




 Redis作为一款基于内存的数据库,以其高速读写能力在大数据时代受到广泛关注。本文详细介绍了Redis的设计理念,包括其如何克服硬件局限性,实现高效数据存储与访问。此外,还探讨了Redis在不同场景下的应用,如缓存、消息队列等,并对比了其与memcache的区别。
Redis作为一款基于内存的数据库,以其高速读写能力在大数据时代受到广泛关注。本文详细介绍了Redis的设计理念,包括其如何克服硬件局限性,实现高效数据存储与访问。此外,还探讨了Redis在不同场景下的应用,如缓存、消息队列等,并对比了其与memcache的区别。
Redis号称是最快的key-value的基于内存的数据库,近年来,各大公司的招聘、面试都会问到Redis,可以说热度极高,接下来我将会分享一些我学习Redis的笔记,希望能够给予到大家一定的帮助。
我们首先明白一个概念,Redis的设计原则就是快,因此会舍弃一些其他的东西。
数据的存储变化
一开始,我们直接将数据存在磁盘当中,但随着数据量的逐渐增大,数据的访问效率逐步的降低,后来,出现了关系型数据库,使得数据的存取效率有了极大的提升,但随着大数据时代的来临和越来越高的并发,关系型数据库也到了一定的瓶颈,此时人们提出了一种内存级的数据库,所有数据保存在内存中,但这种数据库对机器的性能要求极高,造价也极高,所以不能够得到普及,基于这种情况,人们结合这两种数据库的特点,提出了缓存型数据库,也就是我们今天的主角Redis。
硬件的局限性
对于数据的存储访问在硬件层面有两处局限性
-
寻址速度
磁盘中有磁道、扇区(512Byte),如果以一个个的扇区为基本点的话,要想在一块磁盘中找到对应的数据,寻址时间会极长,为了减少寻址时间,人们将磁盘划分为一个个4k大小的格子(格式化),以4k为基本数据单元,这极大的提高了寻址速度,但随着磁盘越来越大,我们不可能为了提升寻址速度,将基本单元变的很大,所以寻址的速度依然成为数据访问的一个局限性。数据库相比于直接磁盘存储是因为其有着索引,根据索引能够快速的定位到磁盘中的数据,相当于提升了寻址的速度,因此数据库的速度才会比直接磁盘快。
-
带宽
无论是内存还是磁盘都有着一定的带宽,一次能传输的数据有限。随着越来越高的并发,磁盘的带宽成为数据库速度的一个局限点。
Redis
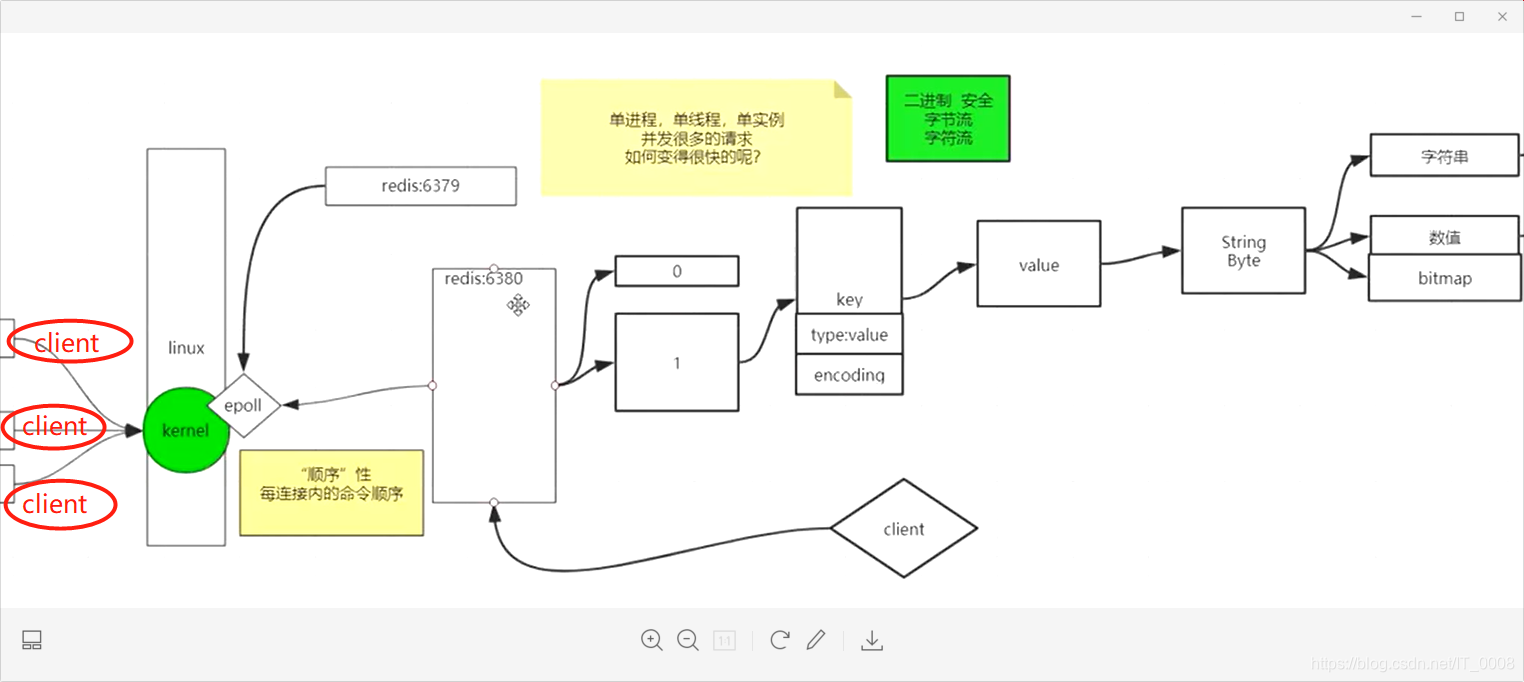
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动分区(Cluster)提供高可用性(high availability)。
-
Redis是key-value模型的数据库。
-
对于客户端的请求Redis使用单线程来处理(这里说的单线程并不是说Redis只有一个线程,而是说Redis只用一个线程来处理请求,它还有其他的线程),单线程保证了在每个连接内请求命令的顺序性,但它的单线程效率并不低,每秒可以接受七八万甚至十万的并发,它之所以可以处理这个高的并发与它采用的IO方式有关,它用的是epoll这种NIO的IO模式。.
-
在一台服务器上我们可以创建多个Redis的实例,各自独立,用不同的端口号区分。
-
一个Redis实例默认有16个库0-15号,每个库都具有自己的独立性,互不影响。
-
每个库里数据以key-value的形式存储,Redis支持5种数据类型,不同的类型有不同的方法来对数据进行操作;在Redis中操作是分组的,不同的组里有着不同的操作,这里说的5中数据类型也划分在不同的组,可以说Redis的一大特色就是支持对数据的不同操作(计算向数据移动),这里说的操作就是在不同的组划分下,Redis会提供各种各样的方法来对数据进行不一样的处理,对数据进行加工。举个例子,对于常用的String类型,Redis支持常见的字符串的查找(get、getrange)、追加(append)、替换(setrange)等操作;支持数值的运算操作(incr、incrby、decr、decrby);支持bitmap操作(bitset、bitcount、bitpos、bitop)。
-
Redis的key是一个对象,它有着许多的属性,记录着key和它所对应的value的一些信息。
-
Redis是二进制安全的,它是面向字节流的IO(存储的数据是字节数组),只要保证各客户端使用统一的编码格式(有统一的编码,就会生成统一的字节),那么它的数据就不会出现乱码,我们称这种为二进制安全。
插个小知识:ASCII是标准的编码,其他任何的编码都是拓展编码,对于任何的机器,都能直接识别ASCII这标准编码,在机器中做字节转换时,对于ASCII的编码机器可直接识别,直接翻译为对应的数据,不是ASCII的编码格式的字节码,机器会去寻找设置好的编码格式来做解析
不同类型的操作
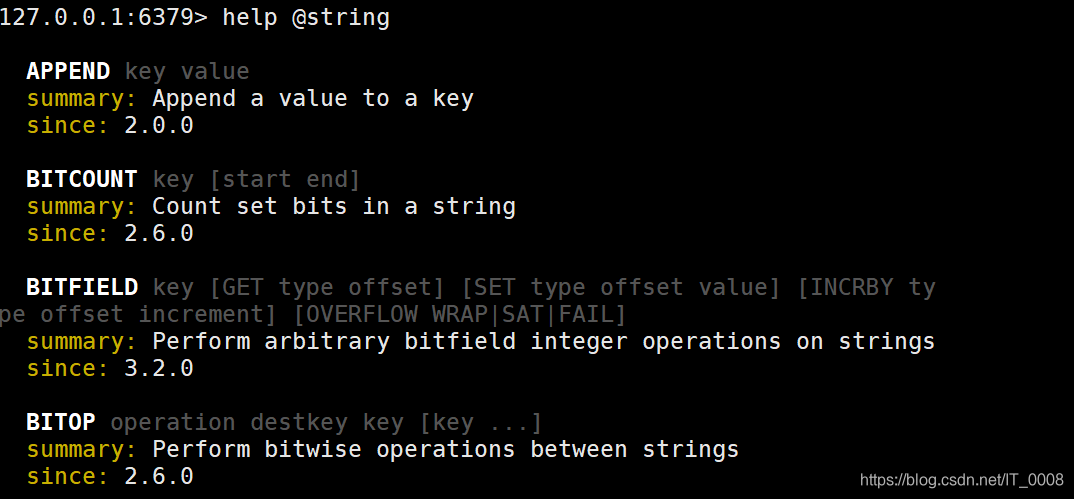
对于Redis客户端,我们可以借助help命令来学习不同的操作。

- 通过help @具体的组名 可以查看对应组下的操作
- help @ +tab键可切换不同的组
- help 具体的命令 可查看具体命令说明
String操作
对于String有常用的三类操作,字符串的操作、数值的操作和bitmap的操作。
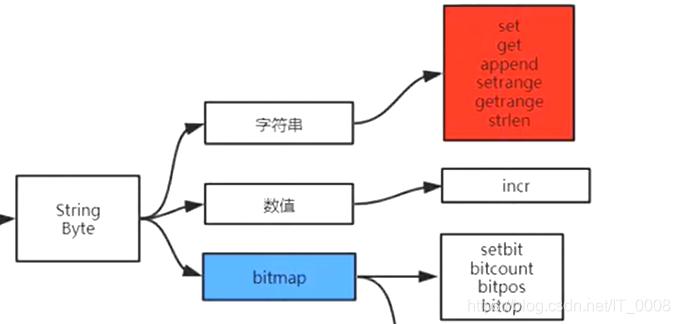
字符串和数值的操作比较容易理解,下面我简单介绍下bitmap(位图)的一些操作(位运算的一些相关操作),Redis是按照字节来存储数据的,key对应的value值由一个个的字节组成,每个字节都有着正负索引,正序从0开始,每个字节逐个递增(第一个字节为0),逆序从-1开始,逐个递减(最后一个字节为-1);字节有索引,每个字节中的位也有索引,从0开始;举个例子:
set k1 abcdef; Redis中存储的一个键值对 key:k1 value: abcdef
由6个字节组成(每个字节有编号,编号为0-5,对于逆序的话,最后一个字节为-1,依次往前递减)或者说由48个二进制位组成(位也有编号,位
的编号为从0到47)
-
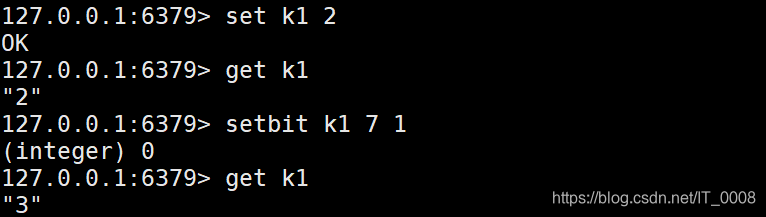
setbit 给指定的位设置0或1

-
getbit 获取指定位置的二进制值
-
bitcount 计算给定key对应的二进制value值中从第start字节开始到end字节中出现的1的个数

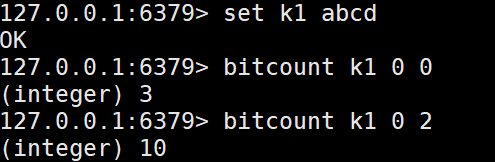
-
bitpos 找出指定string中某个值第一次出现的位置

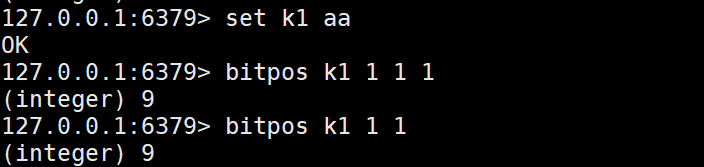
-
bitop 两个值进行位运算 and or xor not


bitmap的使用场景

list操作
redis的list是一个双向链表,key记录着头指针和尾指针,同时节点也有着索引编号,模型如下图。

list中的操作根据命令的组合,可以形成如栈、队列、数组、阻塞队列的效果。

- 同向命令如栈 lpush左边插入和lpop弹出组合形成后进先出
- 反向命令如队列lpush左边插入rpop弹出组合形成先进先出
- lindex命令可以如数组般操作链表

- blpop等以b开头的命令可形成阻塞

hash操作
hash类型的value里是一个个的键值对,一个key对应的值中可以有多个key-value键值对,同时hash中存储的键值对也可以计算。hash类型的使用场景可以是:某一个东西,它有不同的属性,我们可以记录在hash中,如微博中个人信息的记录、商品详情页中信息的记录等,它有点类似于关系型数据库表中的一行记录。

set操作
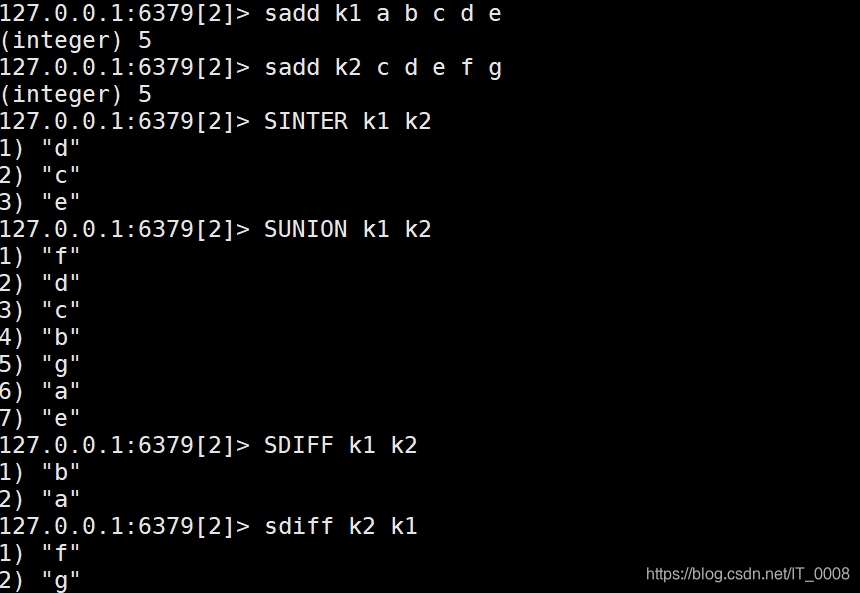
set类型的操作根据其无序不可重复集合的特点可分为两大类:集合的交、并、差操作和随机事件操作。
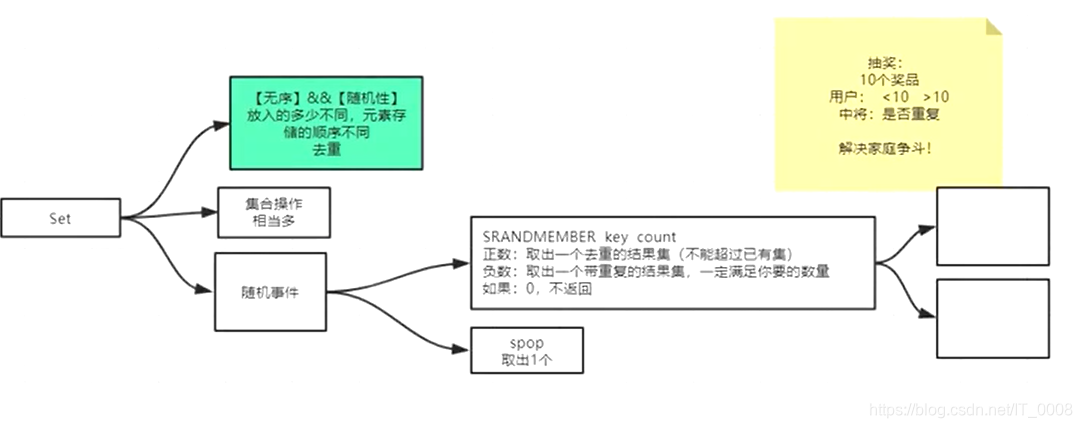
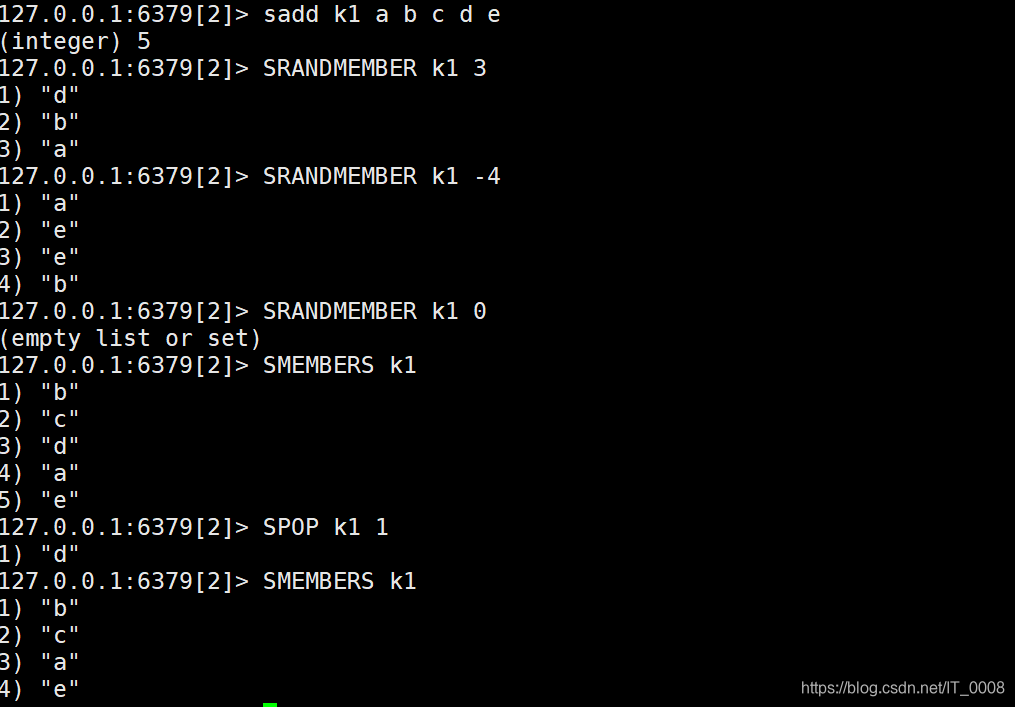
- 随机事件操作 srandmember key 正数、负数、0,正数返回不重复的 不超过集合中元素个数的 已有集合中的元素,负数返回重复的 满足要求数量的 已有集合的元素,0 不返回元素。
- 集合间的操作 交 并 差,差集key的先后顺序不同,返回结果不同。
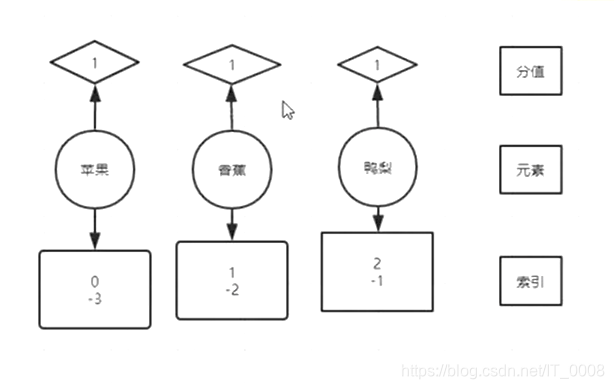
sortedset操作
sortedset是一个有序的不可重复集合,它的主要操作包含集合间的交并差操作和有关顺序的操作,它的排序底层由跳表完成。

- 有序那么就包含了正负索引。
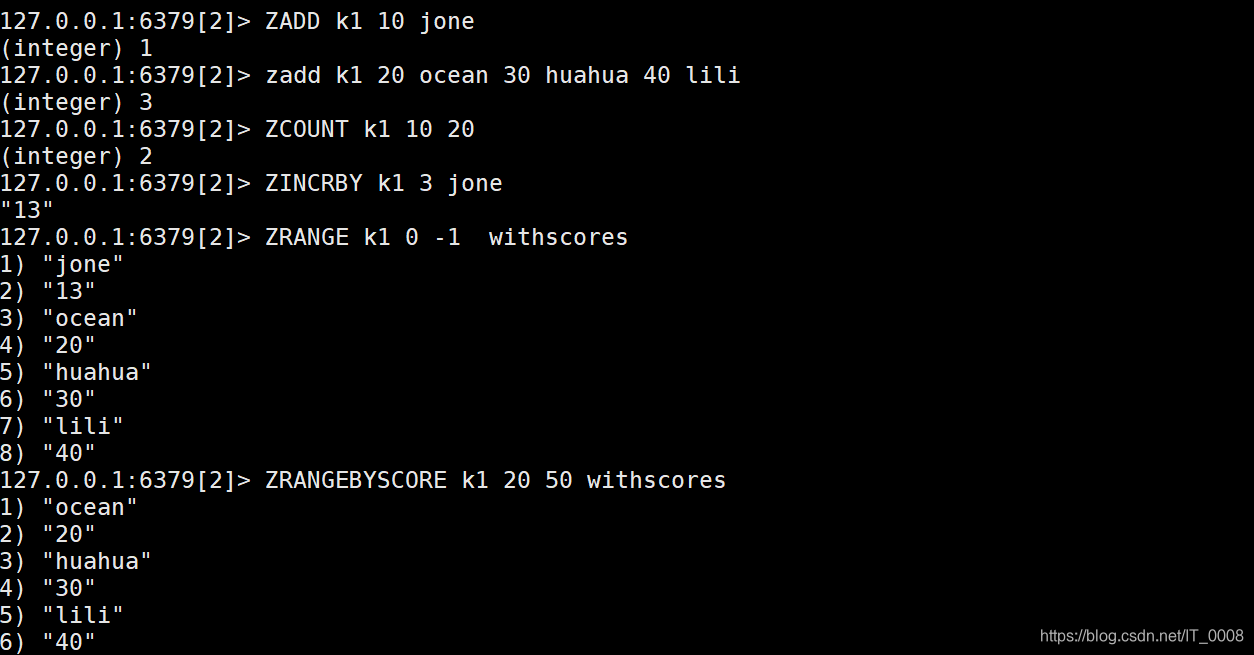
- 要排序那就得有排序的规则,因此它的元素中有个属性score,它的操作命令也就比其他类型的多一项,根据分值的操作,同时元素也支持数值运算。
- 计算顺序相关操作 操作分正向和反向 反向操作一般形如zrev… 会带有rev

Redis与memcache
二者相似,最大的区别是Redis中对每种数据类型都有自己的方法,当一个请求到来时,Redis会取到数据做处理,将满足的数据返回到客户端,而memcache则是会将数据的处理过程交给客户端。造成的结果就是,使用Redis,IO效率和传输效率都较高。

Redis学习参考
- redis.cn Redis的中文网站
- redis.io Redis的英文网站
- db-engines.com 最全的数据库的一个网站

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









