




TextIn ParseX通用文档解析作为一款适配多样化场景的PDF解析工具,在基础识别能力以上,还提供了便捷、完善的参数配置功能,便于用户根据自身需求调整,获得所需输出结果。在TextIn技术社群,我们的产品团队也经常接到关于参数调配的提问与建议,因此,在本期指南中,我们将介绍常用参数的作用及使用方法,前端界面中参数面板的位置如下图所示。
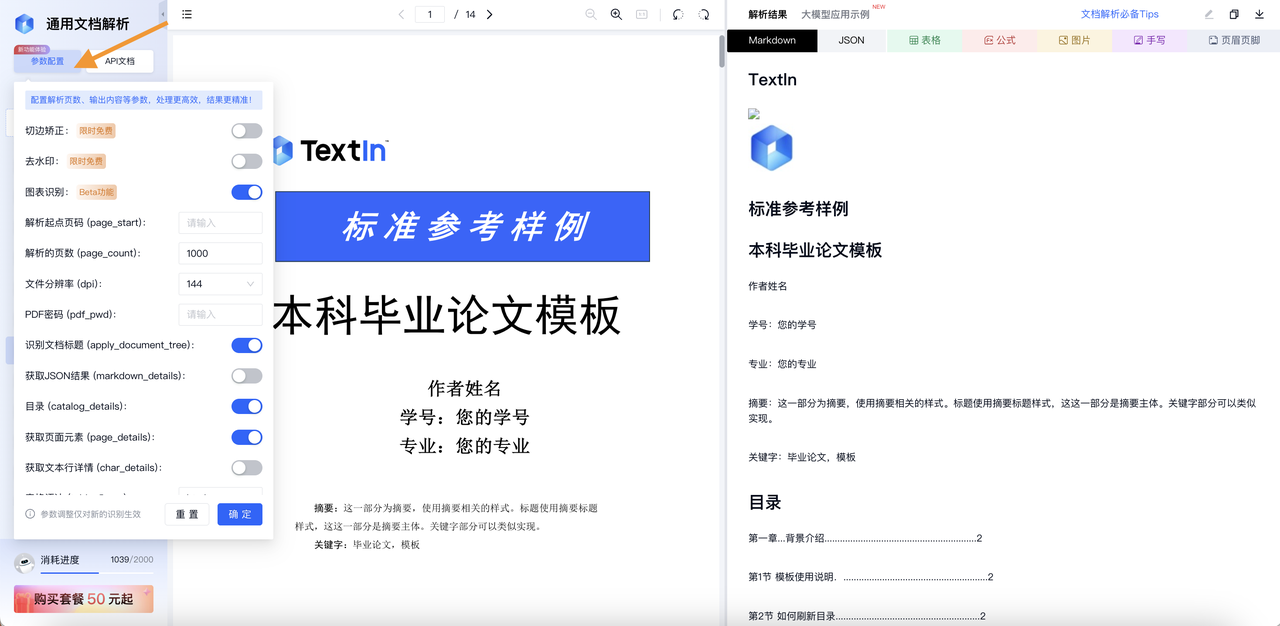
阅读检索指引:
| 参数名称 |
使用场景 |
|---|---|
| page_start & page_count |
需解析文件中部分页码 |
| dpi |
调控分辨率 |
| pdf_pwd |
解析加密PDF文件 |
| apply_document_tree & catalog_details |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 480
480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









