




 如何在保证模型性能不下降的前提下,有效提升联邦学习的训练效率,是当前研究热点。文章介绍了同步参数更新、异步参数更新和基于模型集成的加速方法,如增加通信间隔、减少传输内容等,还提及了相关策略及优缺点。
如何在保证模型性能不下降的前提下,有效提升联邦学习的训练效率,是当前研究热点。文章介绍了同步参数更新、异步参数更新和基于模型集成的加速方法,如增加通信间隔、减少传输内容等,还提及了相关策略及优缺点。
目录
如何在保证模型性能不下降的前提下,有效提升联邦学习的训练效率,成为当前联邦学习的一个研究热点问题。
模型计算和通信传输成为影响联邦学习效率的两大因素。具体优化联邦学习的各类方法见下图:
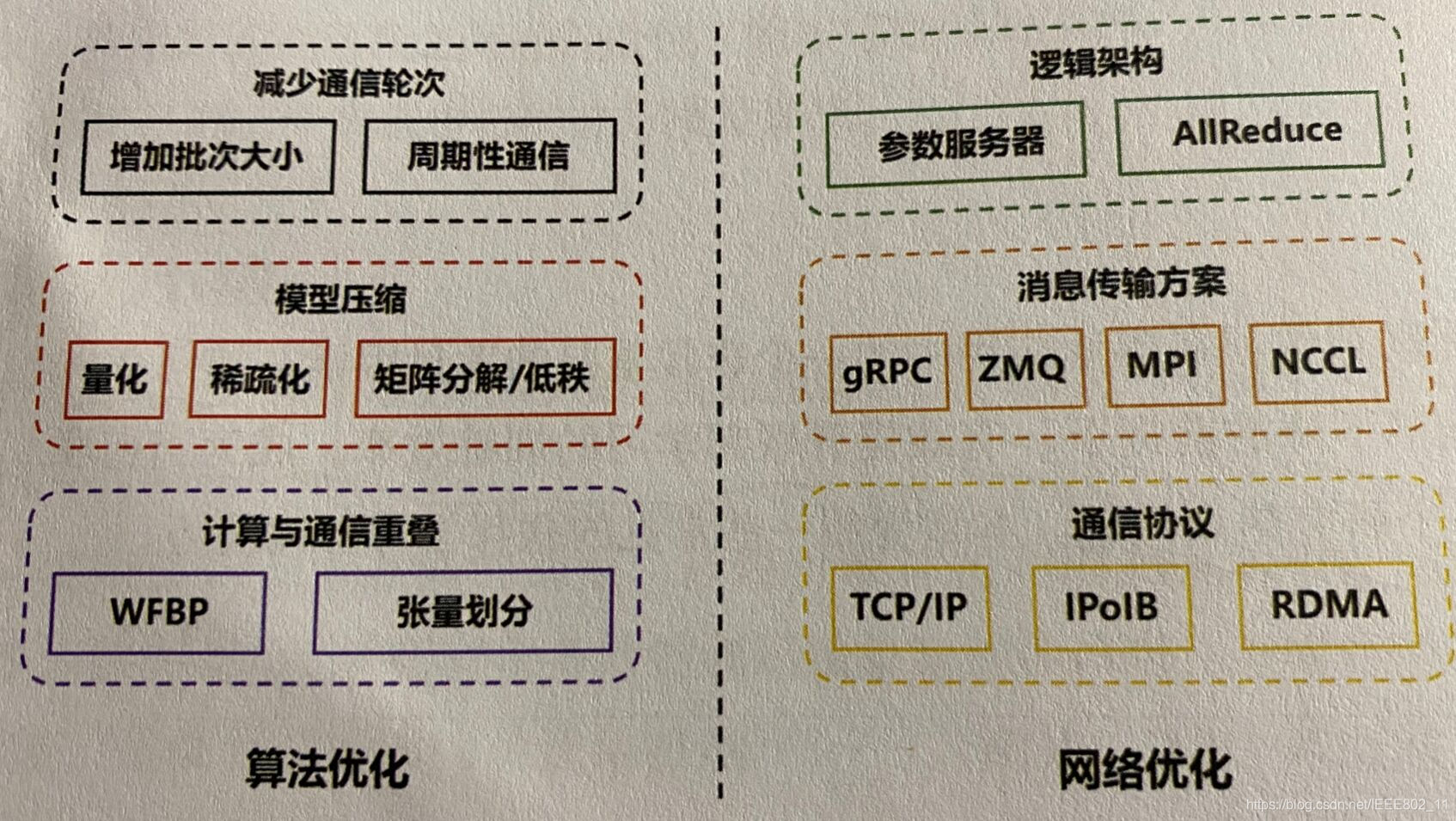
WFBP表示wait-free backpropagation;0ZMQ表示ZeroMQ,NCCL表示NVIDIA collective library。
通信效率的优化显得比计算性能的优化复杂和困难得多,因而从计算机系统的角度看,边缘端设备的算力水平在不断提高。但通信网络,一方面受网络带宽的影响另一方面由于联邦学习的客户端分布具有跨地域的特点,使得各客户端设备之间的通信延迟提高,设备间通信失败的风险比一般的分布式学习大。
同步参数更新的加速方法
同步的参数更新是指服务器会等待每一个客户端完成本地迭代并上传更新的模型参数,然后进行统一的聚合处理。适当降低通信的频度,从而减小通信开销,加速模型训练,常见的方法包括增加通信间隔、减小传输内容、非对称的推送和获取、计算和传输流水线操作。
增加通信间隔
将通信的频度从原来本地模型每次更新后(即每个SGD更新步骤)都通信一次,变成本地模型多次更新后(即多个SGD更新步骤)才通信一次。
减少传输内容
两个代表性的联邦学习的模型参数更新策略:
- 轮廓更新(Sketched updates):参与方在本地正常更新模型参数,之后以编码的方式对参数进行压缩并上传,服务器将压缩的模型参数进行解码,还原原始的模型参数。
- 结构更新(Structured updates):在联邦模型训练过程中,参与方之间可以先限定要传输模型的结构,模型传输只按照限定的结构进行。可以采用掩码策略。掩码矩阵是一个维度与原始模型维度相同的只包含0或1的矩阵。在上传模型参数时,只上传掩码矩阵对应位置为1的元素。
由于模型结构在联邦学习中是共享的,所以我们可以使用模型参数的压缩技术来降低通信代价。深度学习的模型压缩策略都可以应用到联邦学习场景中。具体的方法包括知识蒸馏、网络剪枝,以及针对移动端设备的轻型网络SqueezeNet、MobileNets、Shufflent、Xception等。
模型压缩出了能够有效减少参数传输量、提升联邦学习的训练效率,还能在一定程度上保护模型的原始参数不被泄露,提升模型的安全性。
非对称的推送和获取
联邦学习的通信操作主要包括下面两点:向协调方推送模型更新;从协调方获取最新的全局模型。可以对这两种操作采用不同的通信频率。
在训练过程中,如果某个参与方的本地模型参数变化不太大,实际上没有必要频繁地把很小的更新发送到协调方。同样,也没有必要在每一步都对本地模型进行校准。通过调节推送间隔和获取间隔这两个参数,我们可以在系统性能和模型精度之间找到一个平衡点。
计算和传输重叠
通过在时间上将计算进程和通信进程重叠并行来实现,即流水线操作。流水线是计算机系统中常用的优化方法,通过将没有依赖关系的不同操作用流水线并行,获得加速。
在联邦学习训练过程中,可以将一次迭代分为计算和通信两个步骤。虽然相邻两次迭代之间存在依赖性,但可以利用机器学习的容错性,适当打破这种依赖关系,从而让两次迭代之间的计算和通信以流水线的方式重叠。
异步参数更新的加速方法
异步更新策略是指联邦系统中的每一个参与方完成本地模型训练迭代后,无需等待联邦学习系统的其他参与方,就可以向服务端发送本地模型参数更新并请求当前的全局模型下发,以便继续进行后续训练。同时,服务端也会根据每一个客户端上传的最新模型参数进行聚合,而不需要考虑每一个参与方与服务端的通信次数是否相同。
与同步更新相比,尽管异步更新策略的效率可以大大提高,但是,它会使得来自不同参与方的本地模型参数之间存在延迟的现象,给模型聚合的收敛性带来了一定的影响。
异步更新策略可能引发“延迟”问题,即各参与方的初始本地模型很可能不是当前最新的全局模型,这是因为全局模型不再由服务端进行统一的分发,每一个客户端都独立地从服务端申请获取全局模型,造成各个客户端获取的全局模型很不一致。另一个问题就是模型的不稳定性,这主要是因为参与方之间的步调可能相差很大。
研究人员也提出了很多折中的解决方案,即介于同步和异步之间的新的通信方式,例如延时同步并行(SSP)、带延迟补偿的异步随机梯度下降算法、基于集成压缩的异步更新方法。
基于模型集成的加速方法
One-Shot联邦学习
针对横向两帮学习,one-shot联邦学习被提出,即参与方与协调服务器之间只需要进行一轮通信就可以完成全局联邦学习模型的构建。
基于有监督的集成学习方法
由于不同参与者的本地模型质量可能有很大不同,最佳的生成全局联邦模型的方法可能只需要考虑一部分参与者的本地模型,而非所有参与者的本地模型。具体有以下几种策略:
- 交叉验证(CV)选择:设备只有在其本地验证数据上达到某些基准性能(例如ROC或AUC)时,才共享其本地模型,并且基准由协调服务器预先确定。服务器从这个K个本地模型集合中,挑选符合性能指标的前N个最佳模型。
- 数据选择:参与者只有在拥有一定数量的本地培训数据时才共享其本地模型,并且该数据量由协调服务器预先确定。协调服务器将这些本地模型中的模型集成在一起,这些模型是在前N个最大的数据集上训练的。
- 随机选择:服务器从K个本地模型中随机选择N个本地模型进行聚合。
基于半监督及知识蒸馏的方法
当协调服务器可以访问未标记的公共代理数据时,可以通过知识蒸馏将联邦模型压缩为较小的模型。在传统的知识蒸馏方法中,利用教师模型输出的带有概率标记的数据对学生模型进行训练,从而将教师模型中的知识转移到学生模型中。
知识蒸馏不仅有助于压缩模型,还可以实现隐私保护学习。
基于学习的联邦模型集成
特征分布的机器学习(FDML)采用异步随机梯度下降算法。FDML系统对任何有监督的学习任务都有效,它要求每个参与方可以使用任意的模型,通过将数据输入每一个客户端模型中得到局部特征,进一步得到局部预测,将不同的局部预测汇总为最终预测。
FDML系统的优点是,在每次训练迭代期间,每个参与方都应使用自己的局部特征集的小批量来更新局部模型参数,并且对于每个样本,只需共享其局部对协调服务器的预测。由于一方的原始功能或本地模型参数没有转移到任何外部站点,FDML保留了数据的局部性,并且更不容易遭受针对其他协作学习算法的模型反转进攻。
本读书笔记系列针对2021年5月出版的《联邦学习实战》(见下图),后续部分将逐步更新




















 561
561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











