




第七章:时间序列模型
第二部分:时间序列统计模型与神经网络模型
第四节:时间序列大模型: 谷歌TimesFM模型
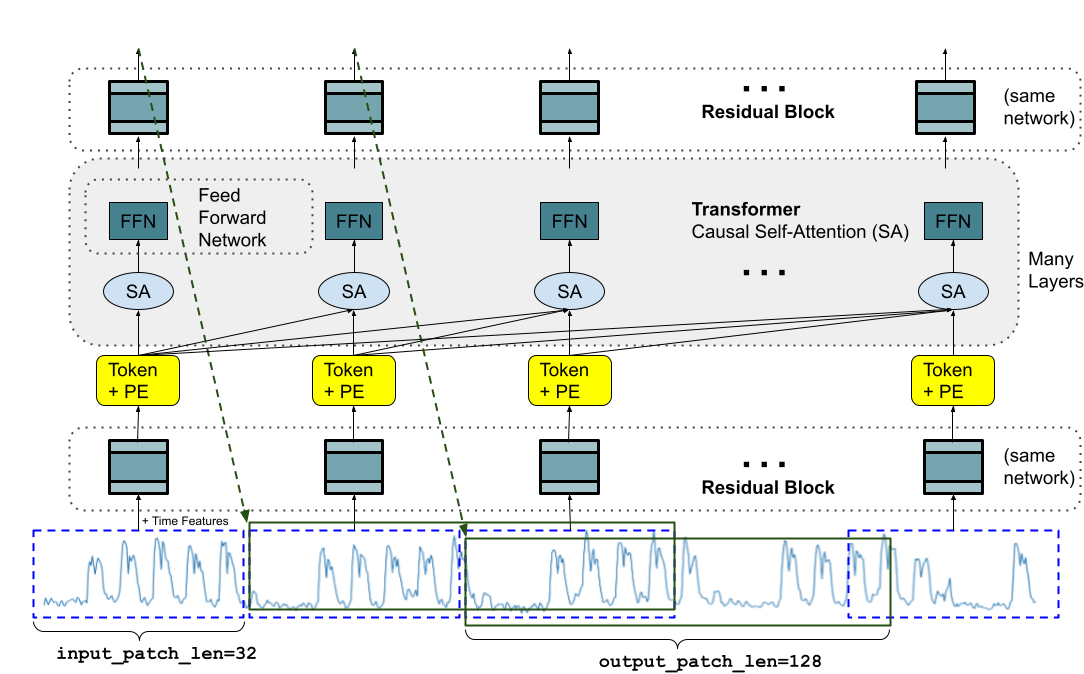
一、背景与模型定位
Google Research 提出的 TimesFM 是一个 面向时间序列预测的基础模型(Foundation Model),类似于 NLP 领域的 LLM(如 GPT‑3/PaLM) — 它预训练于大规模时间序列数据集,然后可用于多场景、零样本(zero-shot)或少样本预测。
-
官方博客指出其预训练数据包含 “100 billion real-world time-points” 。
-
它以 decoder-only Transformer 架构为核心。
-
它已被集成进 BigQuery ML 的模型服务中,方便用户直接使用。
因此,TimesFM 在“统计模型 +传统深度模型”基础上,实现了 “通用、自适应、多场景的时间序列预测” 的升级版。
二、模型核心设计与架构
2.1 Patch 化 & Token 化
-
将时间序列切分为 patches(例如连续 (p) 个时间点为一 patch),将其视作一个 “token”,类似 NLP 模型中 sub-word token。
-
输入为若干历史 patches,输出为若干未来 patches(可能 (>p))。这种设计支持 长 horizon 预测。
2.2 Decoder-Only Transformer
-
模型采用经典 Transformer 的自注意力 + 前馈网络结构,但仅用 解码器(decoder) 部分,不包含编码器-解码器结构。
-
支持 variable context length(历史长度)与 variable horizon length(预测长度),增强通用性。
2.3 预训练 + 零样本迁移
-
该模型预训练于上百亿时间点,覆盖多频率、多个领域、不同粒度。
-
在新的、未见过的数据集上可实现 zero-shot forecasting(无需专门训练即能良好预测)。
2.4 输入与输出细节
-
输入:历史时间序列 patches + 可选 frequency indicator。
-
输出:未来一段时间序列(patches)。
-
支持的 context 长度、模型版本、参数规模各不同:如 v2.0 参数约 5 亿、支持 up to context length ≈ 2048 time-points。
三、为什么 TimesFM 是时间序列模型的“黑科技”
-
通用性强:无需为每个序列重新训练,即可应用于多场景。
-
长依赖能力强:Transformer 架构能捕捉长序列中的远程关系。
-
提升效率:相比传统逐步预测(如 ARIMA、LSTM)可快速应用。
-
零样本能力:在多个公开基准上,其 zero-shot 表现接近或优于监督训练模型。
四、适用场景与限制
适用场景
-
零售销量预测、交通流量、设备传感器监控、能源负荷、财务指标等。
-
需要快速部署、覆盖多任务、少量特化训练的场景。
-
希望借助预训练模型加快开发周期、减少调参成本。
限制与注意事项
-
虽然通用,但在 高度领域化或强多变量依赖 情况下仍可能劣于专门模型。
-
当前版本聚焦 univariate forecasting(单变量),虽然支持 covariate 探索,但功能有限。
-
模型规模大,推理资源要求相对高;需考虑模型压缩、推理优化。
-
解释性较传统统计模型弱(虽比多数 “黑盒” 深度模型好)。
五、简单使用示例
以下为一个快速使用 TimesFM 的 Python 流程(基于 Hugging Face 与 timesfm 库):
# 安装
!pip install timesfm
# 使用
import timesfm
import pandas as pd
# 加载数据
df = pd.read_csv('your_timeseries.csv', parse_dates=['ds'])
# 假设列为 'y'
tfm = timesfm.TimesFm.from_pretrained("google/timesfm-2.0-500m-pytorch")
forecast_df = tfm.forecast_on_df(
inputs = df.rename(columns={'ds':'time','y':'value'}),
horizon = 24,
freq = "MS" # 月度数据
)
print(forecast_df.head())
此外,在 BigQuery ML 中亦可用 SQL 方式调用:
SELECT *
FROM AI.FORECAST(
MODEL = `timesfm_univariate_model`,
table = ...,
horizon => 12
)
六、与传统模型对比:概览表
| 模型类型 | 核心机制 | 优势 | 劣势 |
|---|---|---|---|
| ARIMA/ETS | 线性、自回归、差分 | 参数少、解释好 | 难捕捉非线性、长依赖弱 |
| LSTM/Transformer(专用) | 深度循环或注意力机制 | 长依赖、非线性建模强 | 训练调参复杂、需大数据 |
| TimesFM(基础模型) | 预训练 Transformer,zero-shot | 通用性高、少训练成本 | 单变量限制、资源需求高 |
七、小结与视野
-
TimesFM 是时间序列预测领域迈向 “基础模型” 的代表作。
-
它将“预训练 +迁移”范式带入时序预测,使模型开发更便捷、覆盖更广。
-
虽不全能替代专门模型,但在多数通用场景下,是强有力的选择。
-
对于我们学习时间序列模型者:在掌握 ARIMA、LSTM 等基础后,了解 TimesFM 代表 未来趋势:模型通用化 +少调参化。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









