



如果把计算机比作一座 24 小时不停工的智能工厂,CPU(中央处理器)就是工厂里的生产车间。
车间里有多条生产线协同作业,不管是打开文档、播放视频还是运行程序,所有任务都得靠这个车间的生产线处理,才能从需求变成屏幕上你能看到的结果。
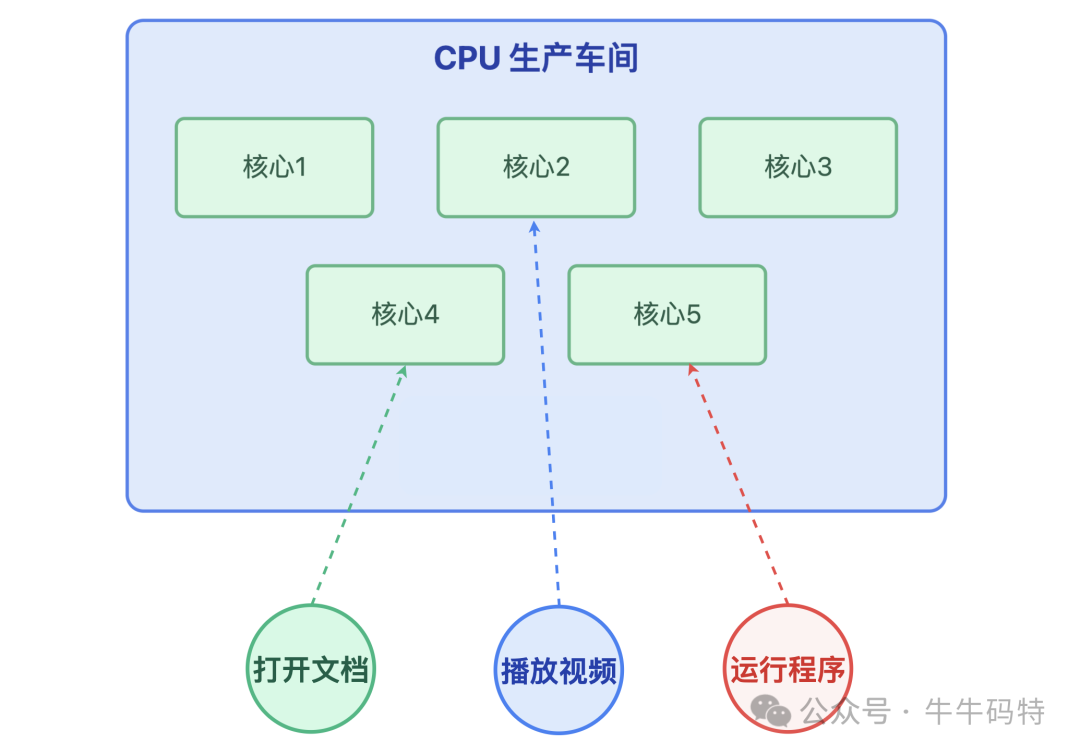
当然,生产车间的高效运转离不开经验丰富的调度员 — 也就是 CPU 调度器(CPU Scheduler)。要是没有它的合理安排,系统很快会陷入订单堆积、生产线空转、甚至瘫痪的混乱。在生活工作都离不开计算机的今天,系统瘫痪带来的影响是难以估量的。
因此,CPU 调度优化就成了保障系统稳定的关键。接下来,我们就一步步揭开 CPU 算力调度的 “突围密码”。
第一站:算力告急 — CPU "忙到宕机" 全过程
在一个普通的上午,当你同时打开浏览器、IDE、视频会议软件和后台下载工具时,电脑没一会儿就变得卡顿 — 鼠标指针变成转圈的 "风火轮",键盘输入延迟半秒才显示,甚至连音乐都开始断断续续。别着急,这不是电脑出了故障,而是 CPU 这个生产车间的使用率飙升到 100% 的 "超负荷预警"。
本质上,这是一场 "算力资源争夺战"。
每个程序都是急于被处理的订单,而 CPU 调度器就是工厂里的调度员,专门负责给车间里的生产线分配任务。当所有订单一股脑涌来,原本井然有序的生产流程瞬间被打乱 — 像键盘输入这样的 "加急订单",和后台下载工具校验这类 "常规订单" 挤在一块儿争抢 CPU 资源,最终导致 "工厂生产瘫痪"。
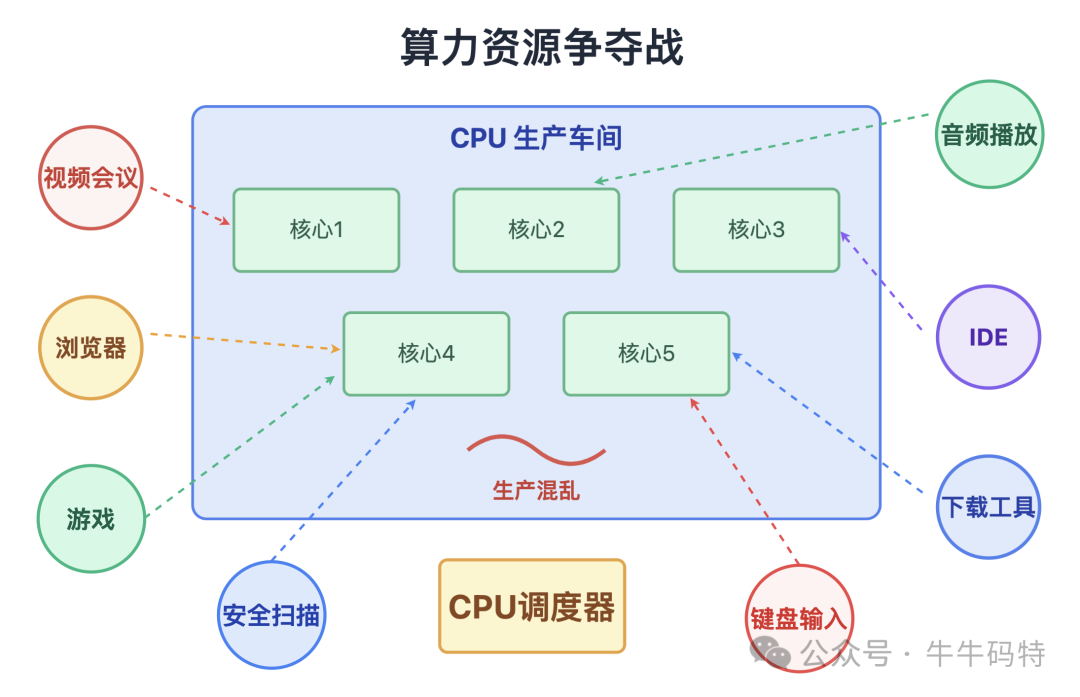
更隐蔽的是,有些程序还会搞违规操作,霸占车间里的生产线不放:
-
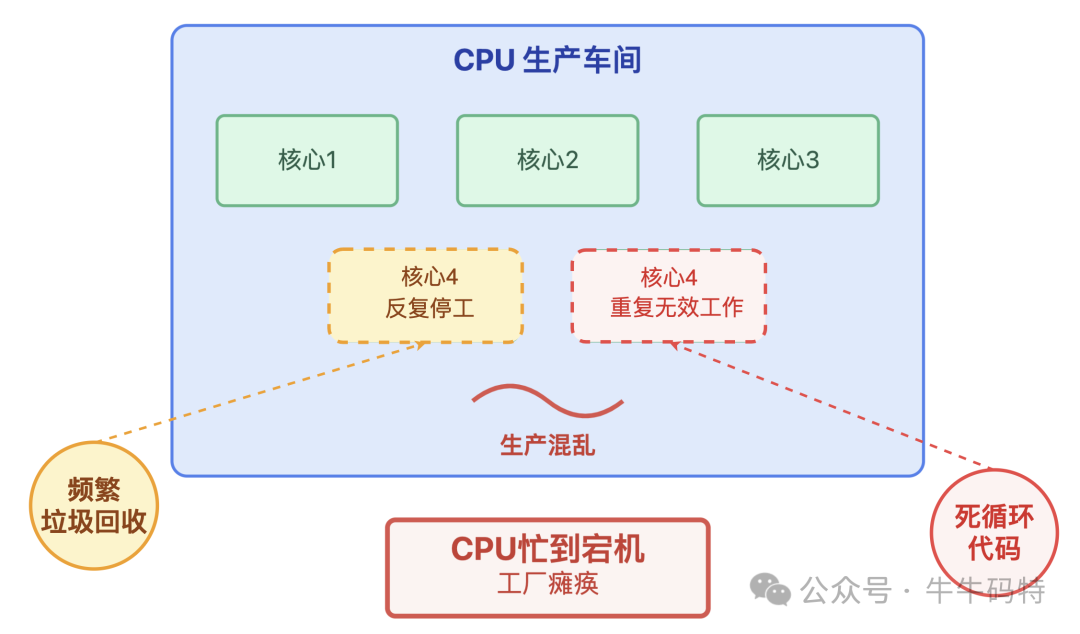
陷入死循环的代码导致车间里某条生产线被强制锁定,一直机械地重复无效工作,却始终不释放宝贵的算力资源;
-
频繁的垃圾回收(GC)则造成生产线在运行中反复停工整理物料,刚把任务推进一点就被打断,既影响效率又浪费资源。
这些行为让本就紧张的算力资源雪上加霜,最终让 CPU 这个生产车间彻底 "忙到宕机"。
看到 CPU 忙到宕机,你或许会疑惑:难道调度员就不管管这些混乱的生产线吗?其实,它一直在背后发挥作用。
第二站:调度员登场 — CPU调度器的核心使命
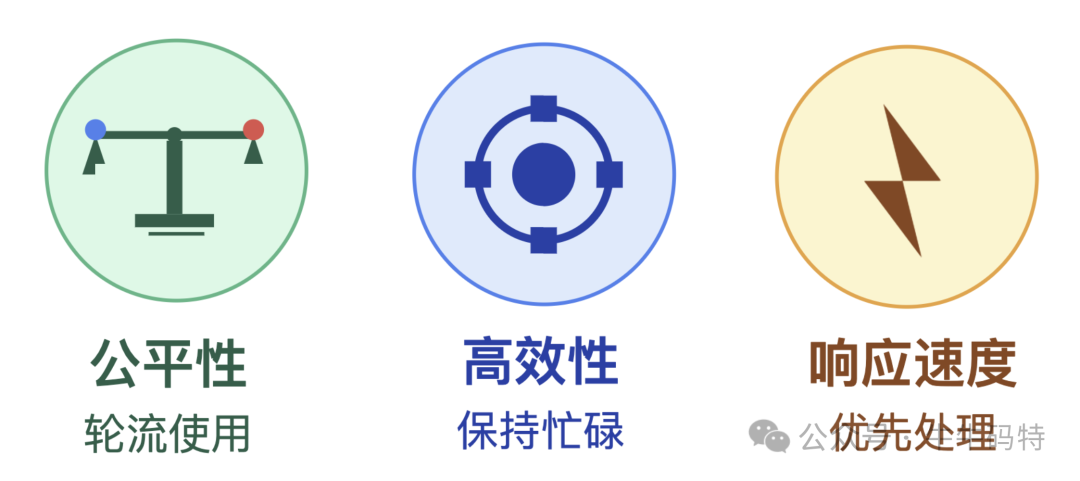
这位调度员的工作,说白了就是解决 “生产线不够用” 的难题。它每天的工作围绕三个核心目标展开:
-
公平性:调度器会确保每个任务都有机会使用 CPU 资源。比如后台默默运行的下载任务,不能一直抢占前台打字、点击操作所需的算力,得让各类任务按规则轮流使用 "生产线"。
-
高效性:调度员绝不会让生产线空转浪费,它会时刻盯着 CPU 的空闲状态,一旦有任务等待,就立刻安排资源,尽量让车间里的每条 “生产线” 都保持忙碌。
-
响应速度:面对用户点击按钮、键盘输入这类 “加急订单”,调度员会优先安排它们上生产线。而文档自动保存这种可以 “错峰处理” 的任务,就会被安排在你停笔的间隙,利用碎片时间完成。
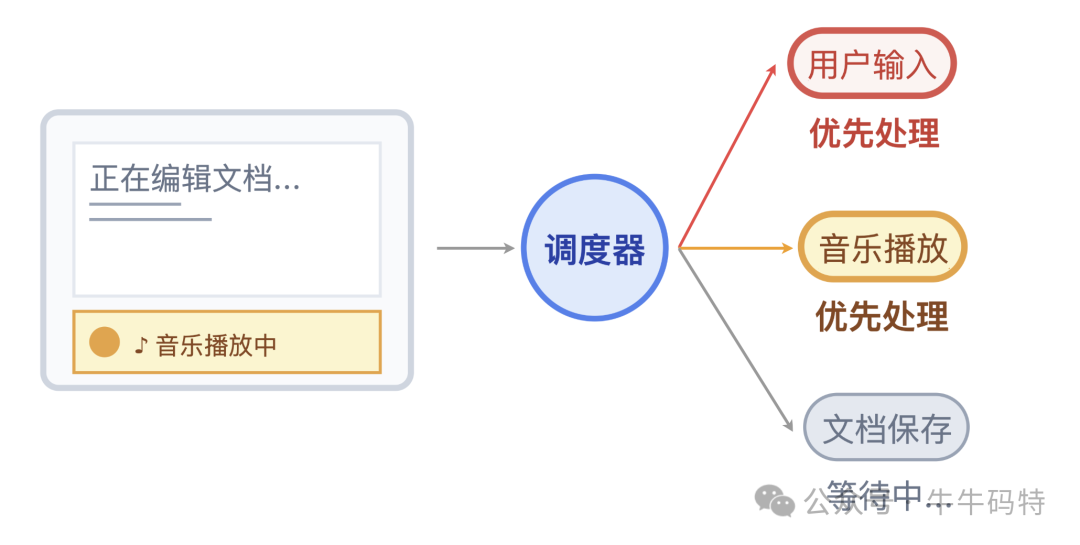
这种在各类任务间动态调配生产线资源的 “平衡术”,正是 CPU 调度器的精髓所在。但是有了调度器,CPU 为什么还是会陷入混乱?很简单,这就像交通系统里,即便有红绿灯和交警,早晚高峰照样可能堵成一锅粥。
第三站:调度员的 "失灵时刻" — CPU 100% 满负荷的真相
调度员失灵的症结在于:那些理想化的调度规则,总会被任务的 “违规操作” 和各种种 “突发状况” 打乱节奏,具体可归结为四类典型问题:
问题1:任务 "耍赖不放手" — 死循环和无限资源申请
调度员明明规定 “每个任务轮流用生产线”,但有些任务偏要“耍赖”。比如下面这段写漏了退出条件的代码:

这就像工厂里某个工人霸占生产线不换班,手里的活儿明明早该结束,却一直机械地重复无效操作。这时候,调度员制定的 “时间片轮转” 规则(即每个任务轮流使用 CPU,各自占用一段固定时间后就必须让出资源)完全失效 — 生产线被死死占着,其他任务只能在队列里干等,越积越多。
问题2:任务 "互不相让" — 锁竞争和资源死锁
调度员虽然能合理分配生产线资源,却管不了任务之间私下的 “资源争夺”。比如两个任务同时盯上了彼此需要的资源锁:
-
任务 A 要处理订单,先拿到了数据库连接的锁,可它接下来还需要读取某个配置文件,必须等任务 B 释放文件使用权的锁;
-
而任务 B 恰好相反,它先占用了文件的锁在做数据解析,后续步骤却需要访问数据库,必须等任务 A 释放数据库连接的锁。
就这样,任务 A 握着数据库连接的锁等文件,任务 B 攥着文件的锁等数据库,两个任务都停在原地动弹不得。
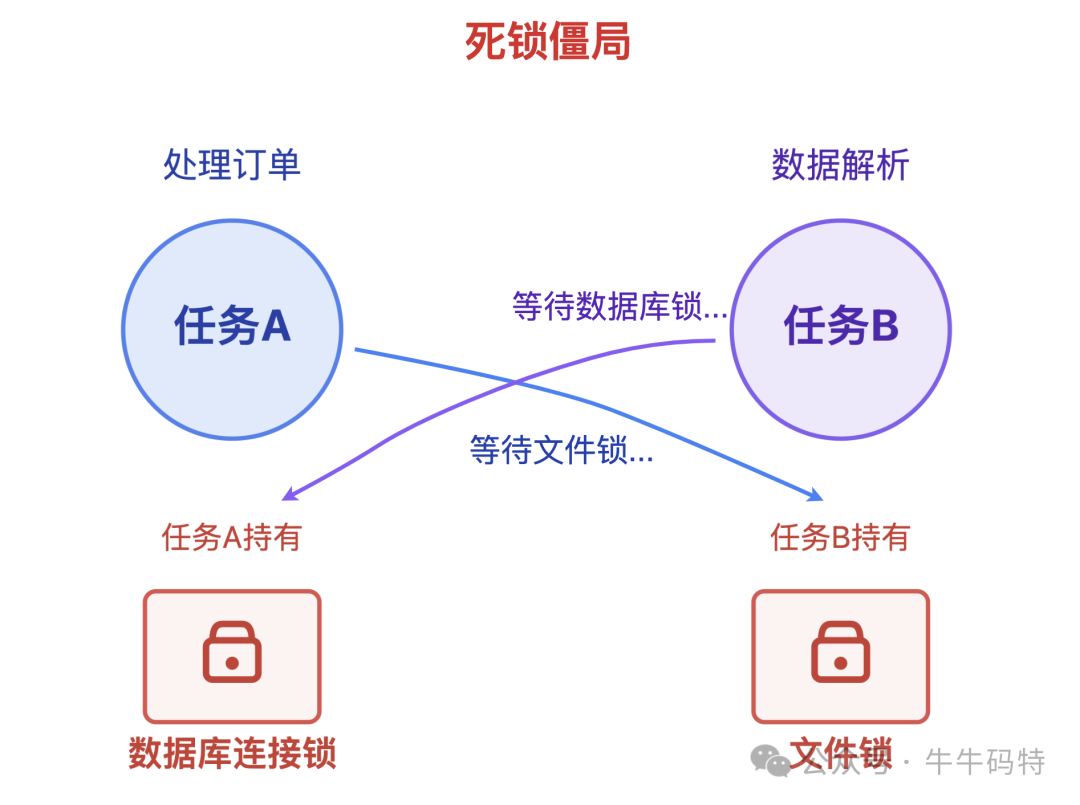
这就像两条生产线的工人,各自抱着对方完成工序必需的一半零件,谁都不肯先放手 — 调度员明明看到两条生产线都空转着,却没法强制它们各让一步,整个流程彻底卡在这儿,这就是典型的 “死锁僵局”。
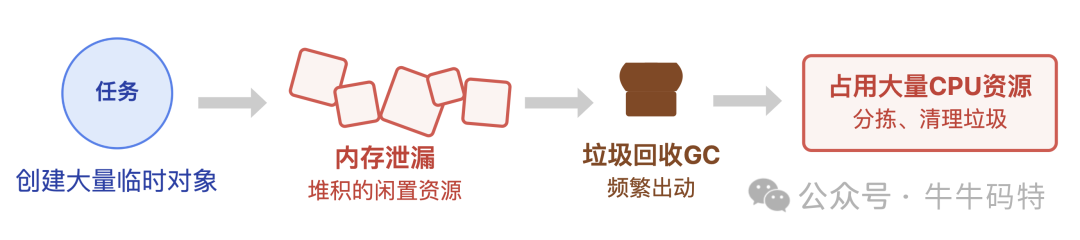
问题3:任务 "谎报需求" — 内存泄露引发的 "GC 风暴"
有些任务还会 “偷偷申请资源不还”:比如代码里创建了大量临时对象,用完后却没及时释放,这些堆积的 “闲置资源” 就是内存泄漏。这时,系统的垃圾回收机制就像工厂里的清理队,不得不频繁出动 — 而执行垃圾回收的 GC 线程会占用大量 CPU 资源来 “分拣、清理这些垃圾”。原本该正常推进的任务自然被越拖越慢,整个生产车间的效率也跟着大打折扣。
问题4:调度规则的 "盲区" — 优先级反转和上下文切换过载
除了上述因任务自身问题导致的调度失灵,有时候调度员制定的规则也会 “顾此失彼”,遇到束手无策的情况。下面这两类情况最为典型:
-
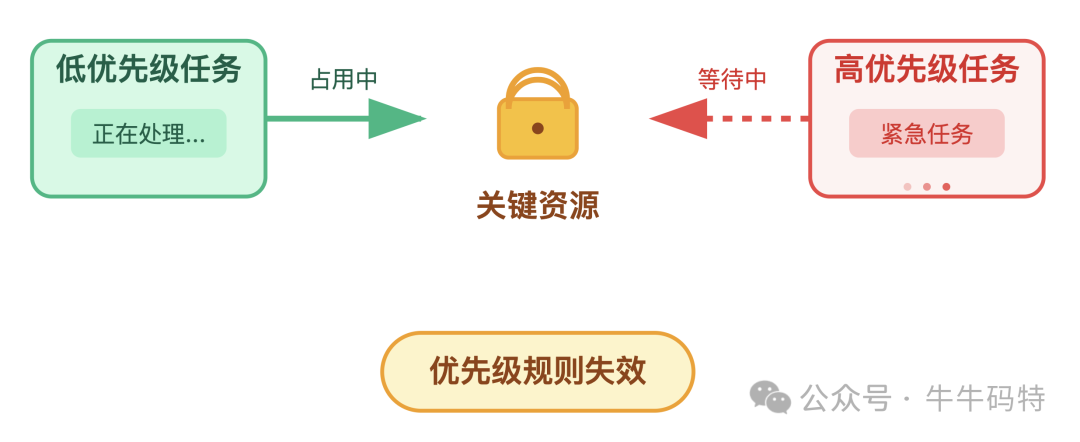
优先级反转:本应优先处理的高优先级任务,偏偏被低优先级任务 “卡住” — 因为低优先级任务先一步占用了关键资源,高优先级任务只能排在后面等着它释放。调度员定下的 “优先级规则” 在这一刻彻底失效。
-
上下文切换过载:如果同时运行的任务太多,比如上千个任务同时争抢资源,调度员就得频繁切换生产线 — 每次切换都要先保存当前任务的进度、再加载新任务的状态,这一系列操作就是 “上下文切换”。这就像工人刚在这条生产线熟悉了流程,还没干几分钟就被调到另一条线,结果花在 “搬工具、记步骤” 上的时间,比实际干活的时间还长,让整个调度的效率大打折扣。
总之,无论是任务 “耍赖”、线程 “互不相让”,还是规则存在 “盲区”,这些问题最终都会引发同一个后果 — CPU 不堪重负而 “罢工”。
因此,当故障发生时,如何快速定位根源就成了化解危机的关键。接下来就进入故障排查的实战环节,定位 CPU “罢工” 的真相。
第四站:故障排查 — 拆解 CPU "罢工" 的三步溯源技巧
此时我们需要像经验丰富的设备巡检员一样,沿着 “观察异常 → 精准检测 → 定位根源” 的路径快速行动,才能避免 CPU 长期超负荷拖垮整个业务流程。
第一步:看异常现象
排查故障的第一步,得先搞清楚异常到底是不是 CPU 引起的。就像工厂出问题时,要先排查是不是生产线本身出了状况,这里可以从业务和系统两个维度观察。
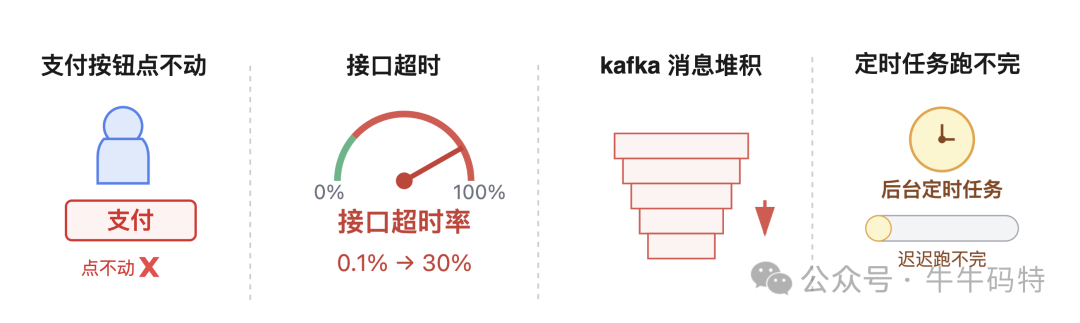
首先是业务侧异常,通常很直观。
比如用户反馈 “支付按钮点不动”,接口超时率从 0.1% 飙升到 30%;kafka 消息队列的消费滞后量达到 10 万条,像堆积的订单一样越积越多;后台定时任务也像赶工不及的订单,迟迟跑不完。这些现象都可能暗示 CPU 资源不足。
接着是系统侧异常,需要通过命令工具 top 和 vmstat 查看。
top 命令是 Linux 系统里的实时进程监控工具,能直接看到 CPU 的负载和进程占用情况。操作和输出示例如下:
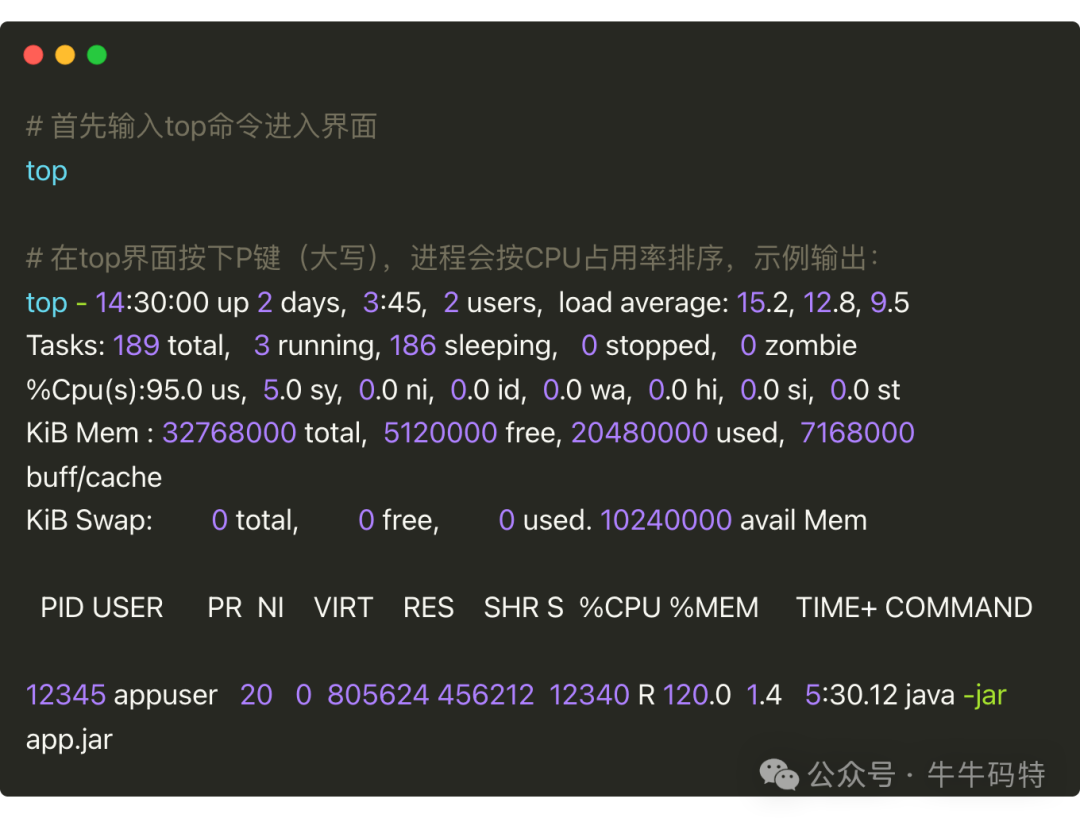
我们重点关注 % Cpu (s) 行、load average 这几个指标:
-
%Cpu(s)行:us(用户进程占用)95% +sy(系统进程占用)5% = 100%,且id(空闲率)为 0,说明 CPU 已被完全占满,没有余力处理新任务; -
load average: 15.2表示 1 分钟内系统平均负载为 15.2,对于 8 核 CPU 来说,意味着除了正在运行的 8 个任务,还有 7 个在排队等 CPU,任务量已超过处理能力; -
进程列表:Java 进程(PID=12345)的
%CPU达到 120%,远超单个核心的承载力,说明它对应的代码可能存在死循环、频繁计算等高耗 CPU 逻辑,是导致过载的主要原因。
vmstat 命令则专注于系统整体状态的报告,像虚拟内存、进程活动、CPU 运行情况等信息都能通过它获取。操作和输出示例如下:
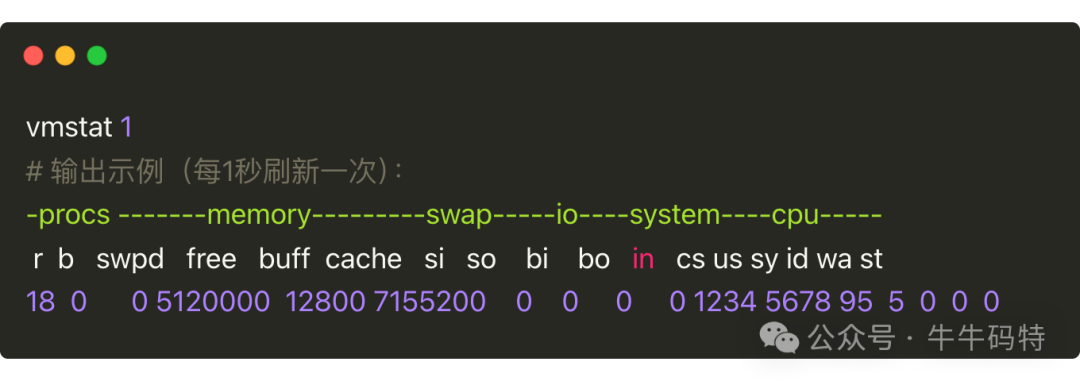
我们重点看 r 列(等待运行的任务数)。上述示例中 r 列数值为 18,对于 8 核 CPU 来说,明显超过核心数的 2 倍,说明 CPU 已超负荷。
第二步:找到 "问题线程"
确定是 CPU 的问题后,接下来要做的就是从高耗资源的进程里,精准揪出 “闹事” 的线程。具体可以按这两步操作:
首先,定位进程内的高耗线程。
用 top -Hp [进程PID]命令,就能查看指定进程内部所有线程的资源占用情况。比如之前通过第一步发现高耗 CPU 进程 PID=12345,示例命令和输出如下:
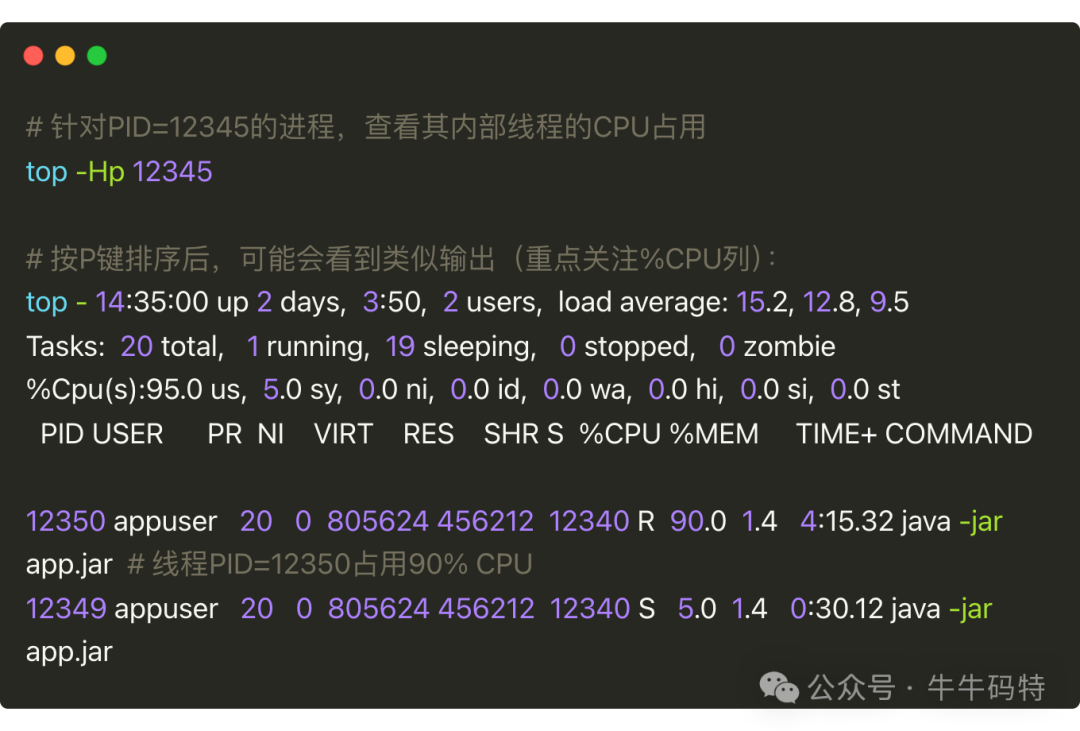
从输出能看到,线程 PID=12350 的 CPU 占用率高达 90%,显然是主要 “肇事者”,记下这个线程 PID。
接着,查看线程的 “运行现场”。
需要先把线程 PID 转换成 16 进制,比如 12350 转换后是 0x4f6a,用printf "%x\n" 12350 命令就能快速转换。
以 Java 进程为例,我们可以用 jstack 工具导出进程的线程栈信息,这个工具能帮助分析线程状态和调用关系,示例命令及输出如下:
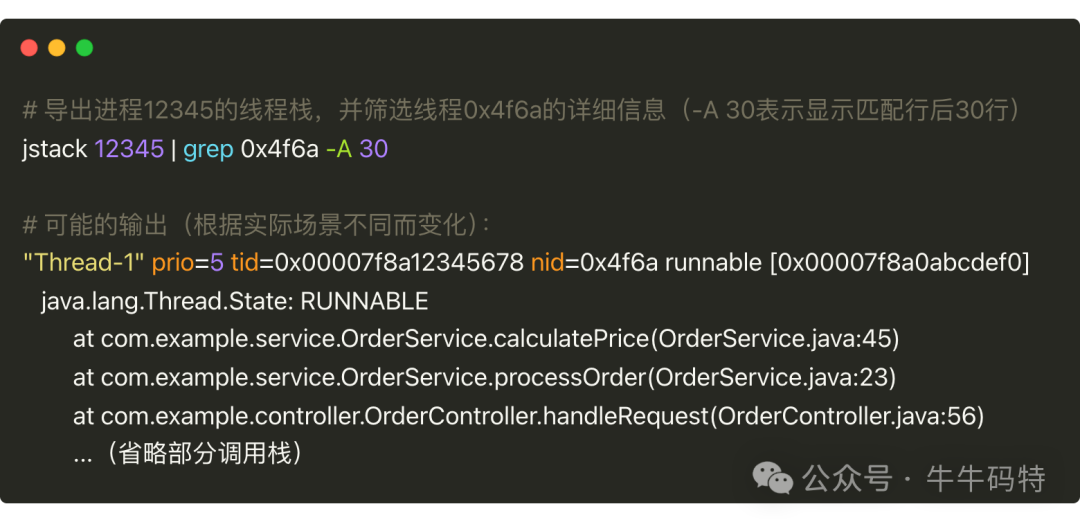
从调用栈就能快速判断问题类型:
-
线程死循环:通常表现为线程在某个方法内无限循环且无退出条件;
-
线程阻塞:日志中常会出现
waiting for monitor entry字样,说明线程在争抢资源锁; -
GC 风暴:表现为
GC task thread#0 (ParallelGC) 等GC 线程活跃,频繁的垃圾回收导致 CPU 占用过高。

第三步:从线程栈追溯到代码逻辑
找到问题线程后,还要像拆解工序流程一样,顺着线程调用栈深挖代码逻辑,弄清到底是什么让 CPU“卡壳”。常见的三种情况可以这样验证:
首先是死循环的验证。从线程栈中定位到具体的代码位置后,直接查看对应逻辑,即可判断是否存在无限循环或无退出条件的情况。
接着是锁竞争的验证。可以用监控工具查看锁的竞争情况,比如发现有大量线程都阻塞在同一个加锁的方法上,而持有锁的线程又长时间不释放,大概率是锁的设计出了问题。
最后是 GC 风暴验证。若线程栈显示 GC task thread 频繁活动,这种情况可以分两步定位:
先用 jstat 监控垃圾回收频率,示例命令和输出如下:
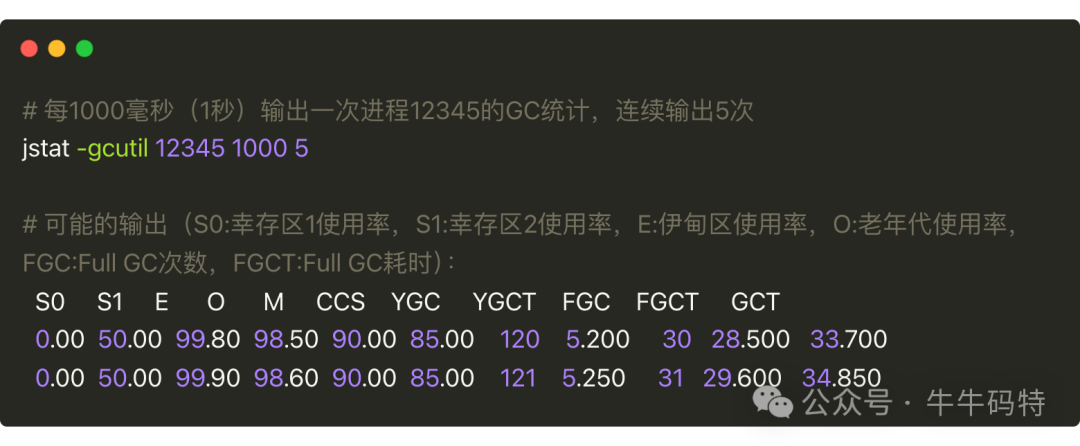
以上输出,我们重点关注 FGC(全量垃圾回收总次数)和 FGCT(全量 GC 总耗时,单位:秒)两个指标,输出显示 1 秒内 FGC 从 30 增至 31,FGCT 从 28.500 增至 29.600,即每秒 1 次全量 GC 且单次耗时近 1 秒,属于典型 GC 风暴。
再用 jmap 查看对象分布,确认是否有内存泄漏,示例命令和输出如下:
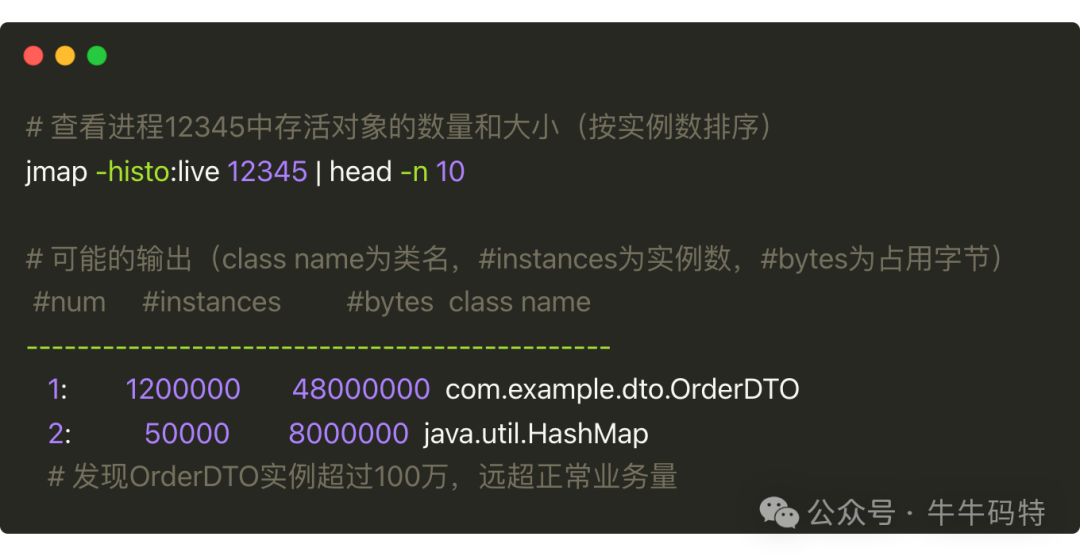
以上输出显示 OrderDTO 实例超过 100 万,远超正常业务量,这说明 OrderDTO 对象未被及时回收,导致内存堆积触发频繁 Full GC,进而占用大量 CPU。
通过这三步,我们锁定了 CPU “罢工” 的根源。但找到问题只是第一步,更关键的是如何快速化解危机、避免业务持续受损。接下来,我们就进入实战修复环节,看看如何给罢工的 CPU 实施 “急救”。
第五站:算力突围 — 化解 CPU "罢工危机" 的修复指南
CPU “罢工” 的处理思路就像工厂应对生产线故障一样,得先稳住局面再彻底解决问题。具体分两步走,第一步是临时止损,核心是快速恢复业务;第二步是长期修复,重点是避免重复故障。
第一步:临时止损 — 5 分钟内让 CPU "喘口气"
当故障已经影响到正常业务时,先做简单有效的操作稳住局面。核心是先保业务不停摆,具体可以从两方面入手:
1. 给 “故障工序” 紧急停机
如果确定是某个特定进程在持续捣乱,比如陷入死循环的 Java 进程,建议先保存线程日志方便后续复盘,再强制终止进程并重启服务,CPU 使用率会瞬间下降。具体可以这样做:
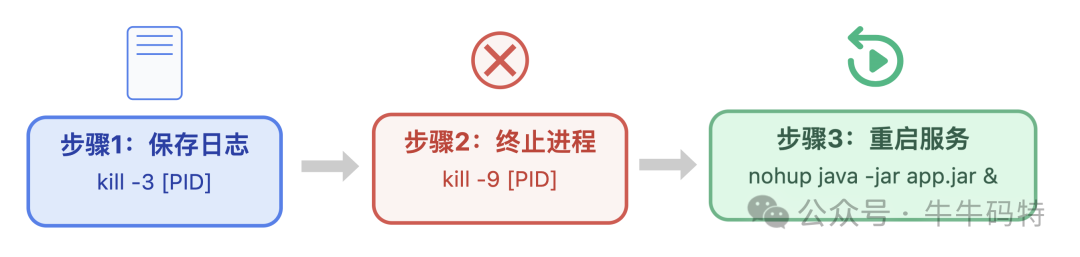
-
先通过
kill -3 [进程PID]命令保存线程日志 -
再用
kill -9 [进程PID]强制终止故障进程 -
最后重启服务,以 Java 服务为例,可执行
nohup java -jar app.jar &来重启。
2. 给 “核心订单” 开绿色通道
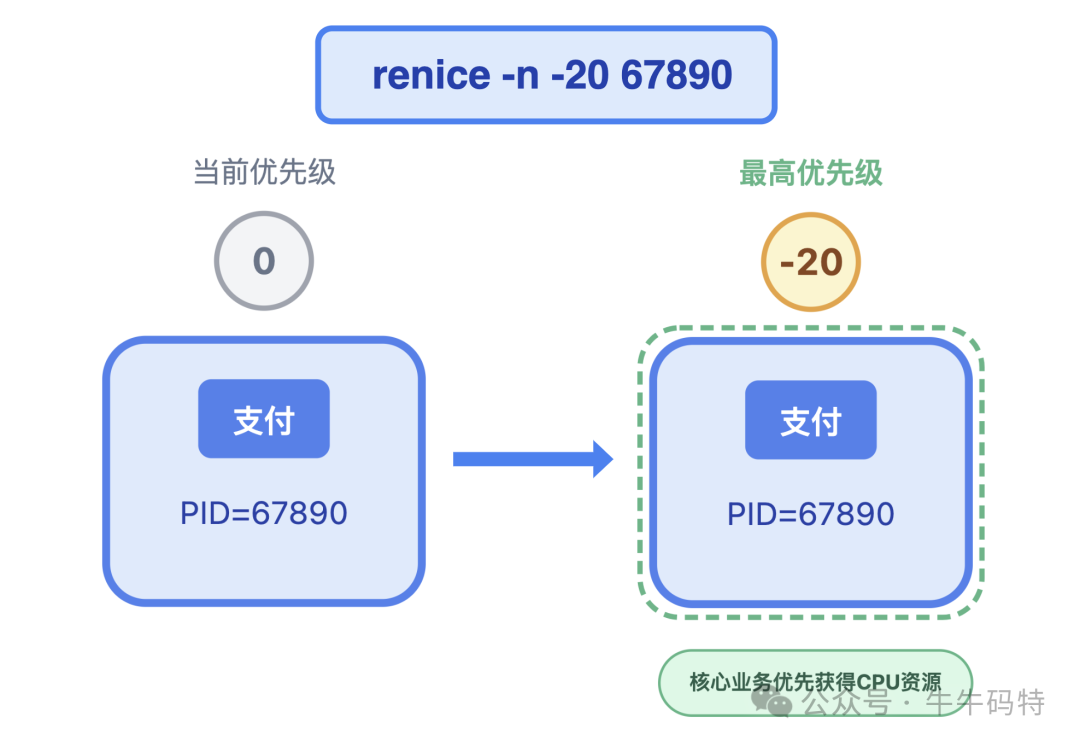
可以用 renice 命令提升核心业务进程的优先级,数值越小优先级越高,最高为-20。比如给支付、登录这类关键进程提升优先级,假设进程 PID=67890,操作示例为 renice -n -20 67890,它们就能优先获得 CPU 资源,保障核心业务不中断。
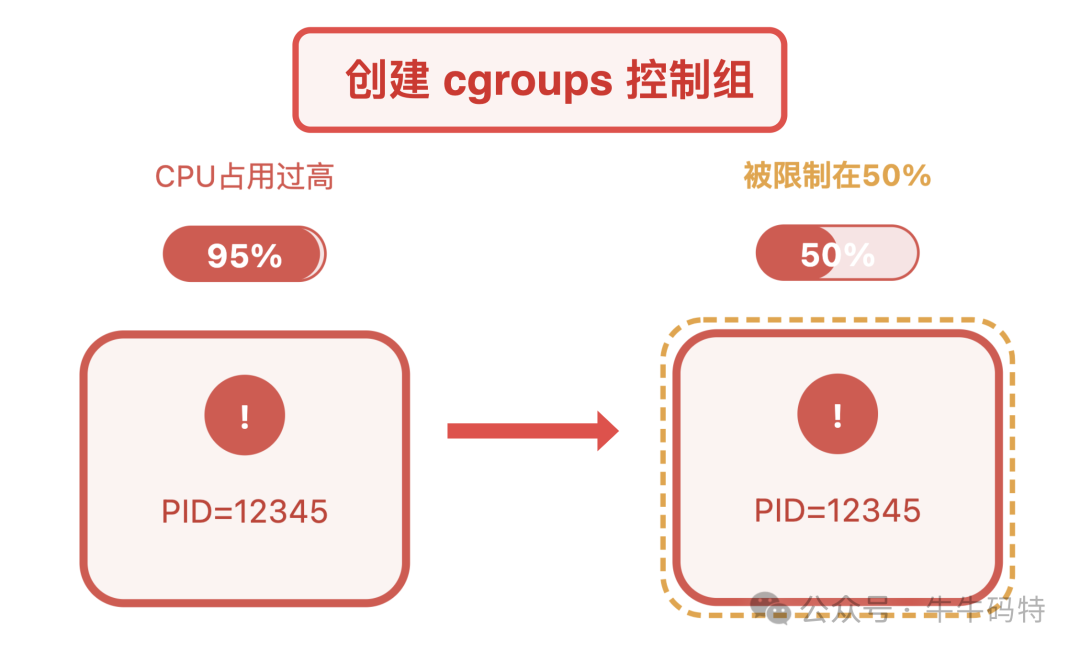
此外,还能用内核级资源管控工具 cgroups 给问题进程设置 “资源上限”,避免它抢占过多 CPU。比如先创建一个名为cpu_limit的控制组,限制其 CPU 使用率不超过 50%,再将问题进程加入该组,比如进程 PID=12345,就能有效遏制资源滥用。
第二步:长期修复 —从代码到架构的改造
要彻底解决 CPU “罢工” 问题,不能只依赖临时止损,更需要从代码逻辑到架构设计进行系统性改造,具体可以针对不同的问题场景,采取不同的优化方案:
1. 针对死循环代码:加“超时闹钟”
如果代码中存在死循环逻辑,可以加入时间限制,使其到点必须停下当前操作,避免无限占用资源。

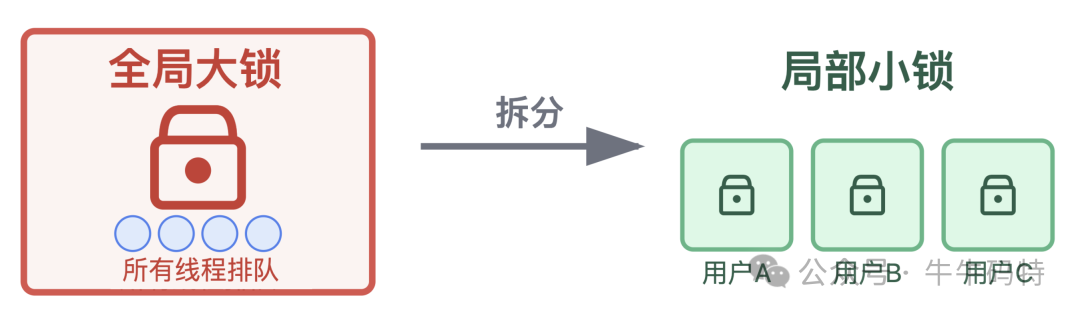
2. 针对锁竞争:把“全局大锁”拆成“局部小锁”
原来用一把全局锁让所有线程排队,就像一条生产线只能一个人用,效率极低。可以按业务场景拆分锁,比如按用户 ID 分片设计多把锁,让不同用户的操作使用不同的锁,减少线程争抢;或者用无锁工具替代传统锁机制,从源头降低竞争频率,让线程协作更高效。
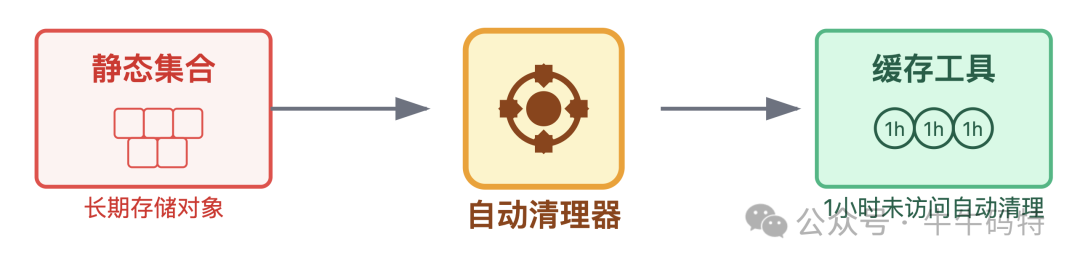
3. 针对GC风暴:给内存装 "自动清理器"
避免用静态集合长期存储对象,可以用带过期机制的缓存工具,给对象设置存活时间,例如 1 小时未访问就自动清理,并限制最大缓存数量,防止对象堆积。同时,上线前要定期检测内存中对象的分布情况,提前发现并修复内存泄漏风险,从根本上减少频繁 GC 对 CPU 的消耗。
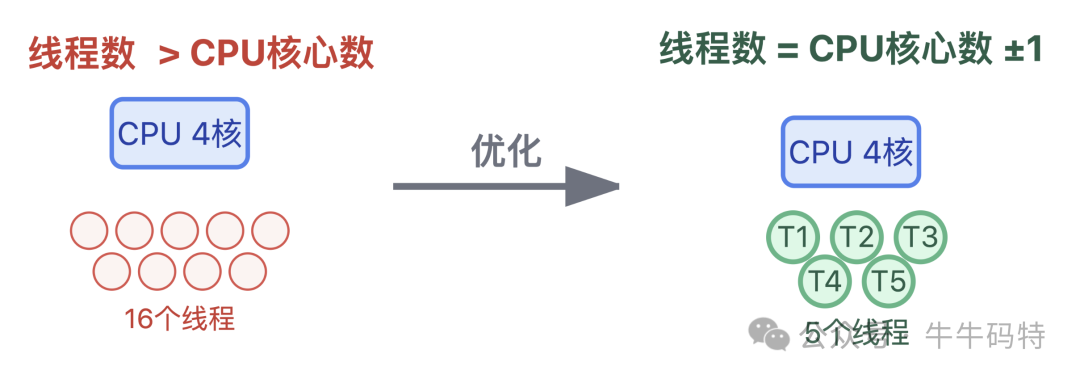
4. 针对上下文切换过载:控制 "同时开工的工序数量"
如果线程池的线程数远超 CPU 核心数,就像工厂同时开太多生产线却没足够工人,反而导致频繁换岗、效率低下。合理的做法是按 CPU 核心数动态设置线程数,通常为核心数 ±1,这样能避免线程过多引发的频繁切换,让每个线程都能专注处理任务,减少资源内耗。
通过这样的长期优化,既能彻底解决当下的 CPU 危机,又能从根源上优化算力分配,让系统像高效运转的 “智能工厂” 一样,始终保持高效运转。
结语:CPU 调度的终极思维
说到底,CPU 100% 使用率的危机,并非调度员 "失职",而是任务复杂性超出了规则的容错能力。真正的算力调度,不应是告警后才进行应急抢救,而应通过 “监控预警 + 代码规范 + 压测验证” 构建三道防线:
-
监控预警:配置 CPU 使用率 80% 预警,提前 5 分钟发现异常;设置线程阻塞数 > 5 告警,及时介入锁竞争。
-
代码规范:循环需加超时限制,锁必须注释粒度,大对象要设过期时间。
-
压测验证:上线前用 JMeter 模拟 10 倍流量,确保 CPU 使用率 < 70%,留足缓冲空间。
算力调度如同城市交通治理,最好的方式不是堵车后疏导,而是规划时避免堵点。掌握这套防患于未然的思维,才能从业务 "救火队长" 转变为算力 "调度大师"。


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









