



题目如下:根据表a表b写一句sql语句表c
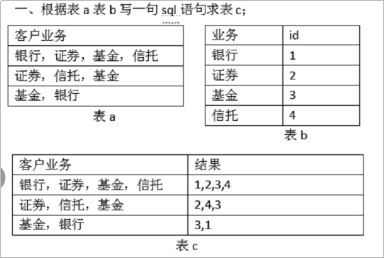
—1.建yinhang表
create table yinhang(
khyw varchar2(50)
);
—2.yinhang表中插入数据
insert into yinhang values('银行'||','||'证券'||','||'基金'||','||'信托');
insert into yinhang values('证券'||','||'信托'||','||'基金');
insert into yinhang values('基金'||','||'银行');
commit;
—3.建yewu表
create table yewu(
yw varchar2(20),
yid number
);
—4.yewu表中插入数据
insert into yewu values('银行','1');
insert into yewu values('证券','2');
insert into yewu values('基金','3');
insert into yewu values('信托','4');
commit;
思路如下:
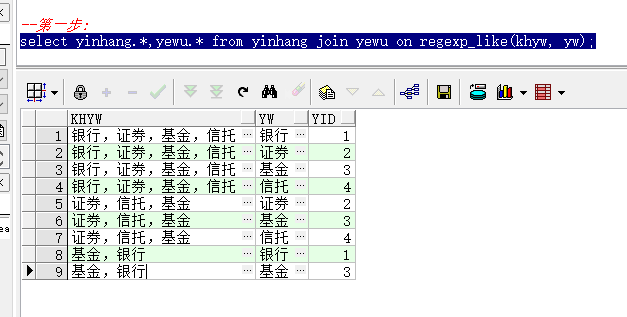
–第一步:
select yinhang.*,yewu.* from yinhang join yewu on regexp_like(khyw, yw);
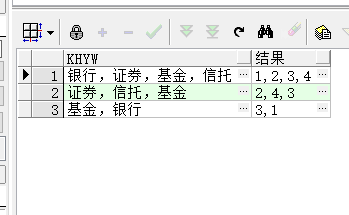
—5.查询语句
select khyw,
listagg(yid, ',') within group(order by instr(khyw, yw)) as 结果
from yinhang
join yewu
on regexp_like(khyw, yw)
group by khyw
order by length(结果) desc;
listagg(yid, ',') within group(order by instr(khyw, yw)) as 结果
这个里面的order by 是对listagg括号里面值的排序,要注意这个

















 743
743

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









