




 本文介绍了一种针对Bottleneck模块的创新剪枝方法,通过裁剪整个模块来提升效率。提出在训练中使用L1正则针对BN层权重,促使激活更接近于0。详情可见作者的GitHub更新:https://github.com/midasklr/yolov5prune。
本文介绍了一种针对Bottleneck模块的创新剪枝方法,通过裁剪整个模块来提升效率。提出在训练中使用L1正则针对BN层权重,促使激活更接近于0。详情可见作者的GitHub更新:https://github.com/midasklr/yolov5prune。
在之前介绍了基于Network Slim的bn层通道剪枝策略。
但是因为Bottleneck模块中shortcut的存在需要shortcut和残差有相同的size,所以没对有shortcut的Bottleneck模块进行裁剪,但是实际上,我们可以把整个残差都裁剪掉,如图:
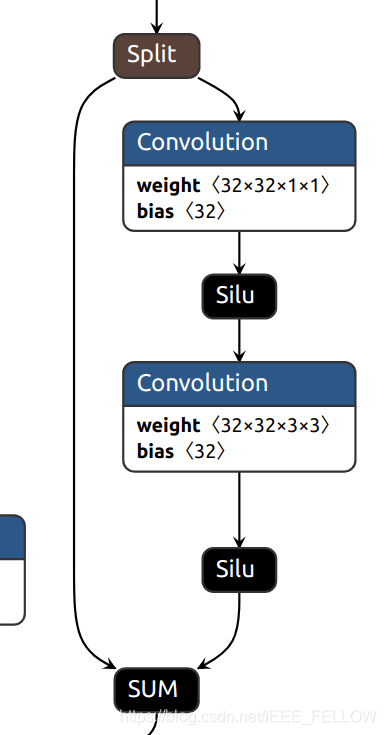
可以将右边的残差分支两个Conv都裁剪,这样就吧整个Bottleneck都裁剪掉了,这样可以更大化地剪枝。
在之前的基础上,在训练中,我们给第二个Conv模块的BN层权重添加L1正则,使得激活逼近0.
未完待续。。
相关代码和实验结果已经更新: https://github.com/midasklr/yolov5prune



















 407
407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









