




文档解析中的数学表达式检测与识别(Mathematical Expression Detection and Recognition, MEDR)是自然语言处理和计算机视觉交叉领域的重要技术,目的在于从文档中定位并解析数学公式,将其转化为结构化表示(如LaTeX、MathML等)。
文档中的数学表达式分为显示式(与普通文本分开)和内联式(嵌入文本行中)两种形式。显示式数学表达式更容易通过文档布局分析进行识别,而内联式数学表达式由于其与普通文本的接近性,需要专门的检测技术。
公式识别的核心技术步骤主要包括:
-
检测(Detection):定位文档中数学表达式的区域,区分文本、表格与公式。
- 方法:传统图像处理方法(边缘检测、连通域分析)或基于深度学习的目标检测模型。
2. 识别(Recognition):将检测到的数学表达式(图像或手写体)转换为机器可读的符号化表示。
- 文本类公式:通过OCR技术结合LaTeX语法解析。
-
图像类公式:结合图像分割与符号识别模型进行解析。
为什么要攻克公式解析难题?
在教育、科研等领域,数学表达式的应用相当常见。当文本OCR技术逐渐成熟,公式识别成为将这类文档转化成结构化可用数据的关卡。以下是两个常见场景:
-
教育智能化
在K12及高等教育中,学生作业、试卷中存在大量手写或印刷公式。传统教学中,作业与试卷一般需要教师进行人工批改。随着公式识别的准确率提升,更多智能化应用开始落地。
例如,基于MEDR技术,智能批改系统可自动识别学生答题步骤中的公式,结合符号语义分析错误逻辑(如符号误用、运算优先级错误),自动批改,并生成针对性反馈。在搜题软件中,学生也可以拍照上传错题,获得详解辅导。电子化笔记整理也是应用场景之一,MEDR技术能够辅助完成笔记、板书等内容从图片到可编辑格式的转化,避免耗时手打工作。
同时,教育服务机构也开始将教科书、教辅、试卷等资料转化为结构化数据,组成完善题库,并根据学生需要,提供针对性训练。
-
学术与科研
科研论文中经常包含复杂公式,其解析准确度决定了知识库质量,以及下游AI应用能否灵活调用有效信息。
另外,科研人员有时需要在论文库中搜索特定公式,但传统文本检索无法识别公式图像。MEDR技术可将论文中的公式转换为LaTeX或MathML代码,帮助学术平台构建可搜索的公式数据库,方便定位相关论文,加速文献调研。
MEDR技术发展
数学表达式检测与识别(MEDR)技术经历了从基于规则到数据驱动的转变。早期方法主要依赖于预定义的规则或文档布局分析来进行数学表达式的检测。随着深度学习的发展,数学表达式检测逐渐采用了类似目标检测的方法来处理文档图像中的数学表达式。
目前的MEDR利用深度学习模型,通过边界框定位或实例分割技术,精确地识别并分离出文档中的数学表达式区域,强化了对复杂和多样的数学表达式结构的处理能力。
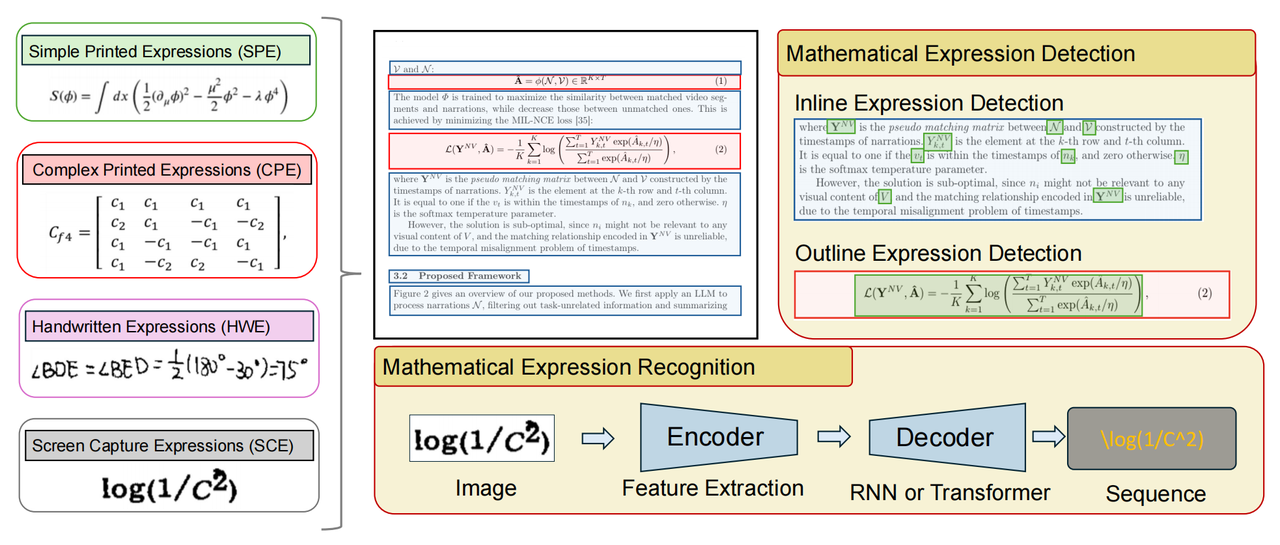
数学表达式检测(MED)
早期的数学表达式检测(MED)利用CNN进行定位。研
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 479
479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









