




 本文介绍了如何使用Python库Surprise构建推荐系统,特别是针对MovieLens数据集。内容涵盖Surprise库的介绍、设计目的、常用类、安装过程、数据集描述以及代码实现,包括数据加载、参数调优和推荐结果的获取。文章还解决了安装过程中可能出现的Microsoft Visual C++ 14.0依赖问题。
本文介绍了如何使用Python库Surprise构建推荐系统,特别是针对MovieLens数据集。内容涵盖Surprise库的介绍、设计目的、常用类、安装过程、数据集描述以及代码实现,包括数据加载、参数调优和推荐结果的获取。文章还解决了安装过程中可能出现的Microsoft Visual C++ 14.0依赖问题。
版权声明:本文为博主原创文章,未经博主允许不得转载。
文章目录
一、Surprise介绍
- Surprise是一个基于Python scikit构建和分析推荐系统。
- Surprise(Simple Python Recommendation System Engine)是一款推荐系统库,是scikit系列中的一个。
- 简单易用,同时支持多种推荐算法:基础算法、基于近邻方法(协同过滤)、矩阵分解等(SVD, PMF, SVD++, NMF)
二、设计surprise时考虑到以下目的
- 让用户完美控制他们的实验。为此,特别强调文档,试图通过指出算法的每个细节尽可能清晰和准确。
- 减轻数据集处理的痛苦。用户可以使用内置数据集(Movielens, Jester)和他们自己的自定义数据集。
- 提供各种即用型预测算法, 例如:基线算法, 邻域方法,基于矩阵因子分解( SVD, PMF, SVD ++,NMF)等等。此外, 内置了各种相似性度量(余弦,MSD,皮尔逊…)。可以轻松实现新的算法思路
- 提供评估, 分析和比较算法性能的工具。使用强大的CV迭代器(受scikit-learn优秀工具启发)以及对一组参数的详尽搜索,可以非常轻松地运行交叉验证程序 。
三、常用类
用法:surprise.prediction_algorithms.XX
| 算法类名 | 说明 |
|---|---|
random_pred.NormalPredictor |
Algorithm predicting a random rating based on the distribution of the training set, which is assumed to be normal. (根据训练集的分布特征随机给出一个预测值) |
baseline_only.BaselineOnly |
Algorithm predicting the baseline estimate for given user and item.(给定用户和Item,给出基于baseline的估计值) |
knns.KNNBasic |
A basic collaborative filtering algorithm. |
knns.KNNWithMeans |
A basic collaborative filtering algorithm, taking into account the mean ratings of each user.(将每个用户评分的均值考虑在内的协同过滤实现) |
knns.KNNBaseline |
A basic collaborative filtering algorithm taking into account a baseline rating. |
matrix_factorization.SVD |
SVD algorithm |
matrix_factorization.SVDpp |
SVD++ algorithm(即LFM+SVD) |
matrix_factorization.NMF |
A collaborative filtering algorithm based on Non-negative Matrix Factorization.(基于矩阵分解的协同过滤) |
slope_one.SlopeOne |
A simple yet accurate collaborative filtering algorithm. |
co_clustering.CoClustering |
A collaborative filtering algorithm based on co-clustering. |
其中基于近邻的方法(协同过滤)可以设定不同的度量准则,用法:surprise.similarities.XX
| 相似度度量标准 | 度量标准说明 |
|---|---|
cosine() |
Compute the cosine similarity between all pairs of users (or items).(余弦相似度) |
msd() |
Compute the Mean Squared Difference similarity between all pairs of users (or items).(均方差异相似度) |
pearson() |
Compute the Pearson correlation coefficient between all pairs of users (or items).(Pearson相关系数) |
pearson_baseline() |
Compute the (shrunk) Pearson correlation coefficient between all pairs of users (or items) using baselines for centering instead of means. |
支持不同的评估准则,用法:surprise.accuracy.XX
| 评估准则 | 准则说明 | 公式 | 意义 |
|---|---|---|---|
mse |
Compute MSE (Mean Squared Error). |
 |
均方误差 |
rmse |
Compute RMSE (Root Mean Squared Error). |
 |
均方根误差 |
mae |
Compute MAE (Mean Absolute Error). |
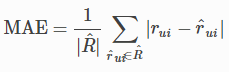 |
平均绝对误差 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1681
1681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











