




在文档解析工作中,我们日常会遇到种类繁多的文件类型:书籍、期刊、论文、企业年报、公告、金融研报、国标材料、试卷,等等不胜枚举。基于深度学习方法,当前的版面分析技术能够妥善处理包括多栏排版论文、跨页无线表格在内的众多复杂版面情况。
尽管如此,仍有更丰富的案例进入我们的视野,它们被应用于学术研究、AI训练等场景,特殊的版面构成向当前的技术提出了挑战。例如,以下两张报纸页面。


以报纸、杂志为代表的版面结构复杂,缺乏统一性,解析难度相较其他文档更高。在当前技术的基础上,合合信息技术团队已关注到这一类版面布局,并开展研究,探索提高算法模型表现的方法。
1 TransDLANet文档布局分析方法
TransDLANet[1] 是一个基于 Transformer 的文档布局分析方法,采用实例分割的方式进行布局提取。方法遵循 ISTR[2] 的框架,但在核心上进行了变化,通过利用自适应元素匹配机制,使查询嵌入能够更好地匹配真实标注并提高召回率。TransDLANet使用不带位置编码的 Transformer 编码器作为特征融合方法,构建了一个分割分支以实现更精确的文档图像实例分割,并使用三个共享参数的多层感知机(MLP)分支进行多任务学习。
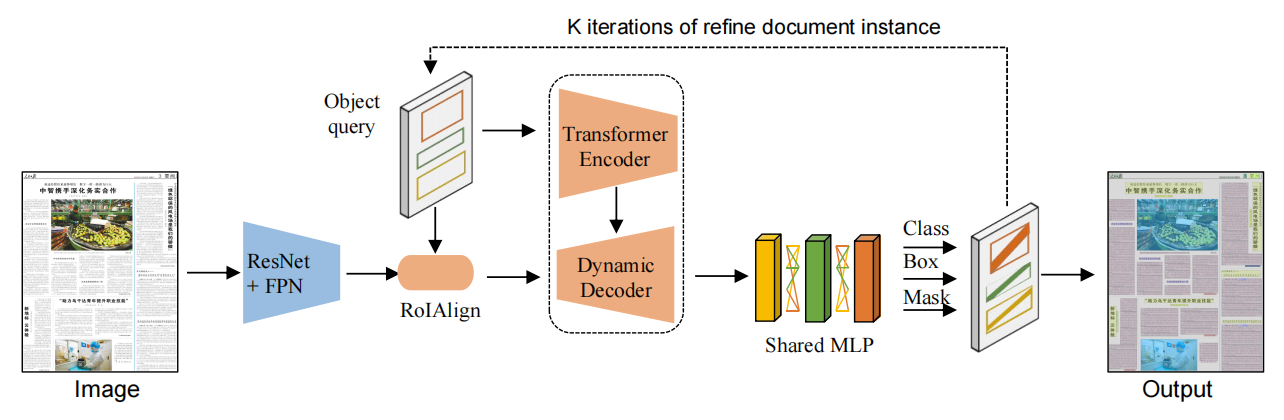
TransDLANet 架构:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 531
531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









