



 本文详细解释了synchronized在代码块和方法中的工作原理,涉及monitorenter/monitorexit字节码、锁的存放位置(对象头),以及轻量级锁、重量级锁和偏向锁的实现和优劣。讨论了StopTheWorld现象在撤销偏向锁时的使用。最后提到Lock与synchronized的对比和使用建议。
本文详细解释了synchronized在代码块和方法中的工作原理,涉及monitorenter/monitorexit字节码、锁的存放位置(对象头),以及轻量级锁、重量级锁和偏向锁的实现和优劣。讨论了StopTheWorld现象在撤销偏向锁时的使用。最后提到Lock与synchronized的对比和使用建议。
synchronized 原理
synchronized 作用在代码块
public class VolatileTest {
public volatile int count;
public void add() {
synchronized (this) {
count ++;
}
}
private static class Count extends Thread {
VolatileTest volatileTest;
public Count(VolatileTest volatileTest) {
this.volatileTest = volatileTest;
}
@Override
public void run() {
super.run();
for (int i = 0; i < 10000; i++) {
volatileTest.add();
}
}
}
public static void main(String[] args) throws InterruptedException {
VolatileTest volatileTest = new VolatileTest();
Count count1 = new Count(volatileTest);
Count count2 = new Count(volatileTest);
count2.start();
count1.start();
Thread.sleep(50);
System.out.println(volatileTest.count);
}
}执行这段代码之后,我们反编译 生成的 VolatileTest.class 文件,使用 javap -v VolatileTest.class
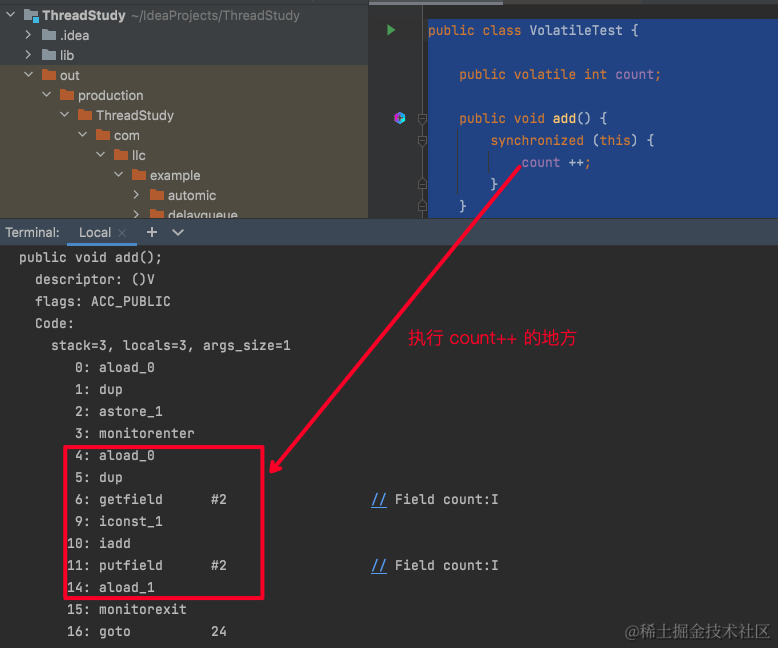
我们发现,这段代码被一个 monitorenter 和 monitorexit 所包裹,这两个字节码指令是由 JVM 在 .java 编译成 .class 的时候 帮我们插入的;
当执行到 monitorenter 这个指令的时候,就会尝试获取锁,每一个 monitorenter 在 JVM 中都是有一个 Monitor 对象与之相对应,我们所说的拿锁,本质上就是拿到这个对象的所有权,谁拿到这个对象的所有权,就表示谁进入了一个锁的状态;
所以说 synchronized 本质原理:就是通过 monitorenter 和 monitorexit 字节码指令实现的;
monitorenter:插入到同步代码块开始的位置;
monitorexit:插入到同步代码块结束的位置;
synchronized 作用在方法
我们把 synchronized 放在方法上
public synchronized void add() {
count ++;
} 然后查看编译后的字节码
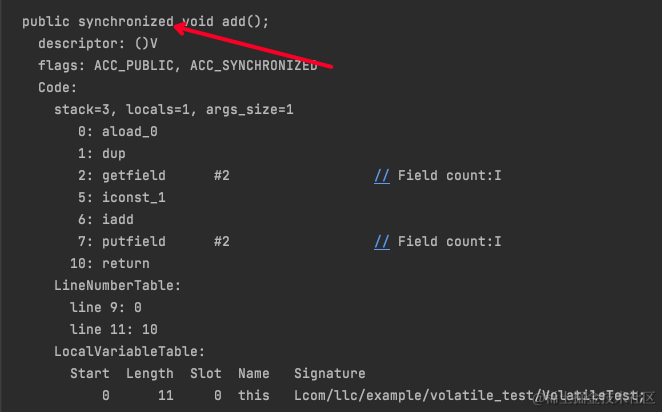
flags 多了一个 ACC_SYNCHRONIZED 标识符,代表着这是一个同步方法,底层还是使用的 monitor,与同步代码块的不同的是我们看不到 monitor 的存在,它是在运行时被添加的;
锁的存放位置
我们使用 synchronized 来加锁,那么锁的位置存放在哪里呢?对于 synchronized 关键字而言,它存放在 Java 的对象头里;
当我们 new 一个对象的时候,它在内存中除了对象体之外,还有对象头,对象头中就包含了一些我们当前对象的关键信息,比如:GC年龄、对象hasCode、属性指针、类型指针(KlassPoint)等等,这个对象头在虚拟机中有个专门的称呼:MarkWord;
GC年龄
- 对象被回收的次数,当一个对象在堆中被创建之后,经过多次的垃圾回收而没有被回收到(JVM 缺省是15次),就会被放入老年代,记录这个次数的就是GC年龄;
类型指针(KlassPoint)
- new 的这个对象属于哪个类,通过对象头中的这个类型指针来标记;
synchronized 就存放在这个对象头(MarkWord)区域;

可以看到这是在无锁状态下 hashCode、分代年龄 就已经把这个 MarkWord 区域占满了,当我们进行加锁的时候,这个锁的信息位置放在了哪里呢?这个对象头的内容随着对象的运行是会发生改变的,而且根据 synchronized 关键字它在实现上引入了一个偏向锁、轻量级锁、以及GC的情况下,这个MarkWord内的值是会不断的发生变化的;
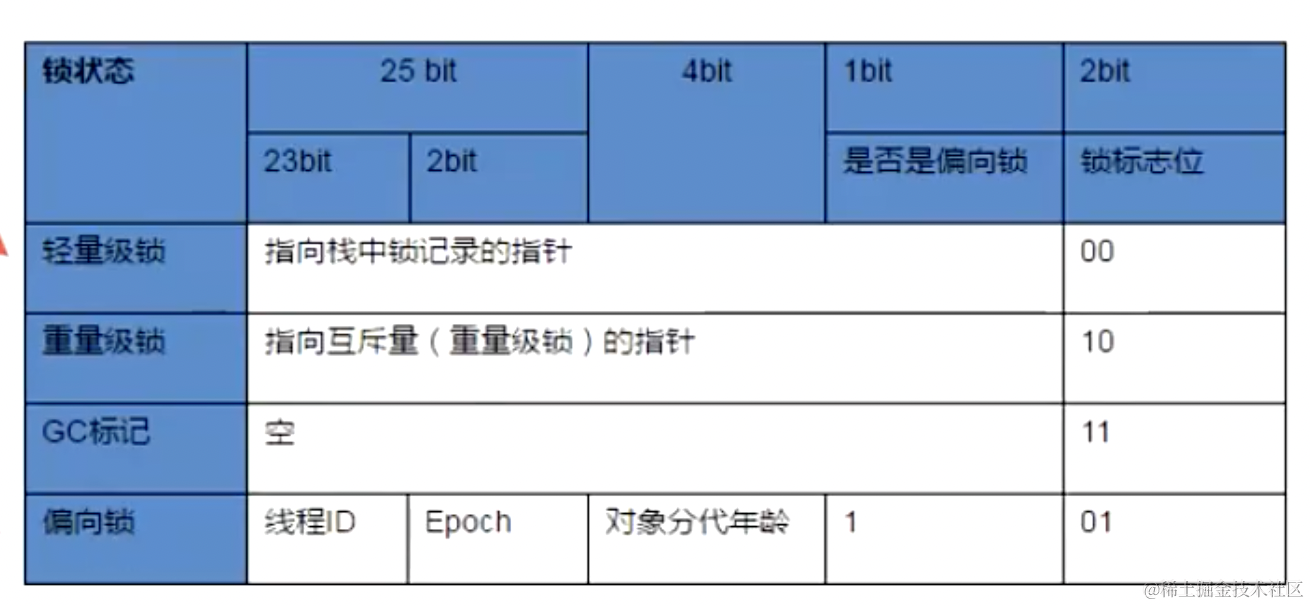
偏向锁的时候,对象头中存放了线程ID、时间戳(Epoch)、对象分代年龄、是否是偏向锁;
轻量级锁的时候,对象头中存放的内容就会变成指向栈中锁记录的指针;
重量级锁的时候,对象头中存放的内容就会变成指向互斥量的指针;
发生GC的时候,对象头中就是空的;
也就是说:对象头中的内容并不是一成不变的,而是随着对象的运行在不断的发生着变化;
从多个线程竞争同步资源的流程细节有没有区别 来看锁的类型有哪些?
因为 synchronized 加锁之后,其他线程是被阻塞在那里的,那么每个线程都会发生至少两次上下文切换(一次上下文切换耗费大概 3 - 5us,CAS基本原理中有介绍),Java 为了优化这块的耗时,就引入了 轻量级锁、重量级锁、偏向锁;
轻量级锁
通过CAS操作来加锁和解锁;也就是说:没有拿到锁的线程不挂起,而是在那里进行自旋操作,这样就不用发生上下文切换了;轻量级锁里面使用的就是自旋锁来实现;
假设加锁的代码块要执行很长时间,如果阻塞的线程一直在那里自旋操作的话,也是很大的消耗;于是虚拟机在自旋锁之上又引入了一个自适应自旋锁的概念,用来控制自旋的次数,早期的JDK版本是10次,在1.6的时候这个值不再是固定的10次,而是由虚拟机自行进行判定(一般来说就是一个线程上下文切换的时间);一旦超过这个时间就不再进行自旋,膨胀为重量级锁;
偏向锁
一般情况下,一个锁总是由同一个线程获取,如果连这个 CAS 操作都不想执行了,那就提前测试一下,当我拿锁的时候,测试下是不是当前线程自己,如果是当前线程自己,那就直接来用,这就是偏向锁;在线程拿锁的时候,总是偏向于拿到这个锁的第一个线程;相比于轻量级锁来说,它连CAS操作都不执行了;通过线程 ID 来测试是不是自己;
偏向锁一般用于没有竞争的时候,一旦发生了竞争,就需要升级为轻量级锁;
升级为轻量级锁,首先就要撤销偏向锁,那么对象头中的内容也要跟着发生变化,把偏向锁的数据撤销,替换成轻量级锁的数据;这种撤销替换的过程引入了一个 STW (Stop The World)
Stop The World
工作线程会不断的往堆里面产生对象,当堆中满的时候,需要把我们不用的一些对象进行回收,如果垃圾回收器在回收的过程中,还有工作线程不停的往堆中生产对象,这对于垃圾回收器来说是不友好的,这个时候就产生了 Stop The World
当垃圾回收器需要进行垃圾回收的时候,它就会划一条节点,当所有的工作线程运行到这个节点的时候,全部停止工作,当所有的线程停止工作后,垃圾回收器将堆中无用的对象清理掉,清理掉之后,再告诉所有的线程 继续执行;
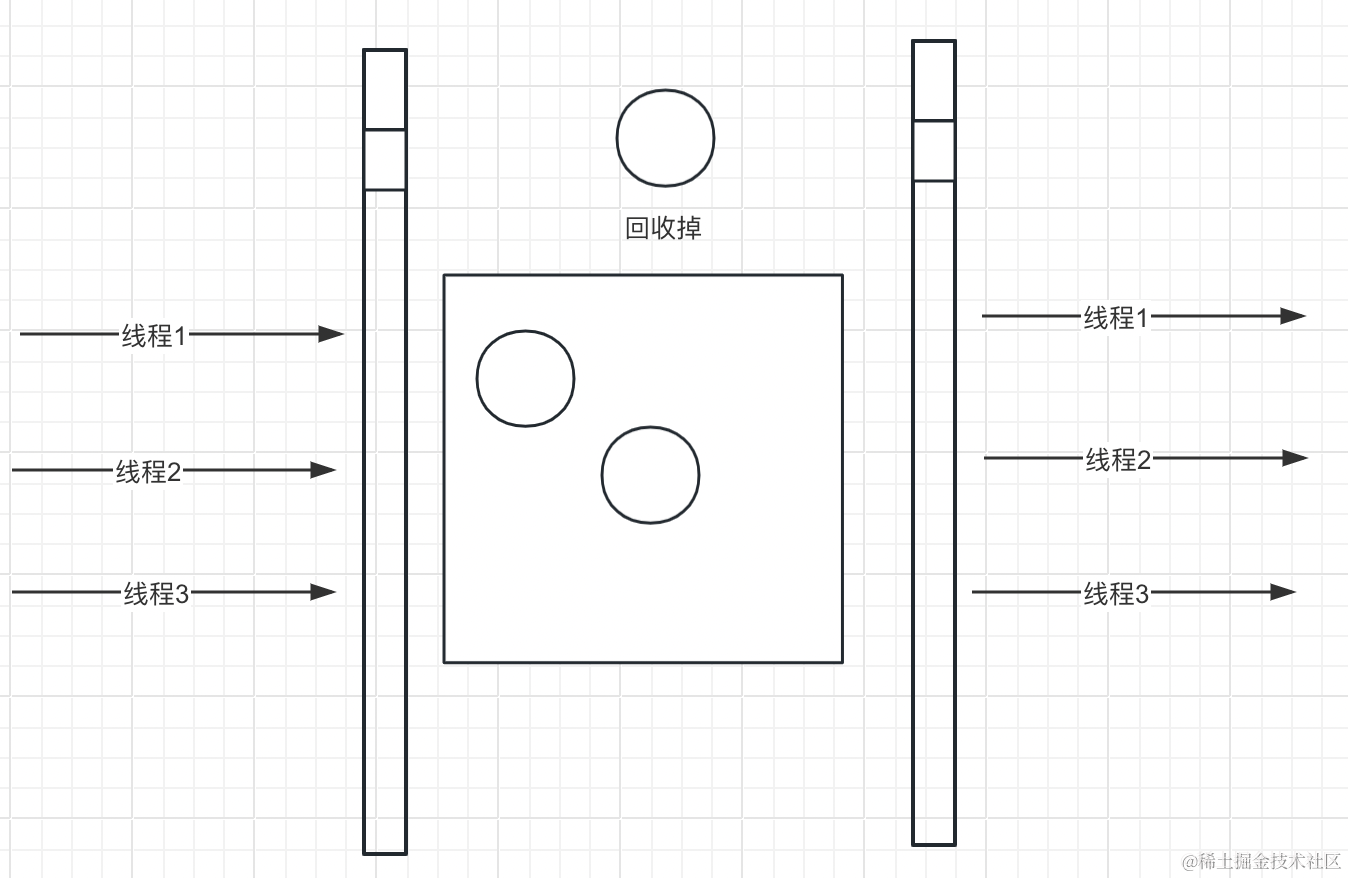
所有线程停止的现象,这就是 stop the world;
在撤销偏向锁的过程中,也存在这个 stop the world,当线程 B 去撤销线程 A 的偏向锁的时候,是会修改线程 A 的堆栈上的内容的,每个线程都有自己的工作内存,这个工作内存如果说硬要和虚拟机进行连接的话,这个工作内存就可以理解为虚拟机中的线程栈内存,每个线程的工作内存是不能相互访问的,但是对于虚拟机来讲,它是没有这个限制的,它就会让线程 B 去修改线程 A 中的相关数据,在这种情况下,如果线程 A 在不停的修改对象头内容,那么线程 B 是无法修改线程 A 的内容的,所以这里也引入 stop the world 概念,用来执行撤销操作;
所以在 synchronized 的优化过程中,jdk 给我们引入了偏向锁 -> 轻量级锁 -> 重量级锁;

Lock 和 synchronized 对比来说,如果你的需求没有尝试拿锁的话,尽可能的还是使用 synchronized,尽量少用显示锁;
简历润色
简历上可写:深度理解 synchronized 实现原理及优化过程,可基于不同的并发场景来高效使用锁机制;
下一章预告
文件IO,手写APK加固框架;
欢迎三连
来都来了,点个关注、点个赞吧~~你的支持是我最大的动力

















 506
506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









