







 本文介绍了解决Python3.x爬虫在爬取特定网站资源时遇到的UnicodeDecodeError问题的方法。通过调整url_open()函数,将网页源码转换为字符串,避免了因编码问题引发的错误。
本文介绍了解决Python3.x爬虫在爬取特定网站资源时遇到的UnicodeDecodeError问题的方法。通过调整url_open()函数,将网页源码转换为字符串,避免了因编码问题引发的错误。
关于Python 3.x爬虫爬取某些网站资源时,碰到UnicodeDecodeError: 'utf-8' codec can‘t......的解决办法
本文简要概述:爬虫小程序本身很简单,就是爬取一个指定网站上的资源(本文中是图片)。但是对于某些Python小小白来说,可能会遇到某些奇奇怪怪的自己解决不了的问题。所以我决定针对一系列的“坑”写点东西。此文为其一。
代码如下:
import urllib.request as urt
import re
def url_open(url):
req = urt.Request(url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0')
page = urt.urlopen(req)
html = page.read().decode('utf-8')
return html
def get_img(html):
p = r'<img src="([^"]+\.jpg)"'
filelist = re.findall(p, html)
for each in filelist:
filename = each.split('/')[-1]
urt.urlretrieve(each, 'E:\py_Down\HG_Python专属纸篓\爬虫图库\www.27270.com\\'+filename, None)
print("蜘蛛工作完毕")
if __name__ == '__main__':
url = 'http://www.27270.com/ent/meinvtupian'
get_img(url_open(url))
报错图片:
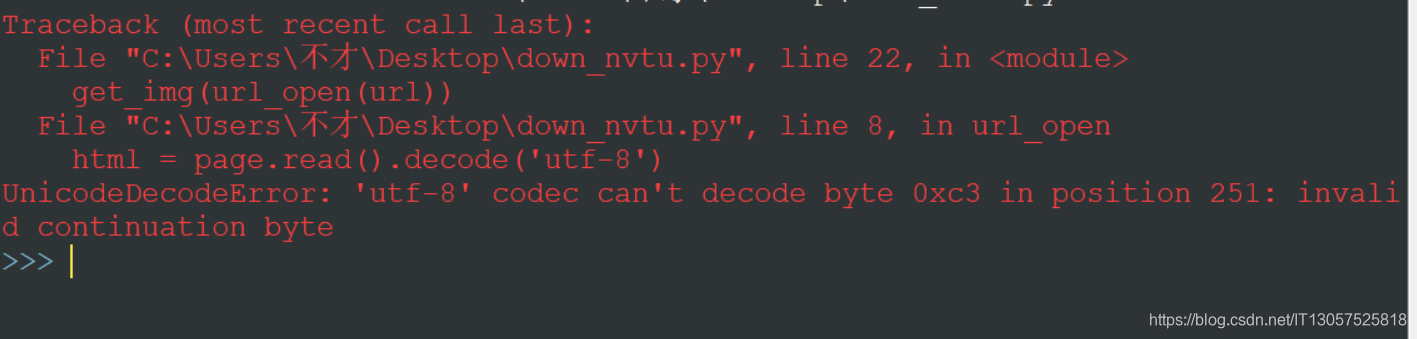
某些小白盆友遇到此问题可能会立即选择上网查对应报错解决办法,接着可能会发现一些帖子所说的办法并不管用。
此时,你需要明确的是,你所写的url_opon()方法目的是得到什么?是得到指定网页的源码字符串,以供后续方法进行爬取操作。
所以,修改url_open()方法为:
def url_open(url):
req = urt.Request(url)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0')
page = urt.urlopen(req)
html = str(page.read())
return html
即可解决此问题。
类似报错可以参考此问题及解决办法。
over

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









