



 梯度下降是基于搜索的最优化方法,用于最小化损失函数。介绍了其使用方法,包括对特征系数求导、学习率α的选择等。还阐述了3种常用方法,以及如何用它寻找线性回归最优解、进行向量化处理,最后提及随机梯度下降法。
梯度下降是基于搜索的最优化方法,用于最小化损失函数。介绍了其使用方法,包括对特征系数求导、学习率α的选择等。还阐述了3种常用方法,以及如何用它寻找线性回归最优解、进行向量化处理,最后提及随机梯度下降法。
梯度下降不是一个机器学习算法,他是一个基于搜索的最优化方法,其作用是最小化损失函数。
一、使用方法:
就是对损失函数中特征的系数进行求导,然后再用上一次的
减去求导后的数值

公式的意义:
是关于
的一个函数,我们当前所处的位置是
点,要从这个点走到
的最小值点,首先我们先确定前进的方向,也就是梯度的反方向,然后走一段距离的步长,也就是
,走完这段步长就到了点
1位置
- 对于
的说明
α在梯度下降算法中被称作为学习率或者步长,意味着我们可以通过α来控制每一步走的距离,以保证不要步子跨的太大而跳过了最优解,其实就是不要走太快,错过了最低点。同时也要保证不要走的太慢而耗费太多时间。所以α的选择在梯度下降法中往往是很重要的!α不能太大也不能太小,太小的话,可能导致迟迟走不到最低点,太大的话,会导致错过最低点!
- 梯度前为什么要加一个负号
梯度前加一个负号,就意味着朝着梯度相反的方向前进!梯度的方向实际就是函数在此点上升最快的方向!而我们需要朝着下降最快的方向走,自然就是负的梯度的方向,所以此处需要加上负号
二、3种常用梯度下降的方法

三、用梯度下降法寻找线性回归中最优解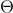

用梯度下降法实现输入数据含有多个特征的线性回归
#!/usr/bin/python
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(666)
x = 2 * np.random.random(size=100)
y = x * 3. + 4. + np.random.normal(size=100)
X = x.reshape(-1,1)
plt.scatter(x,y)
plt.show()
#定义一个损失函数
def J(theta,x_b,y):
try:
return np.sum((y-x_b.dot(theta))**2)/len(x_b)
except:
return float("inf")
#定义一个损失函数对theta求导的函数
def dJ(theta,x_b,y):
#开辟一个空间,大小与theta的长度相同
res = np.empty(len(theta))
res[0] = np.sum(x_b.dot(theta)-y)
for i in range(1,len(theta)):
res[i] = (x_b.dot(theta)-y).dot(x_b[:,i])
return res * 2 / len(x_b)
用梯度下降法求最优,使损失函数最小。
def gradient_descent(x_b,y,initial_theta,eta,epsilon,n_iters=1e4):
theta = initial_theta
i_iter = 0
while i_iter < n_iters:
gradient = dJ(theta,x_b,y)
last_theta = theta
theta = theta - eta * gradient
if (abs(J(last_theta,x_b,y) - J(theta,x_b,y))) < epsilon:
break
i_iter += 1
return theta
x_b = np.hstack([np.ones((len(x),1)),x.reshape(-1,1)])
initial_theta = np.zeros(x_b.shape[1])
eta = 0.01
epsilon = 1e-8
theta = gradient_descent(x_b,y,initial_theta,eta,epsilon)
print(theta)
当数据样本只有一个特征时,线性回归中用梯度下降法求最优解的实现代码
#!/usr/bin/python
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
plot_x = np.linspace(-1,6,141)
#print(plot_x)
plot_y = (plot_x-2.5)**2-1
#plt.plot(plot_x,plot_y)
#plt.show()
#曲线在theta这一点的导数是多少
def dJ(theta):
return 2*(theta-2.5)
#曲线在theta这一点对应的损失函数值是多少
def J(theta):
return (theta-2.5)**2-1
#初始化
theta = 0.0
eta = 0.1
epsilon = 1e-8
theta_history = [theta]
while True:
gradient = dJ(theta)
last_theta = theta
theta = theta - eta * gradient
theta_history.append(theta)
if (abs(J(last_theta)-J(theta))) < epsilon:
break
print(theta)
print(J(theta))
plt.plot(plot_x,J(plot_x))
plt.plot(np.array(theta_history),J(np.array(theta_history)),color = "r",marker = "+")
plt.show()


当theta取2.5时,损失函数最小。
四、线性回归中梯度下降法的向量化
- 如何对梯度下降法的过程进行向量化的处理

向量化后的公式:

def fit_gd(self, X_train, y_train, eta=0.01, n_iters=1e4):
"""根据训练数据集X_train, y_train, 使用梯度下降法训练Linear Regression模型"""
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must be equal to the size of y_train"
def J(theta, X_b, y):
try:
return np.sum((y - X_b.dot(theta)) ** 2) / len(y)
except:
return float('inf')
def dJ(theta, X_b, y):
return X_b.T.dot(X_b.dot(theta) - y) * 2. / len(y)
def gradient_descent(X_b, y, initial_theta, eta, n_iters=1e4, epsilon=1e-8):
theta = initial_theta
cur_iter = 0
while cur_iter < n_iters:
gradient = dJ(theta, X_b, y)
last_theta = theta
theta = theta - eta * gradient
if (abs(J(theta, X_b, y) - J(last_theta, X_b, y)) < epsilon):
break
cur_iter += 1
return theta
X_b = np.hstack([np.ones((len(X_train), 1)), X_train])
initial_theta = np.zeros(X_b.shape[1])
self._theta = gradient_descent(X_b, y_train, initial_theta, eta, n_iters)
self.intercept = self._theta[0]
self.coef = self._theta[1:]
return self
当我们使用梯度下降法搜索损失函数的最小值前对数据需要进行归一化处理,当处理的数据样本量较大时,梯度下降法消耗的时间比正规化方程要少的多,当数据量特别大的时候我们可以使用随机梯度下降法。
五、随机梯度下降法
随机梯度下降法的学习率写成如下形式是为了防止学习率下降太快的情况


















 1078
1078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









