







从网上下载的一些PDF文件,里面添加了特定的背景图像,当文件有很多页的时候,手工删除并不现实。因此,需要用程序将这些图像批量删除。
一、需要依赖的包
MuPDF是一个不错的PDF文件处理库,在Python世界里面,对应的叫做PyMuPDF,它是一个相当给力的工具。它的官方文档如下:
https://pymupdf.readthedocs.io/en/latest/
我们通过pip命令安装它:
pip install --upgrade pymupdf当本地Python环境已经存在该库时,会执行版本更新动作,保持最新版。
二、在代码中引用该包
通过import语句,导入该包:
import fitz
三、查找并删除特定的图片
1. 发现想要删的
通过查阅PyMuPDF的官方文档,我们知道,删除一个PDF里的图像可以通过Page类中的删除图像方法完成(根据文档介绍,这其实是拿一个空白的外参替换原有的,本质上并没有彻底删除,当然肉眼也已经不可见了,但用对象编辑工具可以看到一个透明框框):
delete_image(xref)
又或者再彻底一点,来个“根治”的方法——Document类里的_deleteObject方法(该方法彻底删掉了对应的图像参照对象):
doc._deleteObject(xref)
两个方法的输入参数xref是图像的外部参照ID号,如“622”。那么,我们就可以通过抽取PDF图像列表的方式,获得外部参照xref的ID,例如运行以下程序,可以从PDF中提取对应图像。
import io
import os
import sys
import time
import fitz
print(fitz.__doc__)
if not tuple(map(int, fitz.version[0].split("."))) >= (1, 18, 18):
raise SystemExit("require PyMuPDF v1.18.18+")
dimlimit = 0 # 100 # each image side must be greater than this
relsize = 0 # 0.05 # image : image size ratio must be larger than this (5%)
abssize = 0 # 2048 # absolute image size limit 2 KB: ignore if smaller
imgdir = "output" # found images are stored in this subfolder
if not os.path.exists(imgdir): # make subfolder if necessary
os.mkdir(imgdir)
def recoverpix(doc, item):
xref = item[0] # xref of PDF image
smask = item[1] # xref of its /SMask
# special case: /SMask or /Mask exists
if smask > 0:
pix0 = fitz.Pixmap(doc.extract_image(xref)["image"])
if pix0.alpha: # catch irregular situation
pix0 = fitz.Pixmap(pix0, 0) # remove alpha channel
mask = fitz.Pixmap(doc.extract_image(smask)["image"])
try:
pix = fitz.Pixmap(pix0, mask)
except: # fallback to original base image in case of problems
pix = fitz.Pixmap(doc.extract_image(xref)["image"])
if pix0.n > 3:
ext = "pam"
else:
ext = "png"
return { # create dictionary expected by caller
"ext": ext,
"colorspace": pix.colorspace.n,
"image": pix.tobytes(ext),
}
# special case: /ColorSpace definition exists
# to be sure, we convert these cases to RGB PNG images
if "/ColorSpace" in doc.xref_object(xref, compressed=True):
pix = fitz.Pixmap(doc, xref)
pix = fitz.Pixmap(fitz.csRGB, pix)
return { # create dictionary expected by caller
"ext": "png",
"colorspace": 3,
"image": pix.tobytes("png"),
}
return doc.extract_image(xref)
fname = sys.argv[1] if len(sys.argv) == 2 else None
if not fname:
fname = "your_default_pdf_path"
if not fname:
raise SystemExit()
t0 = time.time()
doc = fitz.open(fname)
page_count = doc.page_count # number of pages
xreflist = []
imglist = []
for pno in range(page_count):
il = doc.get_page_images(pno)
imglist.extend([x[0] for x in il])
for img in il:
xref = img[0]
if xref in xreflist:
continue
width = img[2]
height = img[3]
if min(width, height) <= dimlimit:
continue
image = recoverpix(doc, img)
n = image["colorspace"]
imgdata = image["image"]
if len(imgdata) <= abssize:
continue
if len(imgdata) / (width * height * n) <= relsize:
continue
imgfile = os.path.join(imgdir, "img%06i.%s" % (xref, image["ext"]))
fout = open(imgfile, "wb")
fout.write(imgdata)
fout.close()
xreflist.append(xref)
t1 = time.time()
imglist = list(set(imglist))
print(len(set(imglist)), "images in total")
print(len(xreflist), "images extracted")
print("total time %g sec" % (t1 - t0))代码运行结果如下:
PyMuPDF 1.24.1: Python bindings for the MuPDF 1.24.1 library (rebased implementation).
Python 3.11 running on win32 (64-bit).
12 images in total
12 images extracted
total time 1.93884 sec

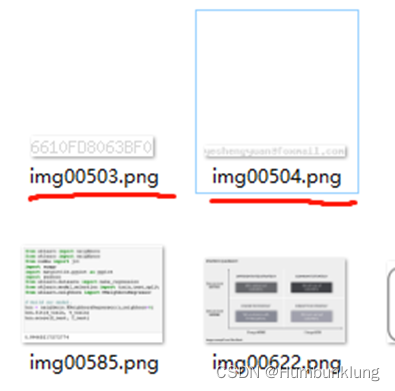
查看输出目录的图像,我需要删除当中ID为503(一串编码)和504(我的邮箱)的外参图像。
2. 删掉想要删的
找到我们想要删除的内容后,操作就变得简单了。我们通过遍历每一个Page,删掉对应的Image即可。
虚假的删除(只是替换):
import fitz, os
doc = fitz.open("your pdf path")
for page in doc:
# delete the specific images
page.delete_image(503)
page.delete_image(504)
# save the document
doc.save('tapmh.pdf')真实的删除(直接撸掉):
import fitz, os
doc = fitz.open("your pdf path")
# remove the xref objects
doc._deleteObject(503)
doc._deleteObject(504)
# save the document
doc.save("tapmh.pdf")删除效果如下:




















 9087
9087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











