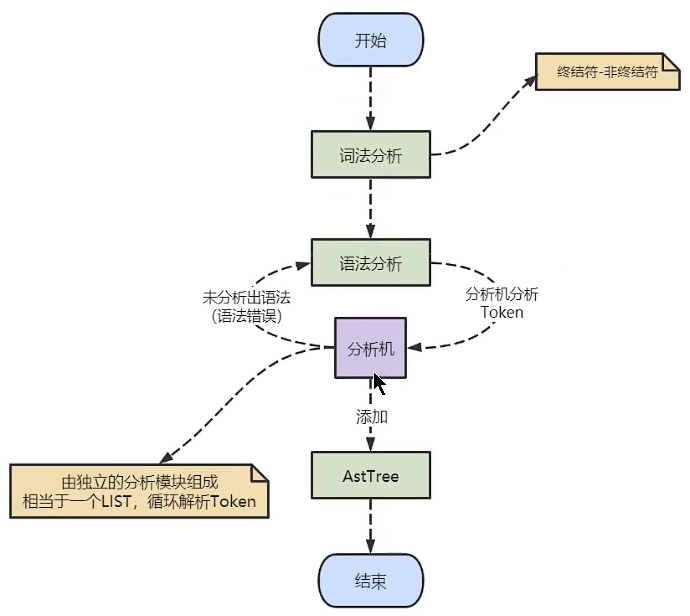
二、语法分析
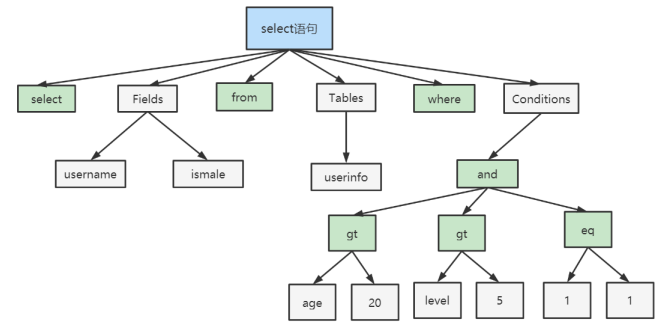
根据词法分析的结果,语法分析器(比如:Bison)会根据语法规则,判断输入的SQL语句是否满足MySQL语法。如果SQL语句正确,会生成语法树;如果不正确,则会进行错误提醒。
第三步:优化器
作用:确定SQL语句的执行路径,比如是根据全表检索,还是根据索引检索等。
总:一条查询语句可以有多种执行方式,最后都返回相同的结果,但是不同的执行方式效率不同。优化器的作用就是可以找到其中最好的执行计划。
对SQL的优化主要也是在这一步,可以进行逻辑优化和物理优化。
第四步:执行器
1、权限判定
- 执行之前需要判断该用户是否具备权限。
- 如果没有,就会返回权限错误。
- 如果有权限,就打开表继续执行。
- 打开表时,执行器会根据表的引擎定义,调用存储引擎的API对表进行读写。
注意:存储引擎API只是抽象接口,具体实现是根据表选择的存储引擎,从而调用下面的存储引擎层。
在 MySQL8.0 以下的版本,如果设置了查询缓存,这时会将查询结果进行缓存。

















 1206
1206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









