



 本文探讨了在使用Spark Streaming进行实时数据处理,并尝试将结果写入MySQL数据库时遇到的Task not serializable错误。通过分析代码示例,详细解释了错误原因在于JDBC连接无法被序列化,提出了正确的解决方案,即将数据库操作封装在foreachPartition方法中,以避免序列化问题。
本文探讨了在使用Spark Streaming进行实时数据处理,并尝试将结果写入MySQL数据库时遇到的Task not serializable错误。通过分析代码示例,详细解释了错误原因在于JDBC连接无法被序列化,提出了正确的解决方案,即将数据库操作封装在foreachPartition方法中,以避免序列化问题。
做spark开发错误 task不能序列化
18/09/25 14:47:35 ERROR JobScheduler: Error running job streaming job 1537858055000 ms.1
org.apache.spark.SparkException: Task not serializable
是什么不能序列化呢?是mysql连接,这种写法是错误的
//将结果输出到mysql中
result.foreachRDD(rdd => {
val connection = createConnection()
rdd.foreach { r =>
val sql = "insert into table wordCount Values('" + r._1 + "','" + r._2 + "')"
connection.createStatement().execute(sql)
}
})
package streaming
import java.sql.DriverManager
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 使用spark streaming 完成有状态统计,并将结果写入到mysql数据库中
*/
object ForeachRDDAPP {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("ForeachRDDAPP").setMaster("local[2]")
val ssc = new StreamingContext(conf,Seconds(5))
ssc.checkpoint(".")
val line: ReceiverInputDStream[String] = ssc.socketTextStream("192.168.100.100",7777)
val result: DStream[(String, Int)] = line.flatMap(_.split(" ")).map((_ , 1 )).reduceByKey( _ + _ )
//此处是打印到控制台
result.print()
//将结果输出到mysql中
// result.foreachRDD(rdd => {
// val connection = createConnection()
// rdd.foreach { r =>
// val sql = "insert into table wordCount Values('" + r._1 + "','" + r._2 + "')"
// connection.createStatement().execute(sql)
// }
// })
result.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
// ConnectionPool is a static, lazily initialized pool of connections
val connection = createConnection()
partitionOfRecords.foreach(r => {
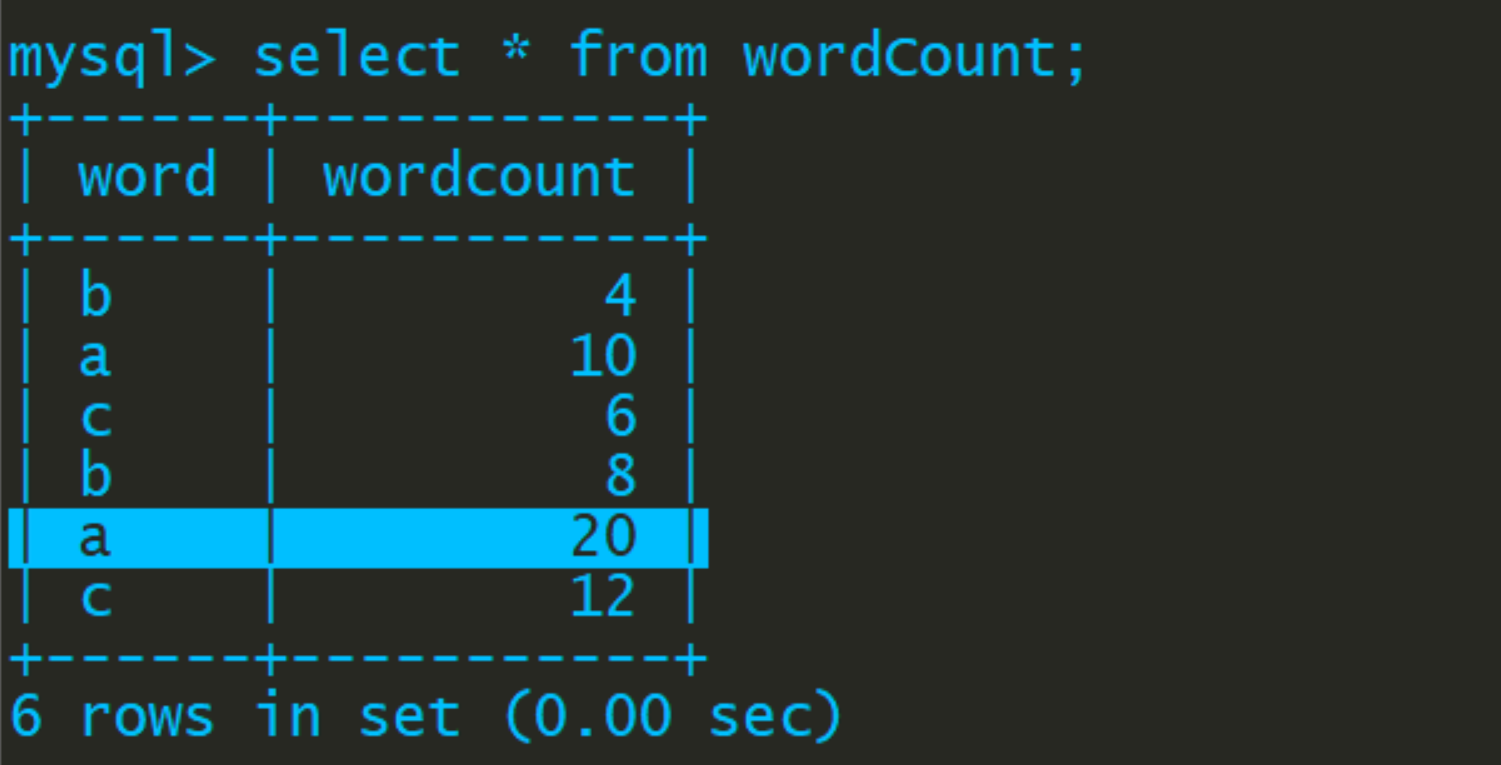
val sql = "insert into wordCount Values('" + r._1 + "'," + r._2 + ")"
connection.createStatement().execute(sql)
})
connection.close()
}
}
ssc.start()
ssc.awaitTermination()
}
/**
* 获取mysql的连接
* @return
*/
def createConnection() = {
Class.forName("com.mysql.jdbc.Driver")
DriverManager.getConnection("jdbc:mysql://192.168.100.100:3306/test","root","123456")
}
}

















 5301
5301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









