






BFS 与 DFS
BFS 刷题
二叉树的最小深度
// 队列存储着当前结点以及当前结点的深度
class Solution {
public:
int minDepth(TreeNode* root) {
if (root == nullptr) return 0;
queue<pair<TreeNode*, int>> q;
q.emplace(root, 1);
while (!q.empty()) {
TreeNode* node = q.front().first;
int depth = q.front().second;
q.pop();
if (!node->left && !node->right) return depth;
if (node->left) q.emplace(node->left, depth + 1);
if (node->right) q.emplace(node->right, depth + 1);
}
return 0;
}
};
// 变量 cc 记录当前层数
class Solution {
public:
int minDepth(TreeNode* root) {
if (root == nullptr) return 0;
queue<TreeNode*> q;
q.push(root);
int cc = 0;
while (!q.empty()) {
int size = q.size();
cc += 1;
for (int i=0; i<size; i++) {
TreeNode* node = q.front(); q.pop();
if (node->right == nullptr && node->left == nullptr)
return cc;
if (node->left) q.push(node->left);
if (node->right) q.push(node->right);
}
}
return cc;
}
};
二叉树的层序遍历
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
if (root == nullptr) return {};
vector<vector<int>> res;
queue<TreeNode*> q;
q.push(root);
while (!q.empty()) {
int num = q.size();
vector<int> temp;
for (int i=0; i<num; i++) {
TreeNode* node = q.front(); q.pop();
temp.push_back(node->val);
if (node->left) q.push(node->left);
if (node->right) q.push(node->right);
}
res.push_back(temp);
}
return res;
}
};
单词接龙

方法一:BFS
- 初始化队列
que和一个哈希表visited中,visited是为了不再重复访问单词。 - 对于刚开始的单词
beginWord = "hit",我们每次只替换一个位置的字符,然后在wordList里查找是否有一样的字符串,若完全没有相同的字符串,相当于beginWord不能转换到endWord;比如将中间的字符 i 替换为 o :- 如果修改后的单词与
endWord相等,则返回对应的最短转换序列; - 如果修改的单词与
endWord不相等,且在wordList数组中找到了对应的单词,以及没有访问过这个单词,则将这个单词放进que里,下一循环就重复这个的过程; - 如果修改的单词与
endWord不相等,且在wordList数组中不存在对应的单词,则que不放入。
- 如果修改后的单词与
- 整体过程可以视为一个很大的树或者图,如上图所示。从
hit节点开始,可以分裂出 26*3 个结点(分支),其中hit也在里面,但是只有hot是在wordList中且没有 visited 过,因此只选择这个单词;后续的流程一样,hot也可以分裂出很多分支,但是能存到队列中就需要看wordList和visited这两个哈希表。
方式二:双向 BFS
- 使用两个队列
startQue和endQue,分别从beginWord和endWord开始。 - 每次循环队列的过程中,选择元素较少的队列开始搜索,以减少搜索空间;较大的队列,不仅作为对立面,也用作较小队列的临时存储。
- 对队列的元素进行访问流程与第一个方式大部分是相同,但有一个点不同:判断最短转换序列的条件是,当两个队列的元素相交时,表示
beginWord可以转换为endWord;具体来说,当在当前队列中找到在另一个队列的集合visitedEnd中存在的单词时,直接返回当前步数 + 1。

// BFS
class Solution {
public:
int ladderLength(string beginWord, string endWord, vector<string>& wordList) {
unordered_set<string> wordlist(wordList.begin(), wordList.end());
if (wordlist.find(endWord) == wordlist.end())
return 0;
int count = 1;
unordered_set<string> visited;
queue<string> que;
que.emplace(beginWord);
visited.insert(beginWord);
int wordSize = beginWord.size();
while (!que.empty()) {
int n = que.size();
// 层序遍历
for (int i=0; i<n; i++) {
string front = que.front(); que.pop();
if (front == endWord) return count;
for (int j=0; j<wordSize; j++) {
string str = front;
for (int k=0; k<26; k++) {
// 替换单个字符
str[j] = 'a' + k;
if (visited.find(str) == visited.end() && wordlist.find(str) != wordlist.end()) {
que.emplace(str);
visited.insert(str);
}
}
}
}
count++;
}
return 0;
}
};
// 双向 BFS
class Solution {
public:
int ladderLength(string beginWord, string endWord, vector<string>& wordList) {
unordered_set<string> wordlist(wordList.begin(), wordList.end());
if (wordlist.find(endWord) == wordlist.end())
return 0;
int count = 1;
queue<string> beginQue;
queue<string> endQue;
beginQue.emplace(beginWord);
endQue.emplace(endWord);
unordered_set<string> visited;
unordered_set<string> visitedEnd;
visited.insert(beginWord);
visitedEnd.insert(endWord);
int wordSize = beginWord.size();
while (!beginQue.empty() && !endQue.empty()) {
if (beginQue.size() > endQue.size()) {
swap(beginQue, endQue);
swap(visited, visitedEnd);
}
int n = beginQue.size();
// 层序遍历
for (int i=0; i<n; i++) {
string front = beginQue.front(); beginQue.pop();
for (int j=0; j<wordSize; j++) {
string str = front;
for (int k=0; k<26; k++) {
str[j] = 'a' + k;
if (visited.find(str) == visited.end() && wordlist.find(str) != wordlist.end()) {
if (visitedEnd.find(str) != visitedEnd.end())
// 这个 str 存在 visitedEnd 中,相交了
return count+1;
beginQue.emplace(str);
visited.insert(str);
}
}
}
}
count++;
}
return 0;
}
};
BFS in Topological Sort
拓扑排序是对一个有向无环图(Directed Acyclic Graph,DAG)进行排序的算法,目的是将图中的顶点排成一个线性序列。且该序列必须满足下面两个条件:
(1) 每个顶点出现且只出现一次。
(2) 若存在一条从顶点A到顶点B的路径,那么在序列中顶点A出现在顶点 B 的前面。
注: 有向无环图 (DAG) 才有拓扑排序,非 DAG 图没有拓扑排序一说。
课程表
207. 课程表
prerequisites[i] = [ai, bi],表示如果要学习课程 ai 则必须先学习课程 bi ;因此是从 bi 指向 ai。

(1) 根据 prerequisites 数组利用 哈希表 map 构建整个课程图,以及利用 数组 in 存储每个顶点的入度情况;比如 {1:[3, 4]} 表明为顶点 1 同时指向 3 和 4,in[3] = 2 相当于顶点 3 的入度为 2 ;
(2) 利用队列 que,将入度为 0 的点,放到队列中 【当顶点的入度为 0 ,相当于对应的课程已经学习完了,若仍有些课程的入度不为 0,说明图中存在环,无法被选,完成不了所有课】;
(3) 从队列中得到入度为 0 的顶点,假设将这个顶点去掉,则对应的被指向的顶点的入度应被减一;若是入度被减为 0 ,则将这个被指向的顶点放入队列中。
class Solution {
public:
bool canFinish(int numCourses, vector<vector<int>>& prerequisites) {
unordered_map<int, vector<int>> map;
vector<int> in(numCourses, 0);
for (int i=0; i<prerequisites.size(); i++) {
map[prerequisites[i][1]].push_back({prerequisites[i][0]});
in[prerequisites[i][0]]++;
}
queue<int> que;
for (int i=0; i<in.size(); i++) {
if (in[i] == 0) que.push(i);
}
int count = 0;
while (!que.empty()) {
int node = que.front(); que.pop();
count++;
for (int i=0; i<map[node].size(); i++) {
if (in[map[node][i]] > 0) {
in[map[node][i]]--;
if (in[map[node][i]] == 0) que.push(map[node][i]);
}
}
}
// 入度为 0 的数量是否等于 numCourses
return count == numCourses;
}
};
课程表 II
class Solution {
public:
vector<int> findOrder(int numCourses, vector<vector<int>>& prerequisites) {
unordered_map<int, vector<int>> map;
vector<int>in(numCourses, 0);
for (int i=0; i<prerequisites.size(); i++) {
map[prerequisites[i][1]].push_back(prerequisites[i][0]);
in[prerequisites[i][0]]++;
}
queue<int> que;
for (int i=0; i<numCourses; i++) {
if (in[i] == 0) que.push(i);
}
vector<int> ans;
while (!que.empty()) {
int node = que.front(); que.pop();
ans.push_back(node);
for (int i=0; i<map[node].size(); i++) {
if (in[map[node][i]] > 0) {
in[map[node][i]]--;
if (in[map[node][i]] == 0) que.push(map[node][i]);
}
}
}
if (ans.size() < numCourses) return {};
return ans;
}
};
DFS 刷题
中序、前序、后序遍历
看这篇文章
力扣刷题 – 树
子集
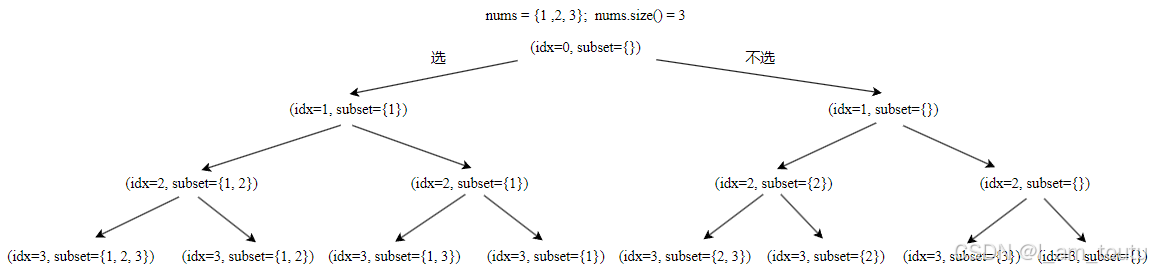
下图是关于 78. 子集 的 dfs 的流程
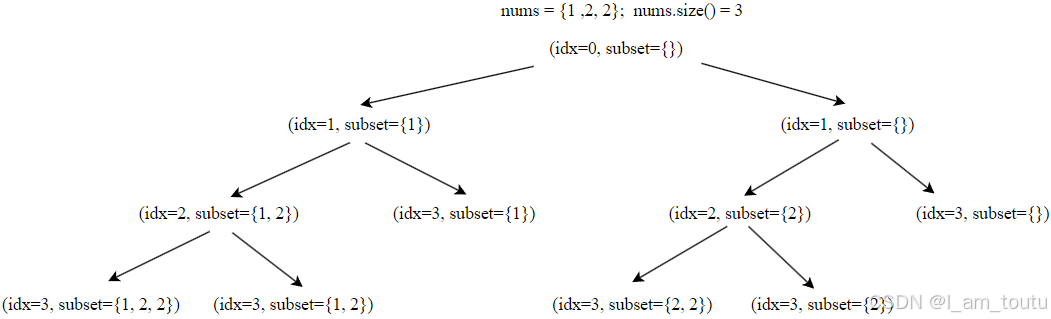
下图是关于 90. 子集 II 的 dfs 的流程。
// 78. 子集
class Solution {
public:
vector<vector<int>> ans;
vector<vector<int>> subsets(vector<int>& nums) {
vector<int> subset;
dfs(nums, 0, subset);
return ans;
}
void dfs(vector<int>& nums, int idx, vector<int> subset) {
if (nums.size() <= idx) {
ans.push_back(subset);
return;
}
dfs(nums, idx+1, subset); // 不选
subset.push_back(nums[idx]); // 选
dfs(nums, idx+1, subset);
subset.pop_back();
}
};
// 90. 子集 II
class Solution {
public:
vector<vector<int>> ans;
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
sort(nums.begin(), nums.end());
vector<int> subset;
dfs(nums, 0, subset);
return ans;
}
void dfs(vector<int>& nums, int idx, vector<int> subset) {
if (nums.size() <= idx) {
ans.push_back(subset);
return;
}
subset.push_back(nums[idx]); // 选
dfs(nums, idx+1, subset);
// 对于图中的示例,当索引为 idx 的元素执行前面两步操作后,
// 再比较 idx 与 idx+1 的元素,若是相等就直接跳过,即为 idx++
while (idx + 1 < nums.size() && nums[idx+1] == nums[idx])
idx++;
subset.pop_back(); // 不选
dfs(nums, idx+1, subset);
}
};
78. 子集 另一种做法
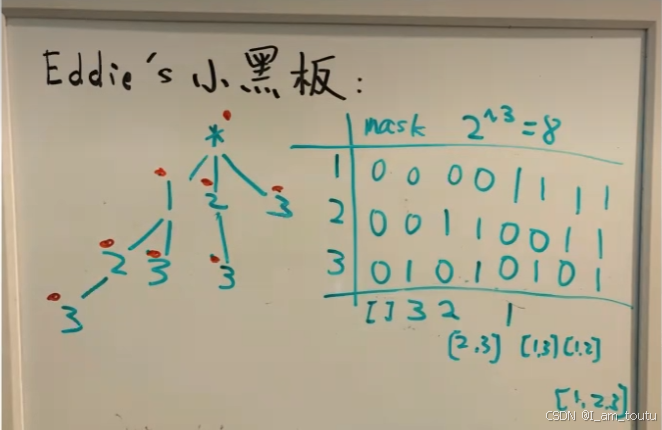
通过按位与操作以及左移操作符生成给定数组的所有子集。
(1) 利用位移操作符 1 << nums.size() 计算所有可能的子集数量,即为 0 到 7,每个数字的二进制表示一个子集;
(2) 循环每一个子集,循环过程中分别于 j=0、j=1 和 j=2 进行按位与操作;若是结果 1,则表示在当前子集中包含 nums[j]。
class Solution {
public:
vector<vector<int>> subsets(vector<int>& nums) {
vector<vector<int>> ans;
int size = 1 << nums.size();
for (int i=0; i<size; i++) {
vector<int> temp;
for (int j=0; j<nums.size(); j++) {
// 1 << 0 ==> 0001;1 << 1 ==> 0010;1 << 2 ==> 0100
// & 按位与操作: 当相应位都为 1 时,结果才为 1
if ((i & (1 << j)) != 0) temp.push_back(nums[j]);
}
ans.push_back(temp);
}
return ans;
}
};
全排列
跟 子集 的关于 dfs 的思路差不多,DFS 用于遍历所有可能的排列组合。
DFS 的每一层代表一个元素的选择。第一层是第一个元素的选择,第二层是第二个元素的选择,以此类推。索引 idx 表示当前层次,也是正在选择第 idx 个位置的元素,通过循环遍历和递归实现深度优先搜索的完整过程。
假设数组
nums = [1, 2, 3],第 idx = 0 层的选择有多种,要么是 1,要么是2,要么是 3;假设我们选择元素 2,则第 idx = 1 层的能选择的就有[1, 3];若选择了元素 3,则在第 idx = 2 层的元素就只剩下元素 1;这样构成了排列组合的其中一个的结果[2, 3, 1]。
class Solution {
public:
vector<vector<int>> ans;
vector<vector<int>> permute(vector<int>& nums) {
dfs(nums, 0);
return ans;
}
void dfs(vector<int> nums, int idx) {
if (nums.size() <= idx) {
ans.push_back(nums);
return;
}
for (int i=idx; i<nums.size(); i++) {
swap(nums[idx], nums[i]); // 交换
dfs(nums, idx+1);
swap(nums[idx], nums[i]);
}
}
};
全排列 II
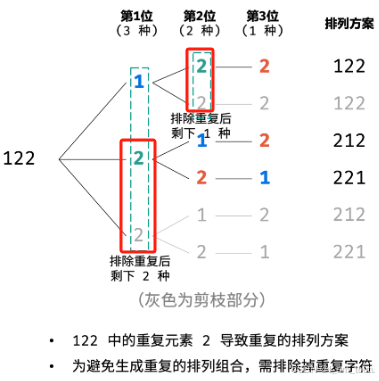
下图中,数组为 nums=[1, 2, 2],那么第一个位置的元素要么是 1,要么是 2,要么是 2;因此存在两次第一个位置都为 2 的情况;
因此,若是第一个安排元素 2,则后续的第一个元素就不能再是 2,就可以避免重复。
只有当第一个 2 被使用了,后续的 2 才能被跳过
相当于在同一层中避免使用相同的元素
// 方式一:
class Solution {
public:
vector<vector<int>> ans;
vector<vector<int>> permuteUnique(vector<int>& nums) {
dfs(nums, 0);
return ans;
}
void dfs(vector<int> nums, int idx) {
if (nums.size() <= idx) {
ans.push_back(nums);
return;
}
set<int> st;
for (int i=idx; i<nums.size(); i++) {
if (st.find(nums[i]) != st.end())
continue; // 存在重复的值
st.insert(nums[i]);
swap(nums[idx], nums[i]);
dfs(nums, idx+1);
swap(nums[idx], nums[i]);
}
}
};
// 方式二:
class Solution {
public:
vector<vector<int>> ans;
vector<vector<int>> permuteUnique(vector<int>& nums) {
sort(nums.begin(), nums.end());
vector<bool> used(nums.size(), false);
vector<int> level;
dfs(nums, level, used);
return ans;
}
void dfs(vector<int>& nums, vector<int> level, vector<bool>& used) {
if (level.size() == nums.size()) {
ans.push_back(level);
return;
}
for (int i=0; i < nums.size(); i++) {
if (used[i]) continue; // 使用过
if (i > 0 && nums[i] == nums[i-1] && !used[i-1]) continue;
used[i] = true;
level.push_back(nums[i]);
dfs(nums, level, used);
level.pop_back();
used[i] = false;
}
}
};
组合
class Solution {
public:
vector<vector<int>> ans;
vector<vector<int>> combine(int n, int k) {
vector<int> level;
dfs(n, k, 1, level);
return ans;
}
void dfs(int n, int k, int idx, vector<int> level) {
if (level.size() == k) {
ans.push_back(level);
return;
}
for (int i=idx; i <= n - (k - level.size()) + 1; i++) {
// n - (k - level.size()) + 1 表示剩余元素是否足够生成一个新的组合
// k - level.size() 表示当前还需要选择的元素数量
level.push_back(i);
dfs(n, k, i+1, level); // 下一层递归的起始点为 idx = i + 1
level.pop_back();
}
}
};

















 1025
1025

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









