



前言
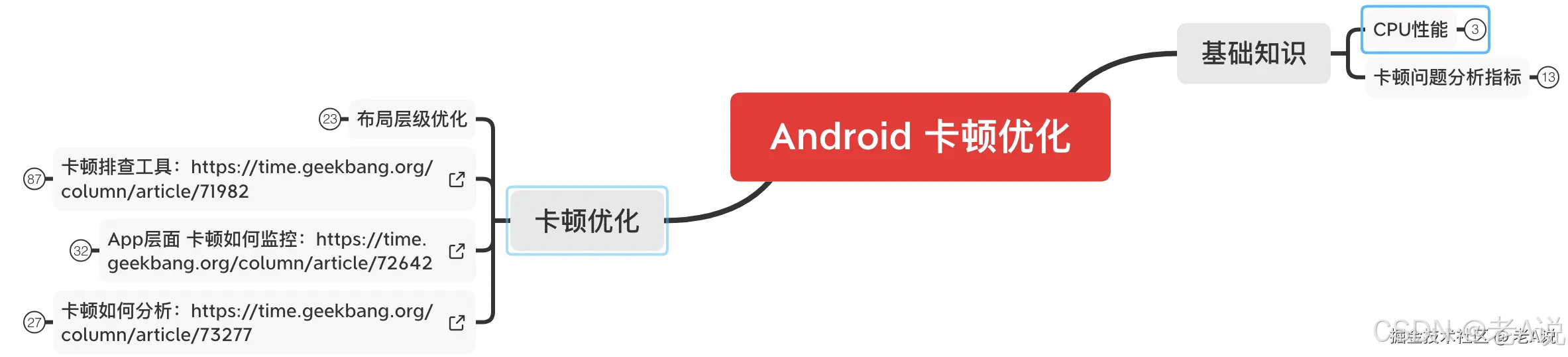
本章我们来讲一下卡顿和布局如何进行优化?
线上卡顿如何监控?
先来讲解一些基础知识,便于我们理解卡顿监控
CPU 性能
造成卡顿的原因可能有千百种,不过最终都会反映到 CPU 时间上。我们可以把 CPU 时间分为两种:用户时间和系统时间
- 用户时间就是执行用户态应用程序代码所消耗的时间;
- 系统时间就是执行内核态系统调用所消耗的时间,包括 I/O、锁、中断以及其他系统调用的时间;
卡顿问题分析指标
CPU 使用率
我们可以通过 /proc/stat 得到整个系统的 CPU 使用情况,通过 /proc/[pid]/stat 可以得到某个进程的 CPU 使用情况
- proc/self/stat: utime: 用户时间,反应用户代码执行的耗时 stime: 系统时间,反应系统调用执行的耗时 majorFaults:需要硬盘拷贝的缺页次数 minorFaults:无需硬盘拷贝的缺页次数;
- top 命令可以帮助我们查看哪个进程是 CPU 的消耗大户;
- vmstat 命令可以实时动态监视操作系统的虚拟内存和 CPU 活动;
- strace 命令可以跟踪某个进程中所有的系统调用;
CPU 饱和度
CPU 饱和度反映的是线程排队等待 CPU 的情况,也就是 CPU 的负载情况。
- CPU 饱和度首先会跟应用的线程数有关,如果启动的线程过多,容易导致系统不断地切换执行的线程,把大量的时间浪费在上下文切换,我们知道每一次 CPU 上下文切换都需要刷新寄存器和计数器,至少需要几十纳秒的时间;
- CPU 饱和度和线程优先级也有关;
- 线程优先级会影响 Android 系统的调度策略,它主要由 nice 和 cgroup 类型共同决定。nice 值越低,抢占 CPU 时间片的能力越强。当 CPU 空闲时,线程的优先级对执行效率的影响并不会特别明显,但在 CPU 繁忙的时候,线程调度会对执行效率有非常大的影响;
- 我们可以通过使用 vmstat 命令或者 /proc/[pid]/schedstat 文件来查看 CPU 上下文切换次数,这里特别需要注意 nr_involuntary_switches 被动切换的次数;
- proc/self/sched: nr_voluntary_switches: 主动上下文切换次数,因为线程无法获取所需资源导致上下文切换,最普遍的是IO;
- nr_involuntary_switches: 被动上下文切换次数,线程被系统强制调度导致上下文切换,例如大量线程在抢占CPU;
- se.statistics.iowait_count:IO 等待的次数;
- se.statistics.iowait_sum: IO 等待的时间;
卡顿问题分析工具-systrace
卡顿分析,不仅仅只有 systrace
安装教程
要使用Systrace,需要先安装 Python2.7。安装完成后配置环境变量path ,随后在命令行输入: python – version 进行验证;
Systrace具体使用可以查看博客:使用
Androidr sdk 中的 platform-tools 下的 systrace.py
就是一个 python 脚本,直接
python systrace.py
执行 --help 后会提供一些帮助命令
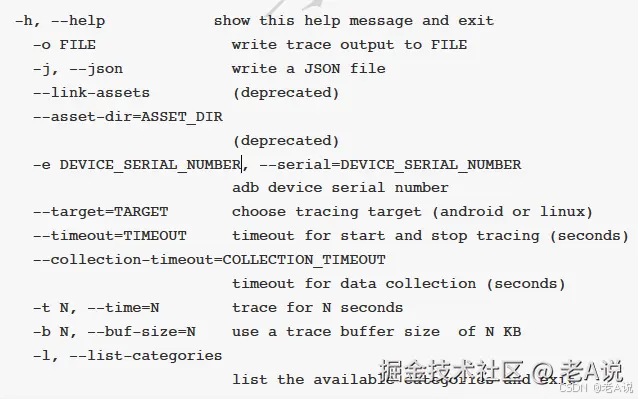
执行 --list-categories 会提供一些查看命令
gfx
Graphics 图形系统,包括SerfaceFlinger,VSYNC消息,Texture,RenderThread等
input
Input输入系统,按键或者触摸屏输入;分析滑动卡顿等
view
View绘制系统的相关信息,比如onMeasure,onLayout等;分析View绘制性能
am
ActivityManager调用的相关信息;分析Activity的启动、跳转
dalvik
虚拟机相关信息;分析虚拟机行为,如 GC停顿
sched
CPU调度的信息,能看到CPU在每个时间段在运行什么线程,线程调度情况,锁信息
disk
IO信息
wm
WindowManager的相关信息
res
资源加载的相关信息
使用方式
python systrace.py -t 8 -o test_trace.html gfx input view am dalvik sched wm disk res -a com.llc.example
默认是写将文件创建到了 systrace 所在目录下,可以将它移动到想要的位置;
然后我们用 chrome://tracing 打开这个 html 文件
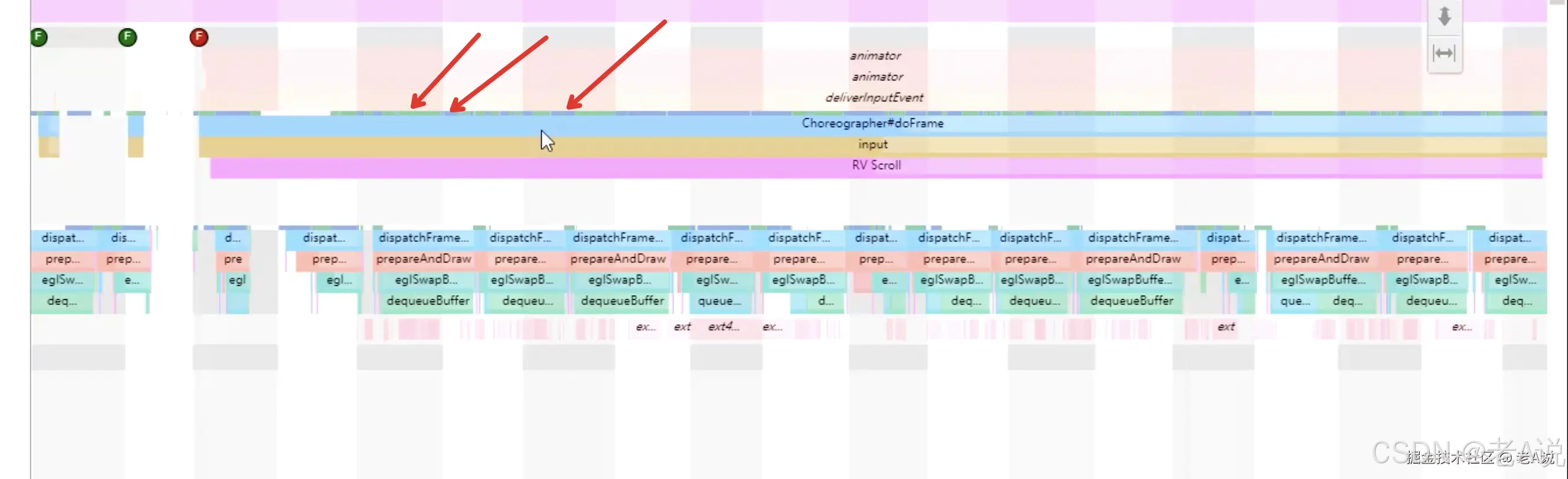
建议使用 Perfetto UI 来分析;打开之后,我们要重点关注的就是 Frame 下的相关信息
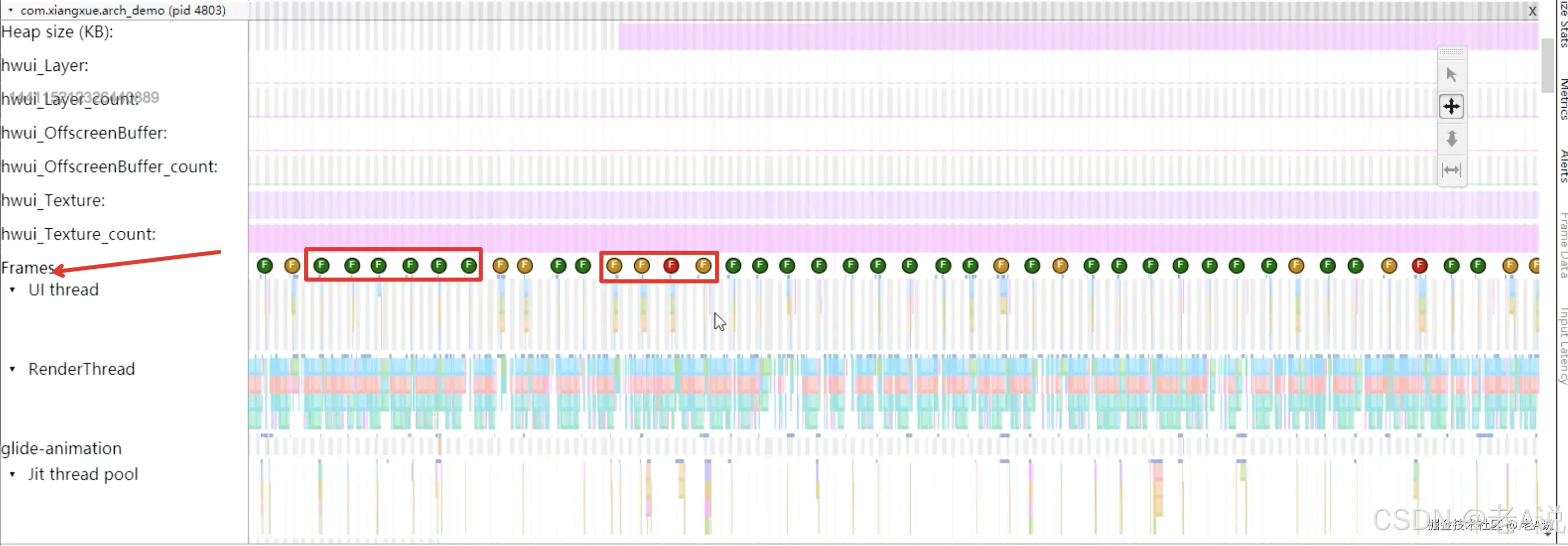
绿色表示 帧间隔在 16ms,黄色红色表示 帧间隔大于 16ms,偶尔的一次黄色 偶尔的一次红色其实是没有太大关系的,连续的红色或者黄色 表示卡顿;
这里我们需要了解下 Android 底层渲染机制;
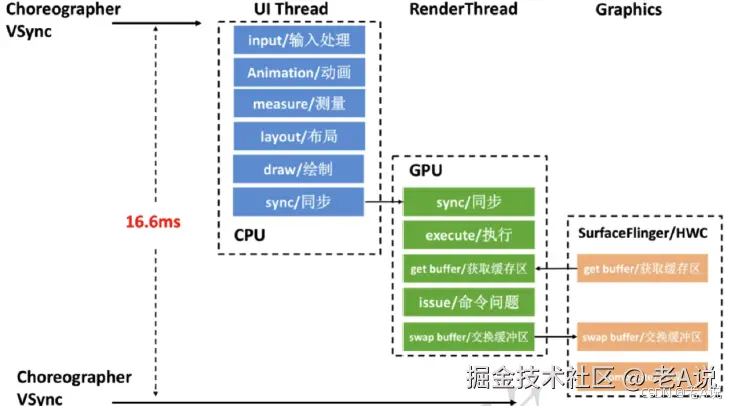
这个 16.6 代表着一个 VSync 的同步信号,每隔这样的一个时间点就会有一个脉冲,每一帧都在这个16.6ms 超过这个时间就会有肉眼可见的卡顿,当有 同步信号 过来的时候,首先会进行 input、动画的处理,通过 CPU 在 UI 线程计算完成之后,它会把这个计算结果给到 RenderThread,这里就涉及到了跟 GPU 跟屏幕硬件相关的绘制逻辑;
所以,我们的 trace 文件中会有 UI Thread 和 RenderThread;
我们在工作中,当用 systrace 追踪启动优化的时候,同时也需要借助 Trace 类下的两个方法,用来进行 tag 的标记;
protected void attachBaseContext(Context base) {
super.attachBaseContext(base);
Trace.beginSection("cool start");
}
在首个 Activity 的 onWindowFocusChanged 回调中执行结束点
override fun onWindowFocusChanged(hasFocus: Boolean) {
super.onWindowFocusChanged(hasFocus)
Trace.endSection()
}
这样,在我们生成的 trace 文件中就能看到这两个之间的耗时,这样,我们就能查看我们的启动耗时并进行优化;
如何用 systrace 看线上 release 包?
可以通过反射 setAppTracingAllowed 来实现线上 release
/**
* From Android S, this is no-op.
*
* Before, set whether application tracing is allowed for this process. This is intended to be
* set once at application start-up time based on whether the application is debuggable.
*
* @hide
*/
@UnsupportedAppUsage
public static void setAppTracingAllowed(boolean allowed) {
nativeSetAppTracingAllowed(allowed);
}
线上卡顿如何监控
线上监控方案有:消息队列、线程监控,插桩等等
消息队列 (Looper Printer 时间差)
利用UI线程Looper打印的日志匹配(通过替换 Looper 的 Printer 实现)

可以看到,消息分发之前和之后都有一个打印,我们可以接管系统中的这个 logging,当执行到 println 的时候,执行我们自己的 println 方法来记录这两个之间(msg.target.dispatchMessage())的间隔是否大于 16ms,大于则认为发生了卡顿;
Looper.getMainLooper().setMessageLogging(new Printer() {
@Override
public void println(String x) {
}
});
通过这个方法来接管 Printer; BlockCanary 也是基于这个的实现原理;
但是这种方案的弊端就是:可能不准,再一个就是时间区间内,不能精确定位到具体是哪里发生了卡顿,需要再精细化分析;
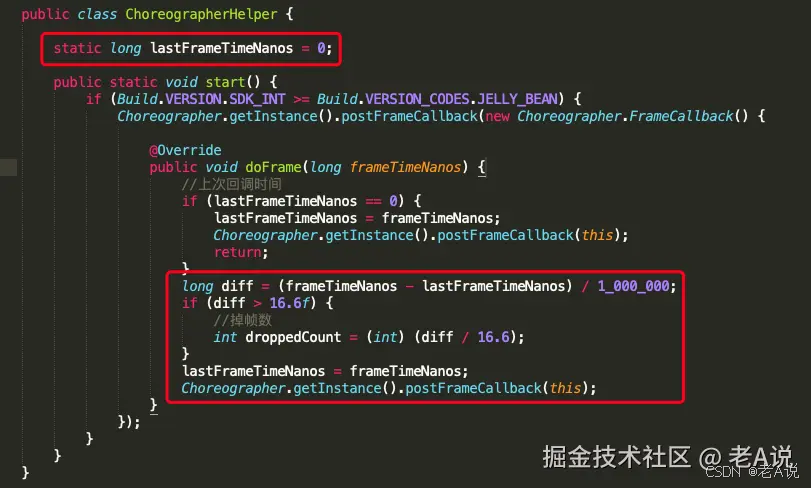
Choreographer.FrameCallback
设置FrameCallback来接收编舞者的callback回调。记录两次vsync的时间差,大于了16ms ,超过阈值认为卡顿
监控线程
一个监控线程,每隔 1 秒向主线程消息队列的头部插入一条空消息。假设 1 秒后这个消息并没有被主线程消费掉,说明阻塞消息运行的时间在 0~1 秒之间。换句话说,如果我们需要监控 3 秒卡顿(也可以是 5s ANR),那在第 4 次轮询中头部消息依然没有被消费的话,就可以确定主线程出现了一次 3 秒以上的卡顿(也可以是 5s ANR);
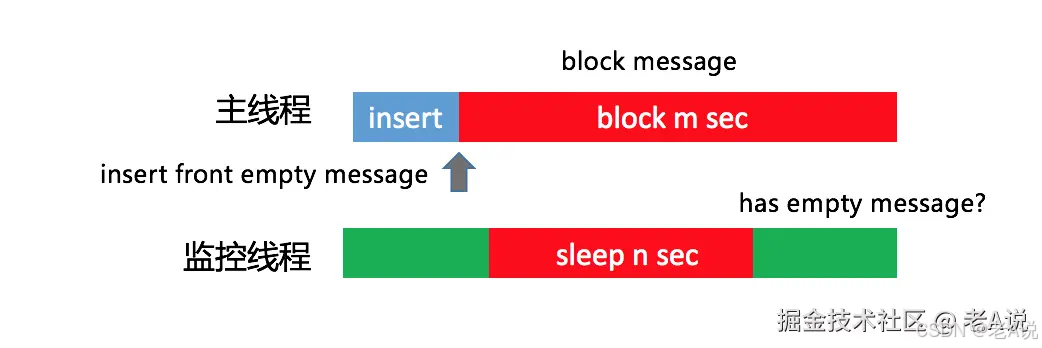
这个方案也存在一定的误差,那就是发送空消息的间隔时间。但这个间隔时间也不能太小,因为监控线程和主线程处理空消息都会带来一些性能损耗,但基本影响不大;
这个通常用来做 ANR 的监控
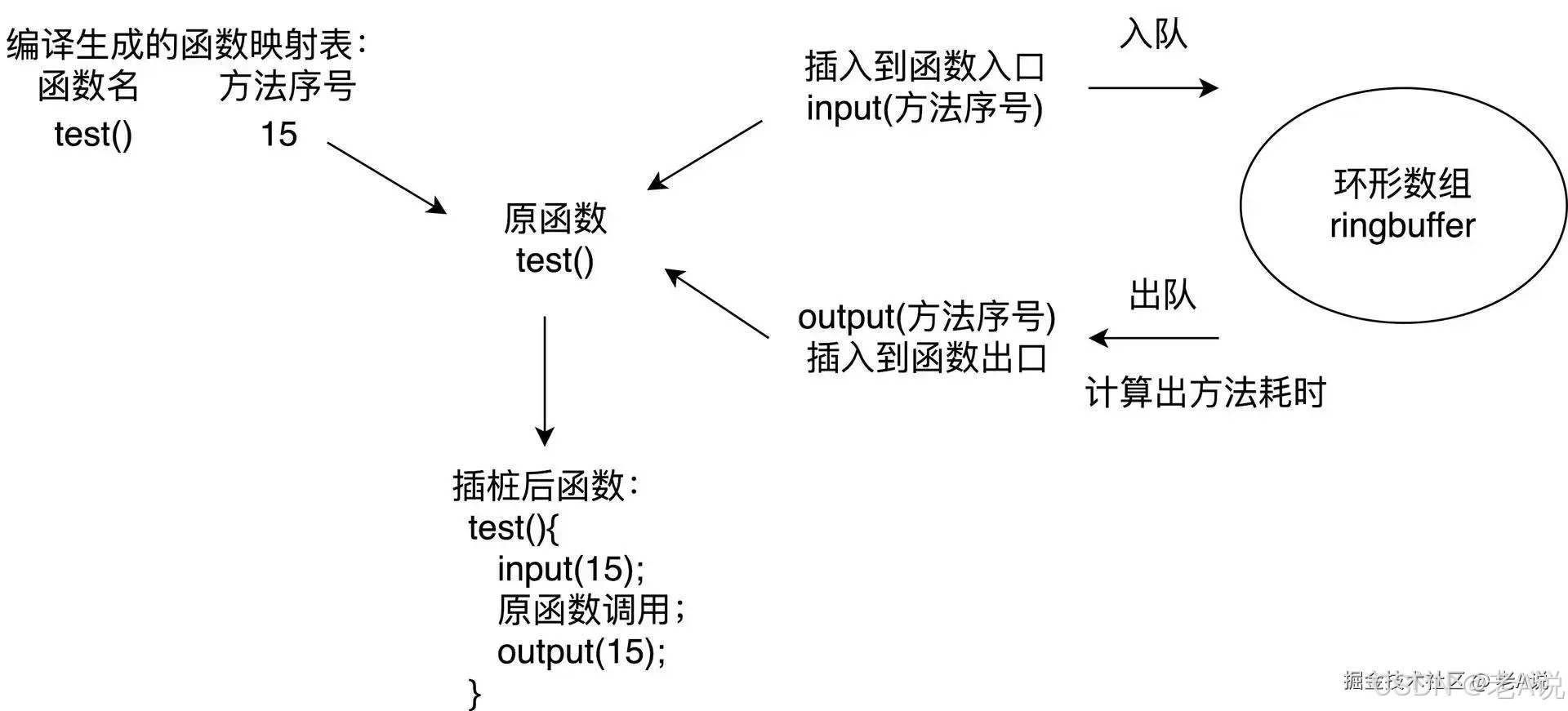
插桩
使用 Inline Hook 技术,编译过程中插桩,在函数入口和出口加入耗时监控的代码。我们可以实现类似 Nanoscope 先写内存的方案;
- 避免方法数暴增。在函数的入口和出口应该插入相同的函数,在编译时提前给代码中每个方法分配一个独立的 ID 作为参数;
- 过滤简单的函数。过滤一些类似直接 return、i++ 这样的简单函数,并且支持黑名单配置。对一些调用非常频繁的函数,需要添加到黑名单中来降低整个方案对性能的损耗;
布局加载优化
说起布局加载优化,那么就需要了解布局的加载原理,只有懂了其中的原理,我们才能有针对性的进行加载优化,布局如何加载,可以看下我前面讲插件化换肤的文章;
我们从插件化换肤的方案中,利用 setFactory2 这个方法来获取到布局加载的耗时;
LayoutInflaterCompat.setFactory2(layoutInflater, object : Factory2{
override fun onCreateView(
parent: View?,
name: String,
context: Context,
attrs: AttributeSet
): View? {
val time = System.currentTimeMillis()
val view: View = this@MainActivity.getDelete().createView(parent, name, context, attrs)
LogEx.d(TAG, "name cost: " + (System.currentTimeMillis() - time))
return view
}
override fun onCreateView(name: String, context: Context, attrs: AttributeSet): View? {
TODO("Not yet implemented")
}
})
当我们拿到每一个 View 的创建耗时的时候,就可以 case by case 的去进行优化了;
优化方式
- 这也是掌阅开源的 X2C 的原理,不采用反射的方式创建 View,通过 APT + javaPoet + new 技术生成对应的 java 文件并映射;
public static void setContentView(Activity activity, int layoutId) {
if (activity == null) {
throw new IllegalArgumentException("Activity must not be null");
}
View view = getView(activity, layoutId);
if (view != null) {
activity.setContentView(view);
} else {
activity.setContentView(layoutId);
}
}
getView 就是通过 new 的方式替换反射的方式创建 View,然后通过 setContentView 重新设置回去;
public static View getView(Context context, int layoutId) {
IViewCreator creator = sSparseArray.get(layoutId);
if (creator == null) {
try {
int group = generateGroupId(layoutId);
String layoutName = context.getResources().getResourceName(layoutId);
layoutName = layoutName.substring(layoutName.lastIndexOf("/") + 1);
String clzName = "com.zhangyue.we.x2c.X2C" + group + "_" + layoutName;
creator = (IViewCreator) context.getClassLoader().loadClass(clzName).newInstance();
} catch (Exception e) {
e.printStackTrace();
}
//如果creator为空,放一个默认进去,防止每次都调用反射方法耗时
if (creator == null) {
creator = new DefaultCreator();
}
sSparseArray.put(layoutId, creator);
}
return creator.createView(context);
}
- AsyncLayoutInflater

原理就是:通过 InflaterThread 在子线程中执行 inflate 操作,然后通过 handler 将结果 post 到主线程,所以需要在 OnInflatFinished 回调中初始化 View;
但是 这种方案也有弊端,官方也并没有建议必须使用,例如 xml 中有 Fragment 是不支持的;
BlockCanary 原理
BlockCanary的原理:实现Printer接口,并通过Looper().getMainLooper().setMessageLogging() 来接管系统中的 logging,这样,当执行到 logging.println(“”) 的时候,就会执行我们自己的 println 方法
手写实现
public class BlockCanary {
public static void install() {
LogMonitor logMonitor = new LogMonitor();
Looper.getMainLooper().setMessageLogging(logMonitor);
}
}
LogMonitor 实现了 Printer 接口,并重写了 println 方法;
public class LogMonitor implements Printer {
private StackSampler mStackSampler;
private boolean mPrintingStarted = false;
private long mStartTimestamp;
// 卡顿阈值,超过3s 则认为发生了卡顿
private long mBlockThresholdMillis = 3000;
//采样频率
private long mSampleInterval = 1000;
private Handler mLogHandler;
public LogMonitor() {
mStackSampler = new StackSampler(mSampleInterval);
HandlerThread handlerThread = new HandlerThread("block-canary-io");
handlerThread.start();
mLogHandler = new Handler(handlerThread.getLooper());
}
@Override
public void println(String x) {
// 从 if 到 else 会执行 dispatchMessage,如果执行耗时超过阈值,输出卡顿信息
if (!mPrintingStarted) {
//记录开始时间
mStartTimestamp = System.currentTimeMillis();
mPrintingStarted = true;
mStackSampler.startDump();
} else {
final long endTime = System.currentTimeMillis();
mPrintingStarted = false;
// 出现卡顿
if (isBlock(endTime)) {
notifyBlockEvent(endTime);
}
mStackSampler.stopDump();
}
}
private void notifyBlockEvent(final long endTime) {
mLogHandler.post(new Runnable() {
@Override
public void run() {
//获得卡顿时主线程堆栈
List<String> stacks = mStackSampler.getStacks(mStartTimestamp, endTime);
for (String stack : stacks) {
Log.e("block-canary", stack);
}
}
});
}
private boolean isBlock(long endTime) {
return endTime - mStartTimestamp > mBlockThresholdMillis;
}
}
StackSampler 就是 dump 卡顿信息;
public class StackSampler {
public static final String SEPARATOR = "\r\n";
public static final SimpleDateFormat TIME_FORMATTER =
new SimpleDateFormat("MM-dd HH:mm:ss.SSS");
private Handler mHandler;
private Map<Long, String> mStackMap = new LinkedHashMap<>();
private int mMaxCount = 100;
private long mSampleInterval;
//是否需要采样
protected AtomicBoolean mShouldSample = new AtomicBoolean(false);
public StackSampler(long sampleInterval) {
this.mSampleInterval = sampleInterval;
HandlerThread handlerThread = new HandlerThread("block-canary-sampler");
handlerThread.start();
mHandler = new Handler(handlerThread.getLooper());
}
public void startDump() {
//避免重复开始
if (mShouldSample.get()) {
return;
}
mShouldSample.set(true);
mHandler.removeCallbacks(mRunnable);
mHandler.postDelayed(mRunnable, mSampleInterval);
}
public void stopDump() {
if (!mShouldSample.get()) {
return;
}
mShouldSample.set(false);
mHandler.removeCallbacks(mRunnable);
}
public List<String> getStacks(long startTime, long endTime) {
ArrayList<String> result = new ArrayList<>();
synchronized (mStackMap) {
for (Long entryTime : mStackMap.keySet()) {
if (startTime < entryTime && entryTime < endTime) {
result.add(TIME_FORMATTER.format(entryTime)
+ SEPARATOR
+ SEPARATOR
+ mStackMap.get(entryTime));
}
}
}
return result;
}
private Runnable mRunnable = new Runnable() {
@Override
public void run() {
StringBuilder sb = new StringBuilder();
StackTraceElement[] stackTrace = Looper.getMainLooper().getThread().getStackTrace();
for (StackTraceElement s : stackTrace) {
sb.append(s.toString()).append("\n");
}
synchronized (mStackMap) {
//最多保存100条堆栈信息
if (mStackMap.size() == mMaxCount) {
mStackMap.remove(mStackMap.keySet().iterator().next());
}
mStackMap.put(System.currentTimeMillis(), sb.toString());
}
if (mShouldSample.get()) {
mHandler.postDelayed(mRunnable, mSampleInterval);
}
}
};
}
好了,卡顿优化就写到这里吧~
下一张预告
继续性能优化
欢迎三连
来都来了,点个关注,点个赞吧

















 442
442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









