




 本文详细介绍了如何在Vmware上的CentOS7环境下搭建Hadoop-2.7.3全分布集群,包括环境准备、安装配置、集群启动和验证步骤。涉及内容包括配置主机名映射、免密登录、时间同步、环境变量设置、Hadoop配置文件修改、 slaves文件编辑、分发配置到各节点以及NameNode的格式化。最后,通过jps命令和浏览器访问特定端口来验证集群是否正常运行。
本文详细介绍了如何在Vmware上的CentOS7环境下搭建Hadoop-2.7.3全分布集群,包括环境准备、安装配置、集群启动和验证步骤。涉及内容包括配置主机名映射、免密登录、时间同步、环境变量设置、Hadoop配置文件修改、 slaves文件编辑、分发配置到各节点以及NameNode的格式化。最后,通过jps命令和浏览器访问特定端口来验证集群是否正常运行。
Hadoop全分布环境搭建
- 环境
Vmware+centos7+jdk8+hadoop-2.7.3 - 说明
hadoop全分布模式需要三台主机:ethan001,ethan002,ethan003 - 主机分布规划:
主节点:ethan001
从节点:ethan002 ethan003
一、准备工作
1、hadoop安装包,hadoop-2.7.3.tar
提码:1111
2、三台安装好jdk的虚拟机,jdk安装教程
3、所有主机都配置好主机名映射关系
vi /etc/hosts
输入自己三台虚拟机的ip 主机名():
192.168.174.140 ethan001
192.168.174.141 ethan003
192.168.174.142 ethan002
5、保证每台机器的时间是一样的
如果不一样的话,我们在执行MapReduce程序的时候可能会存在问题.。 解决方案:
- 搭建一个时间同步的服务器,网上很多教程可以使用
二、开始安装配置
- 安装和配置环境变量
- 在主机/opt/目录下创建两个目录:soft和module
mkdir /opt/soft /opt/module - 将hadoop安装包上传到主机ethan002上的soft目录下
- 解压安装包到module目录下
tar -zvxf hadoop-2.7.3.tar.gz -C /opt/module/ - 配置环境变量
vi /etc/profile#hadoop export HADOOP_HOME=/opt/module/hadoop-2.7.3 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin - 创建tmp目录
mkdir /opt/module/hadoop-2.7.3/tmp
- 集群配置
-
集群部署规划
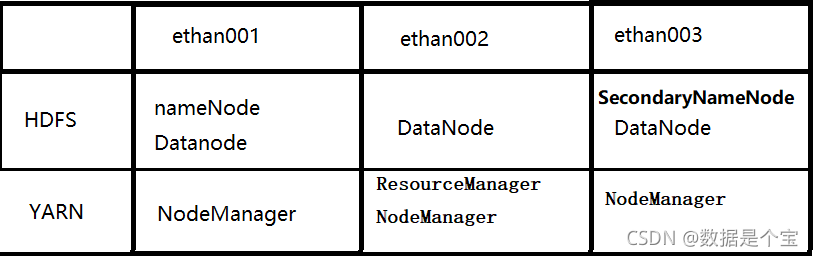
-
规划集群
(1) 修改haoop-env.sh 添加JAVA_HOME
命令:
vi /opt/module/hadoop-2.7.3/etc/hadoop/hadoop-env.sh
添加如下信息:
export JAVA_HOME=/opt/module/jdk1.8.0_171(2) 核心配置文件
配置core-site.xml
vi core-site.xml
在文件中添加如下配置信息:<!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://ethan001:9000</value> </property> <!-- 指定Hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.7.3/data/tmp</value> </property>(3)配置hdfs-site.xml文件
vi hdfs-site.xml
添加如下配置信息:<property> <name>dfs.replication</name> <value>3</value> </property> <!-- 指定Hadoop辅助名称节点主机配置 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>ethan003:50090</value> </property>(4) 配置yarn-site.xml文件
vi yarn-site.xml
添加如下配置信息:<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>ethan002</value> </property> <!-- 日志聚集功能使能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 日志保留时间设置7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> <!-- Site specific YARN configuration properties --> <property> <name>yarn.log.server.url</name> <value>http://ethan002:19888/jobhistory/logs</value> </property> <!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>(5)配置mapred-site.xml文件
vi mapred-site.xml
添加如下配置信息:<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>ethan001:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>ethan001:19888</value> </property> <!--第三方框架使用yarn计算的日志聚集功能 --> <property> <name>yarn.log.server.url</name> <value>http://ethan001:19888/jobhistory/logs</value> </property>(6)配置slaves文件
vi /opt/module/hadoop-2.7.3/etc/hadoop/slaves
添加如下信息(添加的是hadoop集群的DataNode节点的主机名):ethan002 ethan003(7) 将hadoop分发到其他节点
scp -r hadoop-2.7.3 root@ethan001:/opt/module/ scp -r hadoop-2.7.3 root@ethan003:/opt/module/查看分发情况:
cat /opt/module/hadoop-2.7.3/etc/hadoop/core-site.xml
(8)格式化NameNode
hdfs namenode -format
输出的日志中有如下信息则成功
Storage directory /tmp/hadoop-root/dfs/name has been successfully formatted.三、启动hadoop集群
在ethan002上启动hadoop,因为yarn是配置在ethan002上的,只有在ethan002上启动集群时ResourceManager和nodeManager进程才会启动。
启动命令:
start-all.sh四、验证
-
查看进程
jps
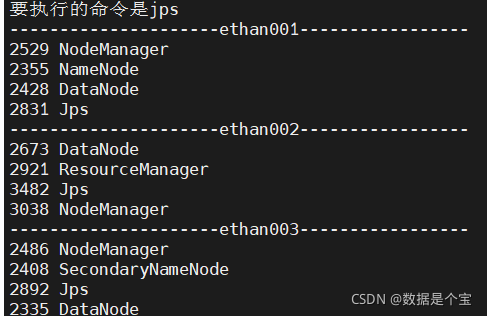
-
浏览网页
hdfs:
http://ethan001:50070

yarn:
http://ethan002:8080

至此,hadoop集群的安装完成,主要的就是一定要先安装jdk
如果您在阅读时发现存在错误,还请您帮忙指出,非常感谢


















 1711
1711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











