 小红书达人价值评估系统
小红书达人价值评估系统








注意:该项目只展示部分功能,如需了解,文末咨询即可。
1 开发环境
发语言:python
采用技术:Spark、Hadoop、Django、Vue、Echarts等技术框架
数据库:MySQL
开发环境:PyCharm
2 系统设计
在数字营销时代,以小红书为代表的内容社交平台已成为品牌方连接年轻消费者的核心阵地,其独特的“种草”文化催生了庞大的达人经济。然而,品牌方面对海量达人时,常面临信息不对称的困境:如何从数以万计的创作者中快速筛选出与品牌调性相符、兼具真实影响力与高性价比的达人?如何科学评估不同领域、不同量级达人的商业价值以制定合理的营销预算?这些问题导致品牌投放决策大多依赖主观经验,缺乏数据支撑,不仅效率低下,且营销风险高。因此,开发一个基于大数据的分析可视化系统具有重要的实践意义。本系统旨在利用大数据技术,对小红书达人数据进行深度清洗、聚合与多维度分析,通过直观的可视化图表,揭示达人生态特征、量化商业价值、剖析内容领域热点,并构建潜力达人挖掘模型,从而为品牌方的营销策略提供科学、精准、高效的数据决策支持。
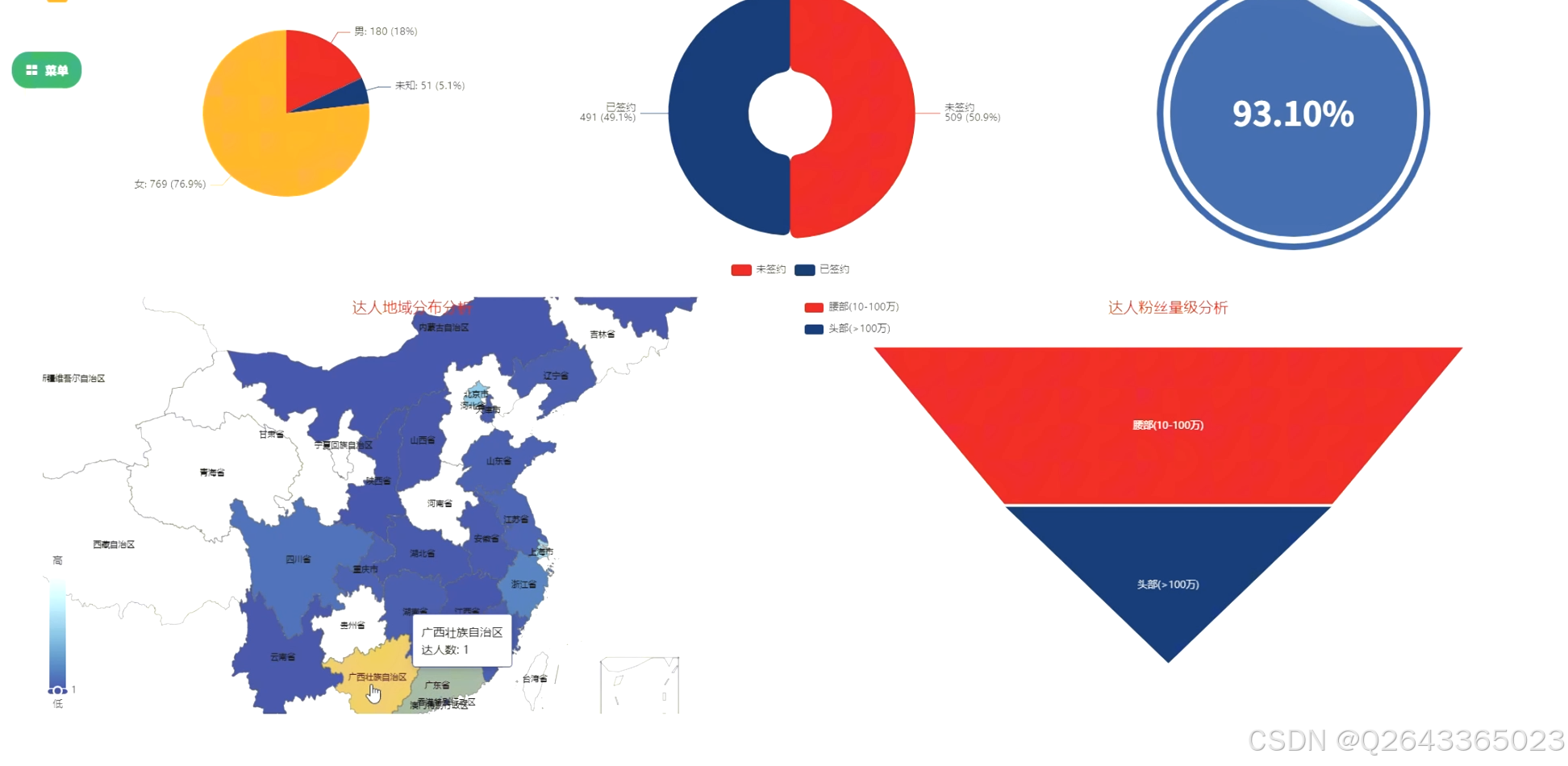
1.达人总体特征分析模块:
此模块旨在描绘达人群体的宏观画像。功能上,将实现对达人性别、地域、粉丝量级、MCN签约情况及品牌合作人身份的统计与可视化展示。研究重点在于地域字段的精确清洗与省份提取,以及粉丝量级的合理划分标准。
2.达人商业价值分析模块:
此模块专注于量化达人的商业潜力。功能上,将从不同维度(粉丝量级、地域)分析达人的平均报价,并探究商业笔记数量、互动数据(赞藏总数)与报价、粉丝量之间的相关性与性价比。研究重点是构建“互动率”和“性价比”等衍生指标,为品牌预算制定和ROI预估提供数据依据。
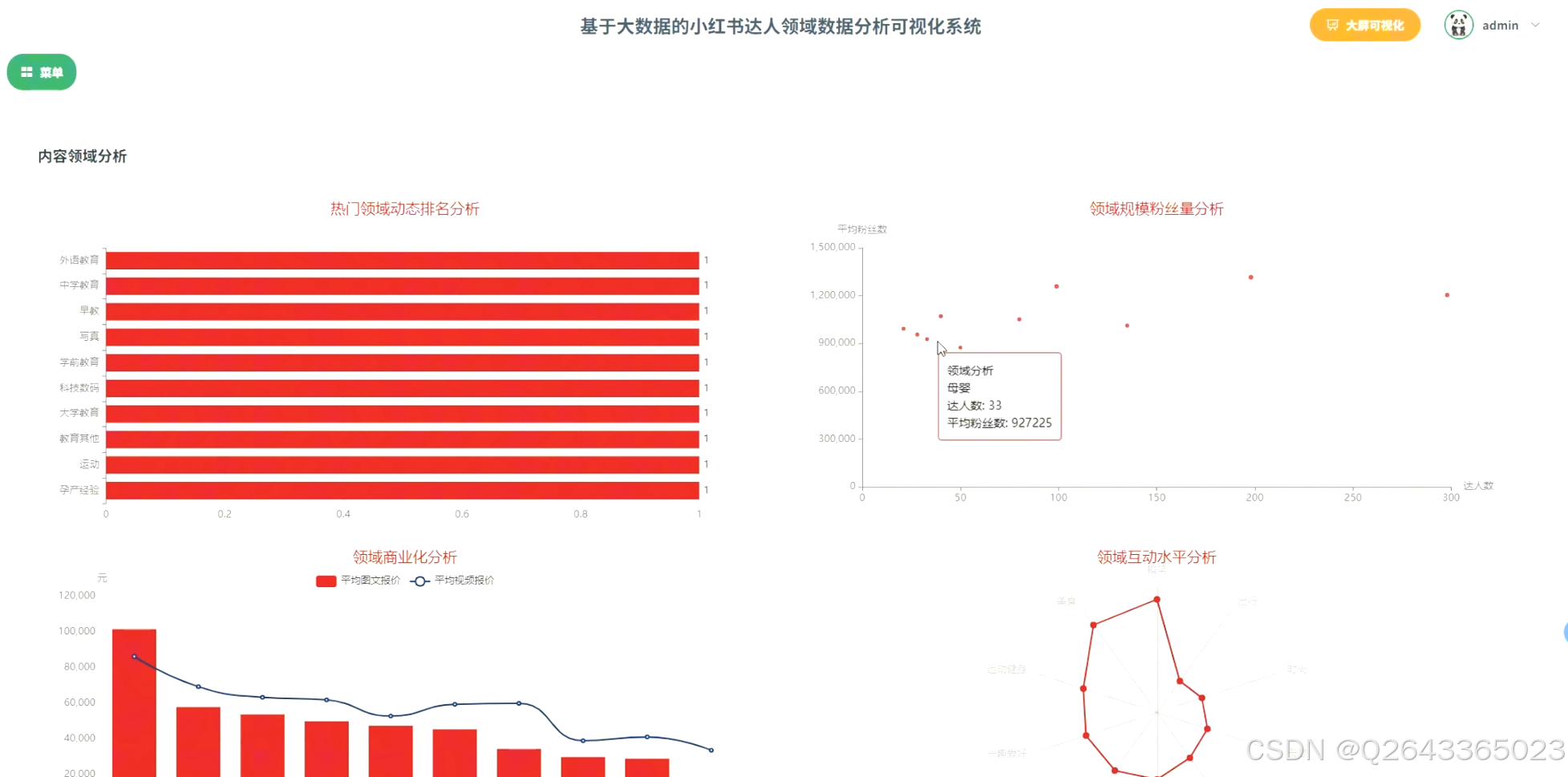
3.达人内容领域分析模块:
此模块用于深度剖析平台的内容生态。功能上,通过对达人标签字段进行拆分和词频统计,识别出热门内容领域,并进一步分析各领域的达人规模、平均粉丝量、商业化程度(平均报价)以及粉丝互动水平。研究重点在于如何处理多标签字段并进行有效聚合。
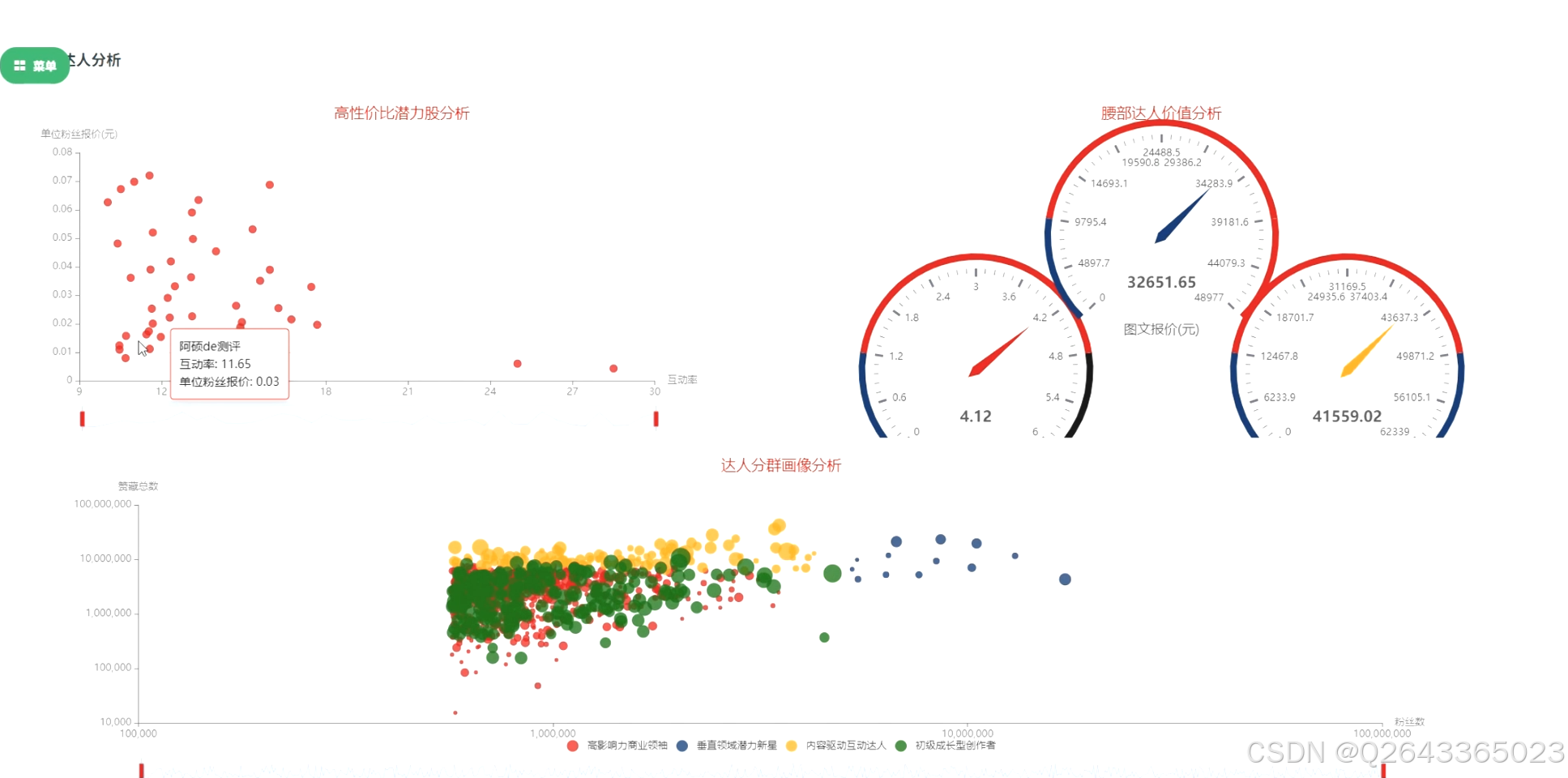
4.潜力达人挖掘模块:
此模块是系统的核心应用与创新点。功能上,将构建一个综合评分模型,筛选出高性价比的“潜力股”达人,并对营销价值显著的“腰部”达人群体进行深度画像。同时,利用K-Means算法对达人进行科学分群,并为每个群体打上如“高影响力领袖”、“高互动潜力新星”等描述性标签,实现从数据到策略的智能推荐。
3 系统展示
3.1 功能展示视频
基于hadoop+python的小红书达人领域数据分析可视化 !!!请点击这里查看功能演示!!!
3.2 大屏页面


3.3 分析页面

3.4 登录页面

4 更多推荐
计算机专业毕业设计新风向,2026年大数据 + AI前沿60个毕设选题全解析,涵盖Hadoop、Spark、机器学习、AI等类型
计算机专业毕业设计选题深度剖析,掌握这些技巧,让你的选题轻松通过,文章附35个优质选题助你顺利通过开题!
【避坑必看】26届计算机毕业设计选题雷区大全,这些毕设题目千万别选!选题雷区深度解析
紧跟风口!2026计算机毕设新赛道:精选三大热门领域下的创新选题, 拒绝平庸!毕设技术亮点+功能创新,双管齐下
纯分享!2026届计算机毕业设计选题全攻略(选题+技术栈+创新点+避坑),这80个题目覆盖所有方向,计算机毕设选题大全收藏
计算机专业毕业设计选题深度剖析,掌握这些技巧,让你的选题轻松通过,文章附35个优质选题助你顺利通过开题!
5 部分功能代码
# 1. 特征选择与预处理
# 选择用于聚类的特征列
feature_cols = ['粉丝数', '赞藏总数', '商业笔记数']
# 填充空值,确保数据完整性
df_cleaned_kmeans = df_raw.fillna(0, subset=feature_cols)
# 2. 特征工程:向量化与标准化
# VectorAssembler: 将多个特征列合并成一个向量列,这是Spark ML库的通用输入格式
assembler = VectorAssembler(inputCols=feature_cols, outputCol="features_raw")
df_vector = assembler.transform(df_cleaned_kmeans)
# StandardScaler: 对特征向量进行标准化,消除不同特征间量纲的影响,避免粉丝数等大数值特征主导聚类结果
scaler = StandardScaler(inputCol="features_raw", outputCol="scaled_features", withStd=True, withMean=False)
scaler_model = scaler.fit(df_vector)
df_scaled = scaler_model.transform(df_vector)
# 3. K-Means模型训练
# 设置聚类数量k=4,与需求分析中设想的四种达人群体对应
kmeans = KMeans(featuresCol='scaled_features', k=4, seed=1)
model = kmeans.fit(df_scaled)
# 4. 进行预测并为结果添加描述性标签
# 'transform'方法会为数据集新增一个'prediction'列,即每个达人所属的簇ID
df_clustered = model.transform(df_scaled)
# 核心步骤:根据每个簇的中心点特征,为抽象的簇ID(0,1,2,3)赋予业务含义
# 注意:此处的映射关系是基于对聚类中心点的分析得出的一个示例,实际应用中需要具体分析
# 例如,粉丝数中心点最高的簇可能为“高影响力领袖”,互动率高的簇为“高互动潜力新星”等。
cluster_descriptions = [
(0, "商业化成熟达人"), # 假设簇0商业笔记数较高
(1, "高影响力领袖"), # 假设簇1粉丝数和赞藏总数均最高
(2, "垂直领域专家"), # 假设簇2粉丝数中等,但互动率可能较高
(3, "高互动潜力新星") # 假设簇3粉丝数较少,但赞藏数相对较高
]
# 使用when().otherwise()链式调用,为每个簇ID映射一个描述性字符串
df_with_desc = df_clustered
for cluster_id, desc in cluster_descriptions:
df_with_desc = df_with_desc.withColumn("cluster_description",
when(col("prediction") == cluster_id, desc)
.otherwise(col("cluster_description") if "cluster_description" in df_with_desc.columns else None))
# 5. 整理、展示并保存最终结果
final_result_kmeans = df_with_desc.select(
"达人名称", "粉丝数", "赞藏总数", "商业笔记数",
col("prediction").alias("cluster_id"),
"cluster_description"
).orderBy("cluster_id")
print("\n--- K-Means达人分群结果 ---")
final_result_kmeans.show(40)
# 将结果保存为单个CSV文件
# final_result_kmeans.toPandas().to_csv("kmeans_clustering_analysis.csv", index=False, encoding='utf-8-sig')
# 停止SparkSession
spark.stop()
源码项目、定制开发、文档报告、PPT、代码答疑
希望和大家多多交流 ↓↓↓↓↓

















 951
951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









