




通常dba都会维护很大的数据库,其中包含几千个索引。作为主动维护的一部分,你需要确定是否有一些索引没有使用。你已经认识到用不到的索引对性能存在负面影响,因为每次插入、更新或删除一个数据行时,都需要维护相应的索引,这将消超 CPU 资源和磁盘空间。如果一个索引不会再用到,那就应该将它删除。
使用 ALTER INDEX…MONITORING USAGE 语句来启用基本的索引监控.下面这个例子在名为HJJ的索引上启用了索引监控
CREATE TABLE HYP
( ID VARCHAR2(11) NOT NULL,
XH VARCHAR2(11),
HHH VARCHAR2(11)
)
CREATE INDEX HJJ ON HYP(ID);
SQL> alter index HJJ monitoring usage;
Index altered.
SQL>
索引第一次被访问时,Oracle 将会记录下来.可以通过V$OBJECT_USAGE视图来查看一个索引是否被访问.要查看哪些索引是被监控的以及是否曾经被访问过,可以运行下面这个查询:
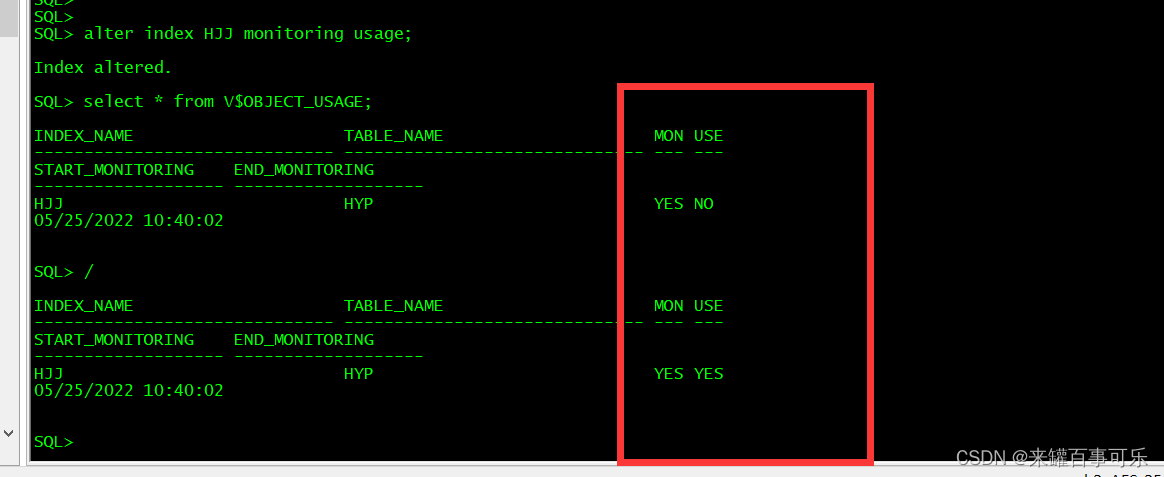
如果索引曾经被SELECT语句使用过,那么USED列的值将会为YES.
大多数时候,我们不会只监控一个索引,而是想要监控一个用户的所有索引.在这种情况下,使用SQL生成一个查询语句脚本,运行该脚本可以监控所有索引.下面给出一个例子:
set pagesize 0 head off linesize 132
spool enable mon.SQL
select
'alter index ' || index_name || ' monitoring usage;'
from user_indexes;
spool off;
执行成功后看到的结果
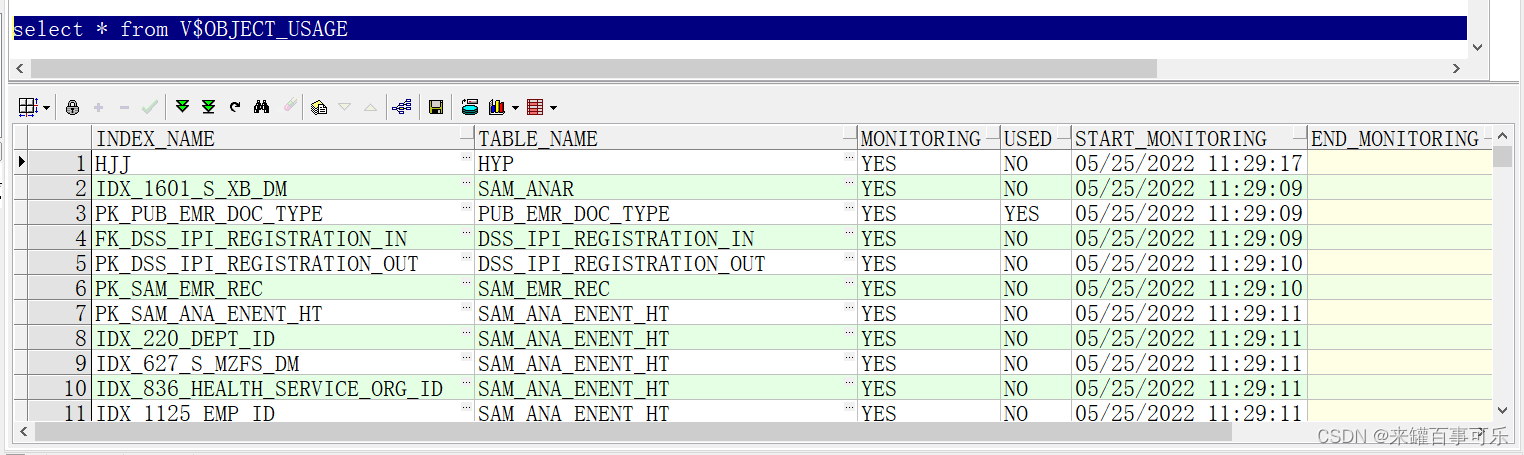
要在一个索引上禁用监控,使用NOMONITORING USAGE,子句
比如

监控索引使用率的主要好处就是识别出不被使用的索引.这样可以确定能够删除的索引,从而释放磁盘空间,并提高 DML 语句的性能.
V$OBJECT_USAGE视图中只提供当前连接用户的信息.可以查看V$OBJECT_USAGE定义的 DBA VIEWS 中的 TEXT 列来验证这一点:
select text from dba_views where view_name = 'V$OBJECT_USAGE';
注意输出中的下面这一行: where io.owner# = userenv('SCHEMAID')
这一行命令该视图仅显示当前连接用户的信息.如果你以数据库管理员权限登录,并且想查看所有启用了监控的索引(不管是哪个用户的)的状态,那么执行这个查询:
select io.name, t.name,
decode(bitand(i.flags, 65536), 0, 'NO', 'YES'),
decode(bitand(ou.flags, 1), 0, 'NO', 'YES'),
ou.start_monitoring,
ou.end_monitoring
from sys.obj$ io, sys.obj$ t, sys.ind$ i, sys.object_usage ou
where io.owner# = userenv('SCHEMAID')
and i.obj# = ou.obj#
and io.obj# = ou.obj#
and t.obj# = i.bo#
上面这个查询移除了限定只显示当前登录用户信息的那一行,这是查看所有被监控索引的方便方法。
不用index monitor usage 获得索引使用情况
SELECT p.object_name,
p.operation,
p.options,
COUNT (1)
FROM dba_hist_sql_plan p, dba_hist_sqlstat s
WHERE p.object_owner <> 'SYS'
AND p.operation LIKE '%INDEX%'
AND p.sql_id = s.sql_id
GROUP BY p.object_name, p.operation, p.options
ORDER BY 1, 2, 3;
某个索引使用情况:
SELECT TO_CHAR (sn.begin_interval_time, 'yy-mm-dd hh24'),
p.search_columns,
COUNT (*)
FROM dba_hist_snapshot sn, dba_hist_sql_plan p, dba_hist_sqlstat st
WHERE st.sql_id = p.sql_id
AND sn.snap_id = st.snap_id
AND p.object_name = '&idxname'
GROUP BY begin_interval_time, search_columns;
按日期查看索引的使用统计:
WHERE p.object_owner <> 'SYS'
AND p.operation LIKE '%INDEX%'
AND p.options LIKE '%UNIQUE%'
AND p.sql_id = s.sql_id
AND s.snap_id = sn.snap_id
GROUP BY TO_CHAR (sn.begin_interval_time, 'yy-mm-dd hh24')
ORDER BY 1) u,
( SELECT TO_CHAR (sn.begin_interval_time, 'yy-mm-dd hh24') c1,
COUNT (1) c2
FROM dba_hist_sql_plan p, dba_hist_sqlstat s, dba_hist_snapshot sn
WHERE p.object_owner <> 'SYS'
AND p.operation LIKE '%INDEX%'
AND p.options LIKE '%FULL%'
AND p.sql_id = s.sql_id
AND s.snap_id = sn.snap_id
GROUP BY TO_CHAR (sn.begin_interval_time, 'yy-mm-dd hh24')
ORDER BY 1) f
WHERE r.c1 = u.c1 AND r.c1 = f.c1;
按日期统计全表扫描,索引扫描:
SELECT i.c1 begin_interval_time,
i.c2 index_Table_Scans,
f.c2 Full_Table_Scans
FROM ( SELECT TO_CHAR (sn.begin_interval_time, 'yy-mm-dd hh24') c1,
COUNT (1) c2
FROM dba_hist_sql_plan p, dba_hist_sqlstat s, dba_hist_snapshot sn
WHERE p.object_owner <> 'SYS'
AND p.operation LIKE '%TABLE ACCESS%'
AND p.options LIKE '%INDEX%'
AND p.sql_id = s.sql_id
AND s.snap_id = sn.snap_id
GROUP BY TO_CHAR (sn.begin_interval_time, 'yy-mm-dd hh24')
ORDER BY 1) i,
( SELECT TO_CHAR (sn.begin_interval_time, 'yy-mm-dd hh24') c1,
COUNT (1) c2
FROM dba_hist_sql_plan p, dba_hist_sqlstat s, dba_hist_snapshot sn
WHERE p.object_owner <> 'SYS'
AND p.operation LIKE '%TABLE ACCESS%'
AND p.options = 'FULL'
AND p.sql_id = s.sql_id
AND s.snap_id = sn.snap_id
GROUP BY TO_CHAR (sn.begin_interval_time, 'yy-mm-dd hh24')
ORDER BY 1) f
WHERE i.c1 = f.c1;
查询重复的索引列,查看有哪些索引含有重复的字段, 从而让索引更加合理化:
SELECT /*+ rule */
a.table_owner,
a.table_name,
a.index_owner,
a.index_name,
column_name_list,
column_name_list_dup,
dup duplicate_indexes,
i.uniqueness,
i.partitioned,
i.leaf_blocks,
i.distinct_keys,
i.num_rows,
i.clustering_factor
FROM (SELECT table_owner,
table_name,
index_owner,
index_name,
column_name_list_dup,
dup,
MAX (dup)
OVER (PARTITION BY table_owner, table_name, index_name)
dup_mx
FROM ( SELECT table_owner,
table_name,
index_owner,
index_name,
SUBSTR (SYS_CONNECT_BY_PATH (column_name, ','), 2)
column_name_list_dup,
dup
FROM (SELECT index_owner,
index_name,
table_owner,
table_name,
column_name,
COUNT (1)
OVER (PARTITION BY index_owner,index_name)
cnt,
ROW_NUMBER ()
OVER (PARTITION BY index_owner, index_name
ORDER BY column_position)
AS seq,
COUNT (1)
OVER (PARTITION BY table_owner,
table_name,
column_name,
column_position)
AS dup
FROM sys.dba_ind_columns
WHERE index_owner = 'SCOTT')
WHERE dup != 1
START WITH seq = 1
CONNECT BY PRIOR seq + 1 = seq
AND PRIOR index_owner = index_owner
AND PRIOR index_name = index_name)) a,
( SELECT table_owner,
table_name,
index_owner,
index_name,
SUBSTR (SYS_CONNECT_BY_PATH (column_name, ','), 2)
column_name_list
FROM (SELECT index_owner,
index_name,
table_owner,
table_name,
column_name,
COUNT (1) OVER (PARTITION BY index_owner,
index_name)
cnt,
ROW_NUMBER ()
OVER (PARTITION BY index_owner, index_name
ORDER BY column_position)
AS seq
FROM sys.dba_ind_columns
WHERE index_owner = 'SCOTT')
WHERE seq = cnt
START WITH seq = 1
CONNECT BY PRIOR seq + 1 = seq
AND PRIOR index_owner = index_owner
AND PRIOR index_name = index_name) b,
dba_indexes i
WHERE a.dup = a.dup_mx
AND a.index_owner = b.index_owner
AND a.index_name = b.index_name
AND a.index_owner = i.owner
AND a.index_name = i.index_name
ORDER BY a.table_owner, a.table_name, column_name_list_dup;
将不被使用的索引删除
SQL> SELECT VISIBILITY FROM DBA_INDEXES WHERE INDEX_NAME='HJJ';
SQL> ALTER INDEX HJJ INVISIBLE;
SQL> DROP INDEX HJJ;

















 2758
2758

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









