






 文章介绍了单链表作为数据结构基础的重要性,特别是在处理图和树结构中的应用。提到了通过单链表可以更高效地执行插入和删除操作。文章提供了一个单链表的模板代码,并给出了一道编程题,要求实现链表的插入、删除和查询操作。最后,提供了题目的解决方案。
文章介绍了单链表作为数据结构基础的重要性,特别是在处理图和树结构中的应用。提到了通过单链表可以更高效地执行插入和删除操作。文章提供了一个单链表的模板代码,并给出了一道编程题,要求实现链表的插入、删除和查询操作。最后,提供了题目的解决方案。
首先我要说明一点,从单链表这里开始我们的数据结构就开始步入基础了啊,而单链表属于数据结构的一个非常重要的的基础。我推荐大家除了看我这里总结的实战模板,最好去优快云找找大佬的讲解看看,还有去哔站上找找视频学一学啊。
单链表又称邻接表,它最重要的作用就是存储图和树,这在以后会十分常用,什么最短路啊生成树啊最大流啊什么的,这都是基础。
单链表本质上是把物理位置上不相邻的内存在逻辑上建立相邻的关系,这使得我们不需要一直使用顺序表,大大节省了我们在一个逻辑中删除和插入所需要耗费的操作,增加了运行效率。
//以下是单链表的板子,需要背过
// head存储链表头,e[]存储节点的值,ne[]存储节点的next指针,idx表示当前用到了哪个节点
int head, e[N], ne[N], idx;
// 初始化
void init()
{
head = -1;
idx = 0;
}
// 在链表头插入一个数a
void insert(int a)
{
e[idx] = a, ne[idx] = head, head = idx ++ ;
}
// 将头结点删除,需要保证头结点存在
void remove()
{
head = ne[head];
}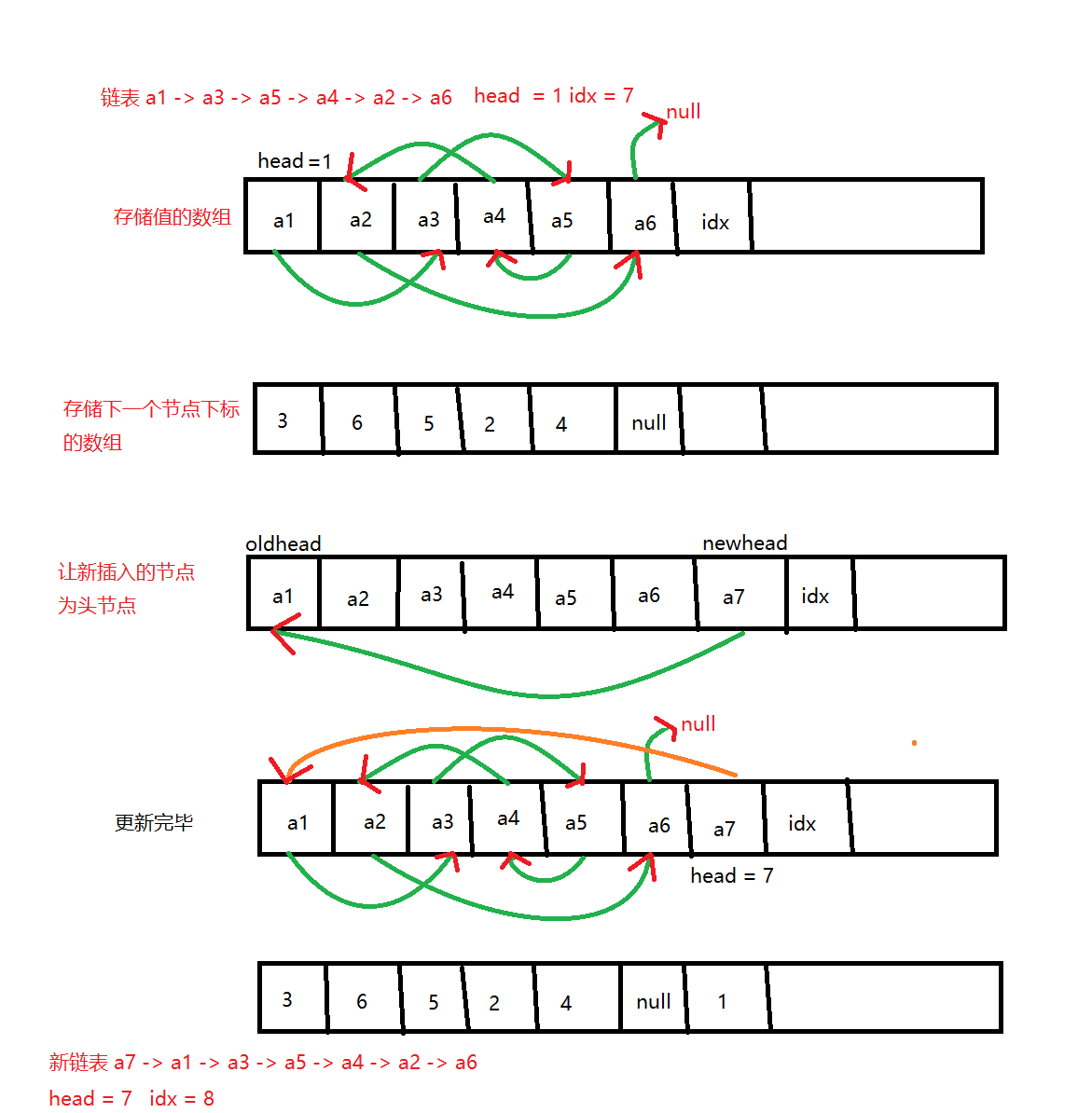
上图来自于ACwing上 海盐饼干 大佬。
给一道例题吧(有一些小小的解说):
实现一个单链表,链表初始为空,支持三种操作:
向链表头插入一个数;
删除第k个插入的数后面的数;
在第k个插入的数后插入一个数。
现在要对该链表进行M次操作,进行完所有操作后,从头到尾输出整个链表。
注意:题目中第k个插入的数并不是指当前链表的第k个数。例如操作过程中一共插入了n个数,则按照插入的时间顺序,这n个数依次为:第1个插入的数,第2个插入的数,…第n个插入的数。
#include <iostream>
using namespace std;
const int N = 100010;
int n;
int h[N], e[N], ne[N], head, idx;
//对链表进行初始化
void init(){
head = -1;//最开始的时候,链表的头节点要指向-1,
//为的就是在后面进行不断操作后仍然可以知道链表是在什么时候结束
idx = 0;
}
//将x插入到头节点上
void int_to_head(int x){
e[idx] = x;//第一步,先将值放进去
ne[idx] = head;//head作为一个指针指向空节点,现在ne[idx] = head;
head = idx;//head现在不再是空指针了。
idx ++;//指针向下移一位,为下一次插入元素做准备。
}
//将x插入到下标为k的点的后面
void add(int k, int x){
e[idx] = x;//先将元素插进去
ne[idx] = ne[k];//让元素x配套的指针,指向它要占位的元素的下一个位置
ne[k] = idx;//让原来元素的指针指向自己
idx ++;//将idx向后挪
void remove(int k){
ne[k] = ne[ne[k]];//让k的指针指向,k下一个人的下一个人,那中间的那位就被挤掉了。
}
int main(){
cin >> n;
init();//初始化
for (int i = 0; i < n; i ++ ) {
char s;
cin >> s;
if (s == 'H') {
int x;
cin >> x;
int_to_head(x);
}
if (s == 'D'){
int k;
cin >> k;
if (k == 0) head = ne[head];//删除头节点
else remove(k - 1);//注意删除第k个输入后面的数,那函数里放的是下标,k要减去1
}
if (s == 'I'){
int k, x;
cin >> k >> x;
add(k - 1, x);//同样的,第k个数,和下标不同,所以要减1
}
}
for (int i = head; i != -1; i = ne[i]) cout << e[i] << ' ' ;
cout << endl;
return 0;
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









