




0 常考知识点
惩罚因子C,越大,过拟合,无穷大时变为硬间隔
合页损失 max(0, 1-Z)
SVM 与 LR 的区别
- LR是参数模型,SVM是非参数模型
- 从目标函数来看,区别在于逻辑回归采用的是logistical loss(二分类,logistic loss就是 cross entropy: L = -( y1 * log(y1_hat) + y2 * log(y2_hat) ) 在 y1 + y2 = 1时的化简),SVM采用的是hinge loss。这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。
- SVM的处理方法是只考虑支持向量,也就是和分类最相关的少数点,去学习分类器。而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重。
- 逻辑回归相对来说模型更简单,特别是大规模线性分类时比较方便。而SVM的理解和优化相对来说复杂一些。
- logic 能做的 svm能做,但可能在准确率上有问题,svm能做的logic有的做不了。
其他
- LR 对异常值敏感、SVM 对异常值不敏感。支持向量机改变非支持向量样本并不会引起决策面的变化,逻辑回归中改变任何样本都会引起决策面的变化。如果我们在 LR 中使用核函数计算,那么每个样本都必须参与核计算,这带来的复杂度是非常高的。而 SVM 中只有少数几个代表支持向量的样本进行了计算
- SVM 只考虑局部的边界线附近的点(支撑向量),而逻辑回归考虑全局(远离的点对边界线的确定也起作用,虽然作用会相对小一些)。
- LR模型找到的那个超平面,是尽量让所有点都远离他,而SVM寻找的那个超平面,是只让最靠近中间分割线的那些点尽量远离,即只用到那些支持向量的样本。
https://www.jianshu.com/p/c49f8ae4cc53
SVM如何处理多分类问题?
间接法:对训练器进行组合。其中比较典型的有一对一,和一对多。
1)一对多: 对每个类都训练出一个分类器,由svm是二分类,所以将此而分类器的两类设定为目标类为一类,其余类为另外一类。这样针对k个类可以训练出k个分类器。
2)一对一: 针对任意两个类训练出一个分类器,如果有 k 类,一共训练出 C2k 个分类器。新样本每当被判定属于某一类时,该类就加一,最后票数最多的类别被认定为该样本的类。
KKT
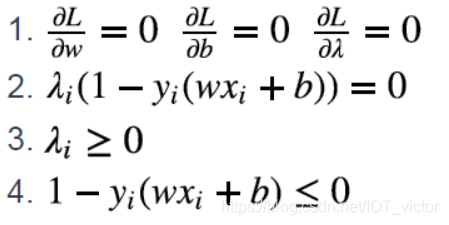
核函数
当样本在原始空间线性不可分时,可将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分。而引入这样的映射后,所要求解的对偶问题的求解中,无需求解真正的映射函数,而只需要知道其核函数。
核函数的定义:K(x,y)=<ϕ(x),ϕ(y)>,即在特征空间的内积等于它们在原始样本空间中通过核函数 K 计算的结果。一方面数据变成了高维空间中线性可分的数据,另一方面不需要求解具体的映射函数,只需要给定具体的核函数即可,这样使得求解的难度大大降低。

- 当特征维数 超过样本数 时 (文本分类问题通常是这种情况), 使用线性核;
- 当特征维数 比较小. 样本数 中等时, 使用RBF核;
- 当特征维数 比较小. 样本数 特别大时, 支持向量机性能通常不如深度神经网络
优缺点
优点
-
由于SVM是一个凸优化问题,所以求得的解一定是全局最优而不是局部最优。
-
不仅适用于线性线性问题还适用于非线性问题(用核技巧)。
-
拥有高维样本空间的数据也能用SVM,这是因为数据集的复杂度只取决于支持向量而不是数据集的维度,这在某种意义上避免了“维数灾难”。
-
理论基础比较完善(例如神经网络就更像一个黑盒子)。
缺点
-
二次规划问题求解将涉及m阶矩阵的计算(m为样本的个数), 因此SVM不适用于超大数据集。(SMO算法可以缓解这个问题)
-
只适用于二分类问题。(SVM的推广SVR也适用于回归问题;可以通过多个SVM的组合来解决多分类问题)看了
各模型的优缺点 https://blog.youkuaiyun.com/mach_learn/article/details/39501849
1 Linear SVM
1.1 SVM基本型
间隔最大化,求最优分离超平面

最条件的最优化问题(最大化间隔d)

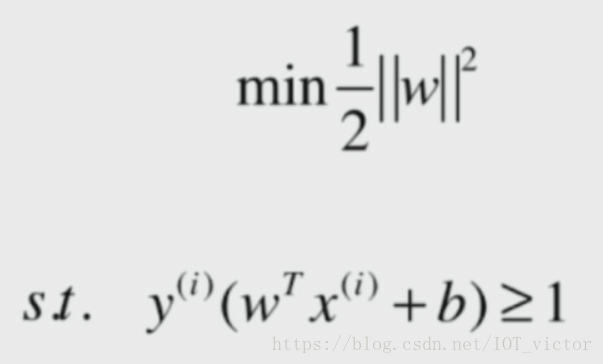
其中,代表w二范数的平方
所以SVM基本型为:
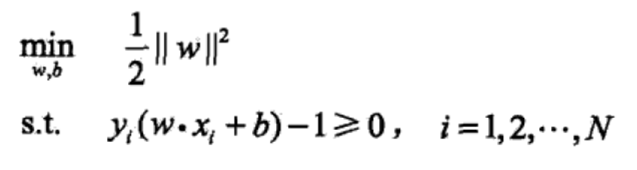
支持向量机是求解凸二次规划(目标函数是二次函数,约束函数是仿射函数)的最优化算法。
凸优化问题的标准形式为:
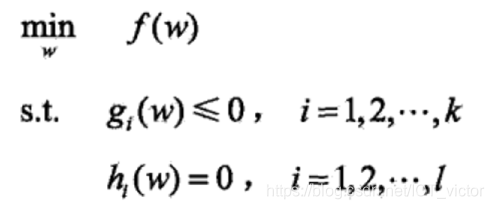
1.2 对偶问题
应用拉格朗日对偶性,通过求解对偶问题(dual problem)得到原始问题的最优解,这样更易求解,且可以自然引入核函数。
满足KKT条件(强对偶关系),先极大再极小(min (max L)),转换成 先对w,b求极小,再求 对拉格朗日乘子的极大。
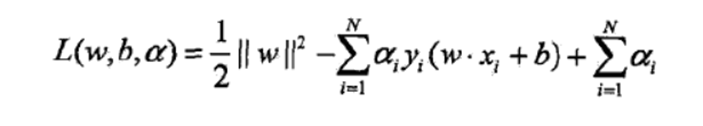

①求L 对 w,b求极小
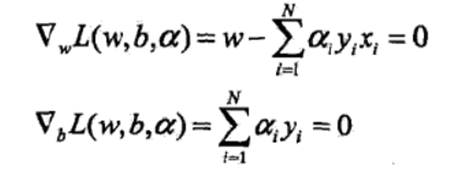
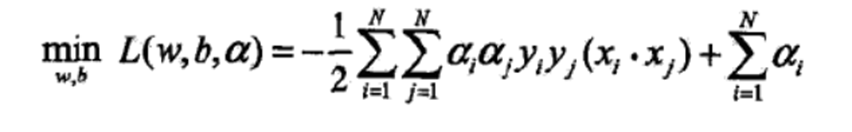
②求min L 对α的极大
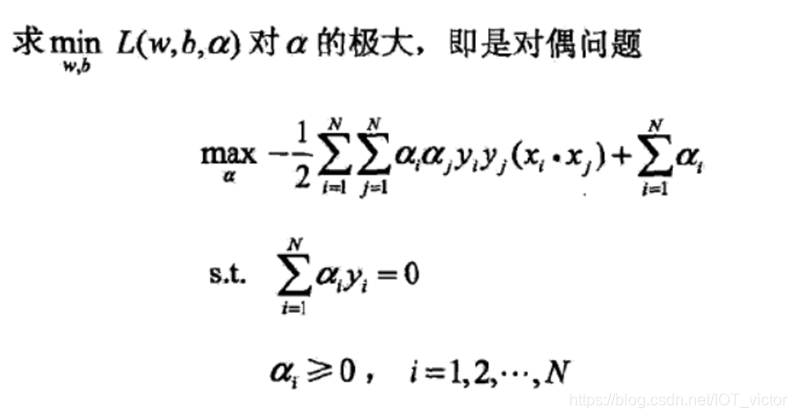
③构造并求解约束优化问题(序列最小最优化SMO算法求解最优解
)
SMO算法的基本思路是每次选择两个变量,选取的两个变量所对应的样本之间间隔要尽可能大,因为这样更新会带给目标函数值更大的变化。
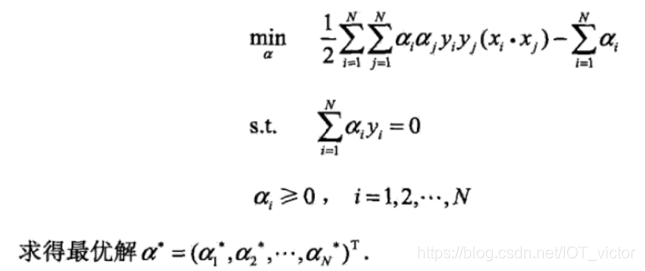
④计算最优 和
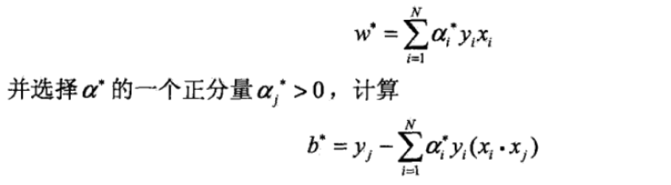
⑤求得分离超平面和分类决策函数
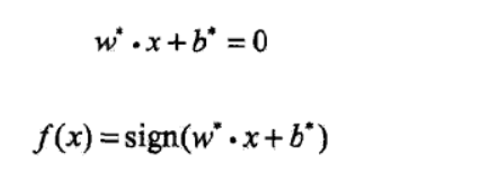
1.3 Soft Margin SVM
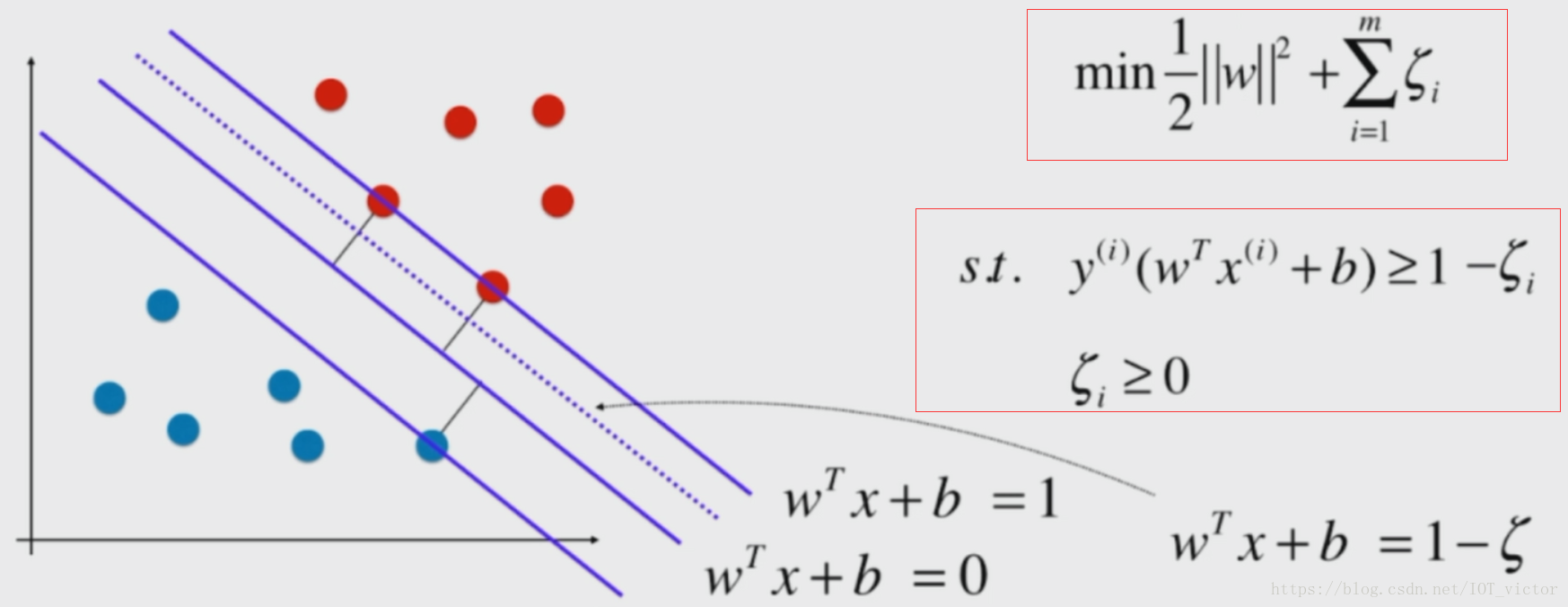
正则化

参考资料
[1] 《统计学习方法》李航
[2] 《Python3入门机器学习 经典算法与应用》liuyubobobo
[3] https://mp.weixin.qq.com/s/j_LzPcESaou0FOS2Z4f3kA

















 2134
2134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









