




第一个:order by
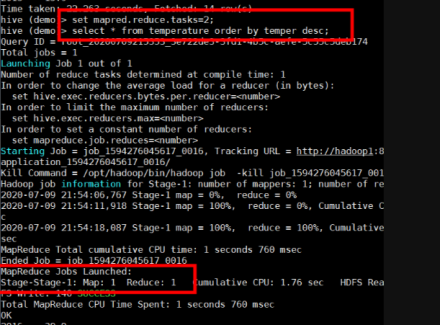
全局性排序,不管设置多少reduce task,只会启动1个reduce task进行排序,因此当输入规模较大时,需要较长的计算时间
当设置set mapred.reduce.tasks=2时,执行order by 排序语句,只显示一个reduce
第二个:sort by
根据reduce task数量,对每个reducer中的数据进行排序,只能保证局部有序。对全局结果集来说不是排序。
注意:
①当reducer task数量设置为1时,相当于order by排序
②排序列必须出现在select column列表中。
set mapreduce.job.reduces=3;
hive (stu_db)> select * from emp_salary order by salary desc;
全局排序;
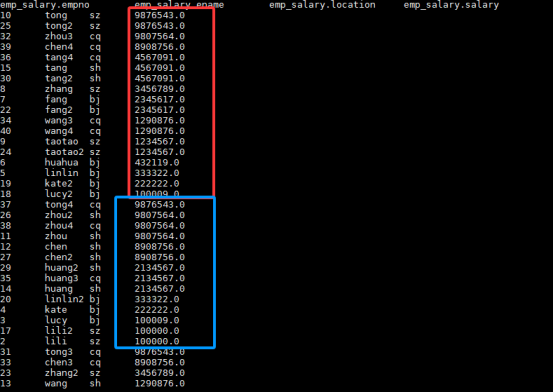
hive (stu_db)> select * from emp_salary sort by salary desc;
分成三个部门排序;
第三个:distribute by
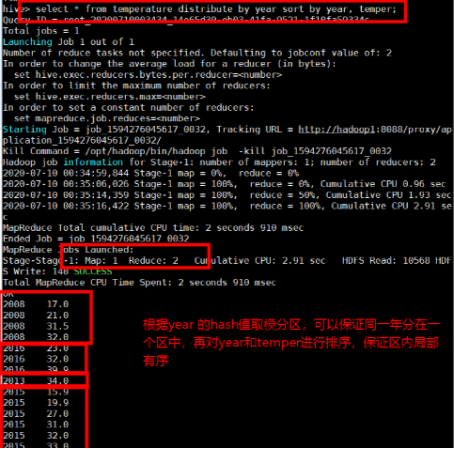
根据字段先进行分区,默认分区为字段的哈希值取模
注意:distribute by只根据字段分区,并不对字段进行排序,
因此常与sort by一起使用,保证分区内有序。
第四个:cluster by
相当于 distribute by+sort by
当distribute by和sort by 字段一致时,可以使用cluster by
注意:
①只能升序排序,不支持ASC 或: DESC
②排序列必须出现在SELECT column列表中

















 1534
1534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









