




标题HashMap的底层结构
HashMap是基于哈希表的Map接口实现,以key-value的形式存在。在HashMap中,key-value总是以一个整体来处理
系统会根据hash算法来计算key-value的存储位置,我们总是可以通过key快速的存取value
**一:**定义
HashMap实现了Map接口,继承AbstractMap。其中Map接口定义了键映射到值的原则而AbstractMap类提供 Map 接口的骨干实现,以最大限度地减少实现此接口所需的工作,其实AbstractMap类已经实现了Map。
二:构造函数
HashMap提供了三个构造函数
HashMap();构造一个默认初始容量(16)和默认因子(0.75)的空HashMap
HashMap(int initialCapacity);构造一个带指定初始容量和默认加载因子(0.75)的空HashMap
HashMap(int initialCapacity, float loadFactor;)构造一个带指定初始因子和加载因子的空HashMap
参数中容量代表哈希表的桶的数量,也就是底层数据结构中数组的大小。加载因子是哈希表可以装多满的一种尺度
,衡量散列表的空间的实用程度,加载因子越大表示散列表的装填程度越高,反之越小。因子越大查找效率会变低。因子太小
空间使用率越低,因子系统默认加载因子为0.75,一般无需修改
三:数据结构
在Java中最常用的两种数据结构是数组和链表,几乎所有的数据结构都可以用这两种组合来实现,HashMap也是,实际上HashMap是一个“链表散列”,数据结构如下:
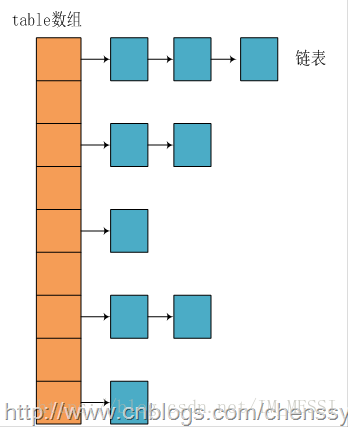
可以看出HashMap的底层还是数组,只是每一项都是一条链,所以说构造函数中的参数代表了该数组的长度,每次新建一个HashMap都会创建一个table数组,元素为装有key-value值的entry节点,其中还包括下一个节点next,下图是entry节点的数据结构:
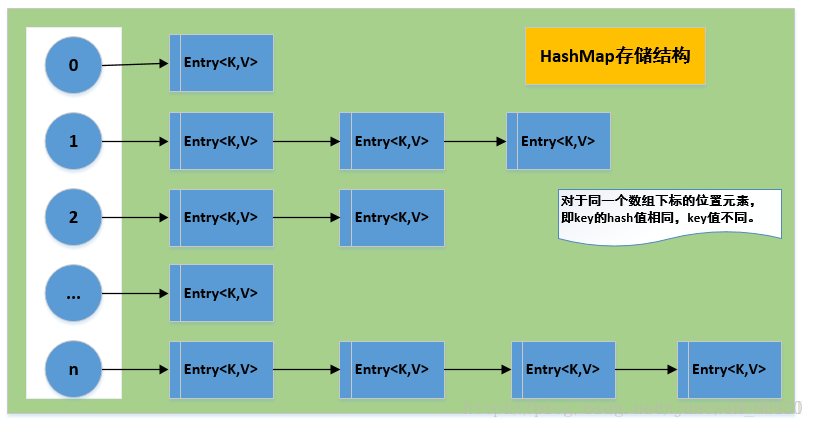
四:存储过程
通过源码我们可以知道,1:判断key是否为空,若为空,直接调用putForNullKey方法。将null放在table的第一个位置中;2:不为空的话先计算key的hash值,然后根据hash值搜索在table中的索引位置,如果table数组在该位置处有元素则通过比较是否存在相同的key,存在则覆盖原来的value值,否则将该元素保存在链头(最先保存的放链尾)。若在该位置出没有元素,则直接保存。。。
注1:
这里为什么最先保存的放链尾呢?先看一下链是怎么产生的
系统总是将新的Entry对象添加到bucketIndex处。如果bucketIndex处已经有了对象,那么新添加的Entry对象将指向原有的Entry对象,形成一条Entry链,但是若bucketIndex处没有Entry对象,也就是e==null,那么新添加的Entry对象指向null,也就不会产生Entry链了。
五:获取过程
通过key的hash值找到table中数组的索引出的entry,然后返回该key对应的value值
六:扩容问题
随着HashMap中元素的个数越来越多,产生的链表就会越来越长,会影响HashMap的效率,所以在某个临界点就必须扩容 这个临界就是HashMap中的 元素数量=table数组的长度*加载因子,扩大为原来容量的2倍
,扩容很繁琐,他需要重新计算HashMap中各个元素的位置,所以在初始化的时候如果知道元素数量,就要对HashMap的初始容量进行衡量

















 343
343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









